A Novel Metric for Measuring the Robustness of Large Language Models in Non-adversarial Scenarios
作者: Samuel Ackerman, Ella Rabinovich, Eitan Farchi, Ateret Anaby-Tavor
分类: cs.CL, stat.AP
发布日期: 2024-08-04 (更新: 2024-11-04)
备注: Published in the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) findings
💡 一句话要点
提出一种新指标,评估大型语言模型在非对抗场景下的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性评估 非对抗场景 语义不变性 自然语言扰动
📋 核心要点
- 现有大型语言模型在面对输入扰动时,其输出的稳定性面临挑战,尤其是在非对抗性的自然扰动下。
- 论文提出了一种新的鲁棒性评估指标,旨在衡量模型在语义保持不变的输入变体下的输出一致性。
- 通过构建包含自然扰动和语义等价释义的数据集,并对多个模型进行评估,验证了所提出指标的有效性。
📝 摘要(中文)
本文评估了多个大型语言模型在多个数据集上的鲁棒性。这里的鲁棒性指的是模型答案对于输入中保持语义不变的变体的相对不敏感性。通过引入自然发生的、非恶意扰动,或者生成输入问题或陈述的语义等价的释义,来构建基准数据集。此外,本文还提出了一种新的指标来评估模型的鲁棒性,并通过在创建的数据集上对多个模型进行实证评估,证明了其在非对抗场景中的优势。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在非对抗场景下的鲁棒性评估问题。现有方法缺乏一种有效的、能够量化模型对语义保持不变的输入扰动不敏感程度的指标。模型在实际应用中,经常会遇到包含自然语言变体的输入,因此评估模型对这些变体的鲁棒性至关重要。
核心思路:论文的核心思路是构建包含语义等价但表达不同的输入样本,并衡量模型在这些样本上的输出一致性。通过比较模型在原始输入和扰动输入上的输出差异,可以量化模型对语义不变性的敏感程度。提出的新指标旨在捕捉这种敏感性,从而评估模型的鲁棒性。
技术框架:论文的技术框架主要包含以下几个阶段:1) 构建数据集:通过引入自然发生的非恶意扰动或生成语义等价的释义来创建数据集。2) 模型评估:使用构建的数据集评估多个大型语言模型。3) 指标计算:使用提出的新指标量化模型的鲁棒性。4) 结果分析:分析不同模型在不同数据集上的鲁棒性表现,并验证指标的有效性。
关键创新:论文的关键创新在于提出了一个新的鲁棒性评估指标,该指标专门设计用于衡量模型在非对抗场景下对语义保持不变的输入扰动的敏感程度。与现有方法相比,该指标更关注自然语言的细微变化,能够更准确地反映模型在实际应用中的鲁棒性。
关键设计:论文的关键设计包括:1) 数据集的构建方法,确保扰动是自然发生的且非恶意的,同时保持语义不变。2) 新指标的定义,需要能够有效捕捉模型输出的细微差异,并将其转化为鲁棒性的量化指标。3) 实验评估方案,需要选择合适的模型和数据集,并设计合理的评估指标,以验证新指标的有效性。
🖼️ 关键图片
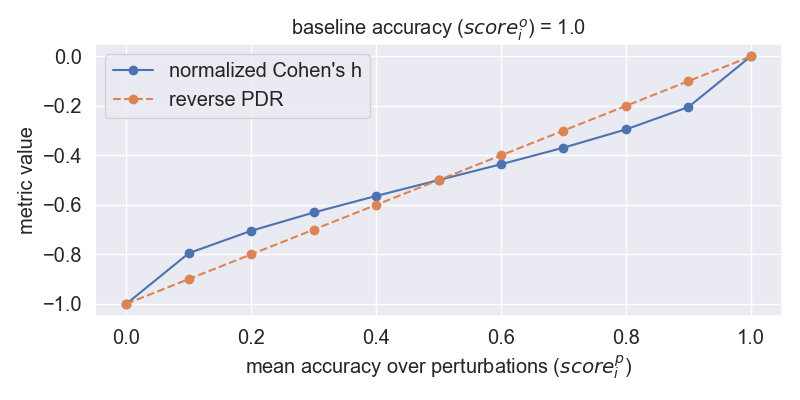


📊 实验亮点
论文通过实验验证了所提出的鲁棒性评估指标的有效性。在构建的包含自然扰动和语义等价释义的数据集上,对多个大型语言模型进行了评估。实验结果表明,该指标能够有效区分不同模型的鲁棒性差异,并与模型的实际表现相符。具体的性能数据和对比基线在论文中进行了详细描述。
🎯 应用场景
该研究成果可应用于提升大型语言模型在实际应用中的可靠性和稳定性。例如,在智能客服、机器翻译、文本摘要等领域,模型需要能够处理各种自然语言表达方式,并保持输出的一致性。通过使用该论文提出的指标评估和优化模型,可以提高模型在这些场景下的性能和用户体验。未来的研究可以进一步探索如何利用该指标来指导模型的训练和微调,从而提高模型的鲁棒性。
📄 摘要(原文)
We evaluate the robustness of several large language models on multiple datasets. Robustness here refers to the relative insensitivity of the model's answers to meaning-preserving variants of their input. Benchmark datasets are constructed by introducing naturally-occurring, non-malicious perturbations, or by generating semantically equivalent paraphrases of input questions or statements. We further propose a novel metric for assessing a model robustness, and demonstrate its benefits in the non-adversarial scenario by empirical evaluation of several models on the created datasets.