Defining and Evaluating Decision and Composite Risk in Language Models Applied to Natural Language Inference
作者: Ke Shen, Mayank Kejriwal
分类: cs.CL, cs.AI
发布日期: 2024-08-04
备注: arXiv admin note: text overlap with arXiv:2310.03283
💡 一句话要点
提出决策与复合风险评估框架,提升LLM在自然语言推理中的置信度校准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自然语言推理 置信度校准 风险评估 决策风险 复合风险 两级推理架构 常识推理
📋 核心要点
- 现有大型语言模型在推理时存在置信度偏差,过度自信和欠自信问题并存,但对欠自信的研究不足。
- 论文提出一种两级推理架构,通过决策规则判断模型是否应该避免推理,从而降低决策风险和复合风险。
- 实验结果表明,该框架能使LLM更自信地处理低风险任务,并有效避免高风险任务的错误回答,提升了置信度校准。
📝 摘要(中文)
大型语言模型(LLM),如ChatGPT,虽然表现出色,但也存在重要的风险。其中一种风险源于模型推理中不恰当的置信度,包括过度自信和欠自信。虽然过度自信已被广泛研究,但对欠自信的研究不足,导致对模型基于置信度偏差的综合风险理解不对称。本文通过定义两种风险(决策风险和复合风险)来解决这种不对称性,并提出了一个实验框架,该框架包含一个两级推理架构和适当的指标,用于测量判别式和生成式LLM中的此类风险。第一级依赖于一个决策规则,该规则决定底层语言模型是否应该避免推理。第二级(如果模型不避免)是模型的推理。在四个自然语言常识推理数据集上使用基于RoBERTa的开源集成模型和ChatGPT进行的详细实验,证明了评估框架的实际效用。例如,我们的结果表明,我们的框架可以使LLM自信地响应额外的20.1%的低风险推理任务,而其他方法可能会将这些任务错误地分类为高风险,并跳过19.8%的高风险任务,否则这些任务会被错误地回答。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在自然语言推理任务中存在的置信度校准问题,具体表现为过度自信和欠自信。现有方法主要关注过度自信,而忽略了欠自信带来的风险,导致对LLM综合风险评估的不完整。这种不平衡会影响LLM在实际应用中的可靠性。
核心思路:论文的核心思路是通过引入一个决策层,让LLM在不确定性较高时选择“拒绝回答”,从而降低因不恰当置信度导致的风险。这种方法旨在提高LLM的整体可靠性,使其在能够给出正确答案时才给出答案,避免因错误答案带来的负面影响。
技术框架:该框架包含两级推理架构。第一级是决策层,使用决策规则判断LLM是否应该避免推理。如果决策层判断LLM可以进行推理,则进入第二级,即LLM的推理过程。整个框架通过定义决策风险和复合风险来评估LLM的性能,并使用相应的指标进行测量。
关键创新:该论文的关键创新在于提出了一个完整的风险评估框架,同时考虑了过度自信和欠自信两种情况,并设计了一个两级推理架构来降低风险。与现有方法相比,该方法更加全面地评估了LLM的可靠性,并提供了一种有效的风险控制手段。
关键设计:决策规则的具体实现方式未知,但可以推测其可能基于LLM的输出概率、注意力权重或其他置信度指标。论文中使用了自然语言常识推理数据集进行实验,并选择了RoBERTa和ChatGPT作为实验对象。具体的损失函数和网络结构细节未在摘要中提及。
🖼️ 关键图片


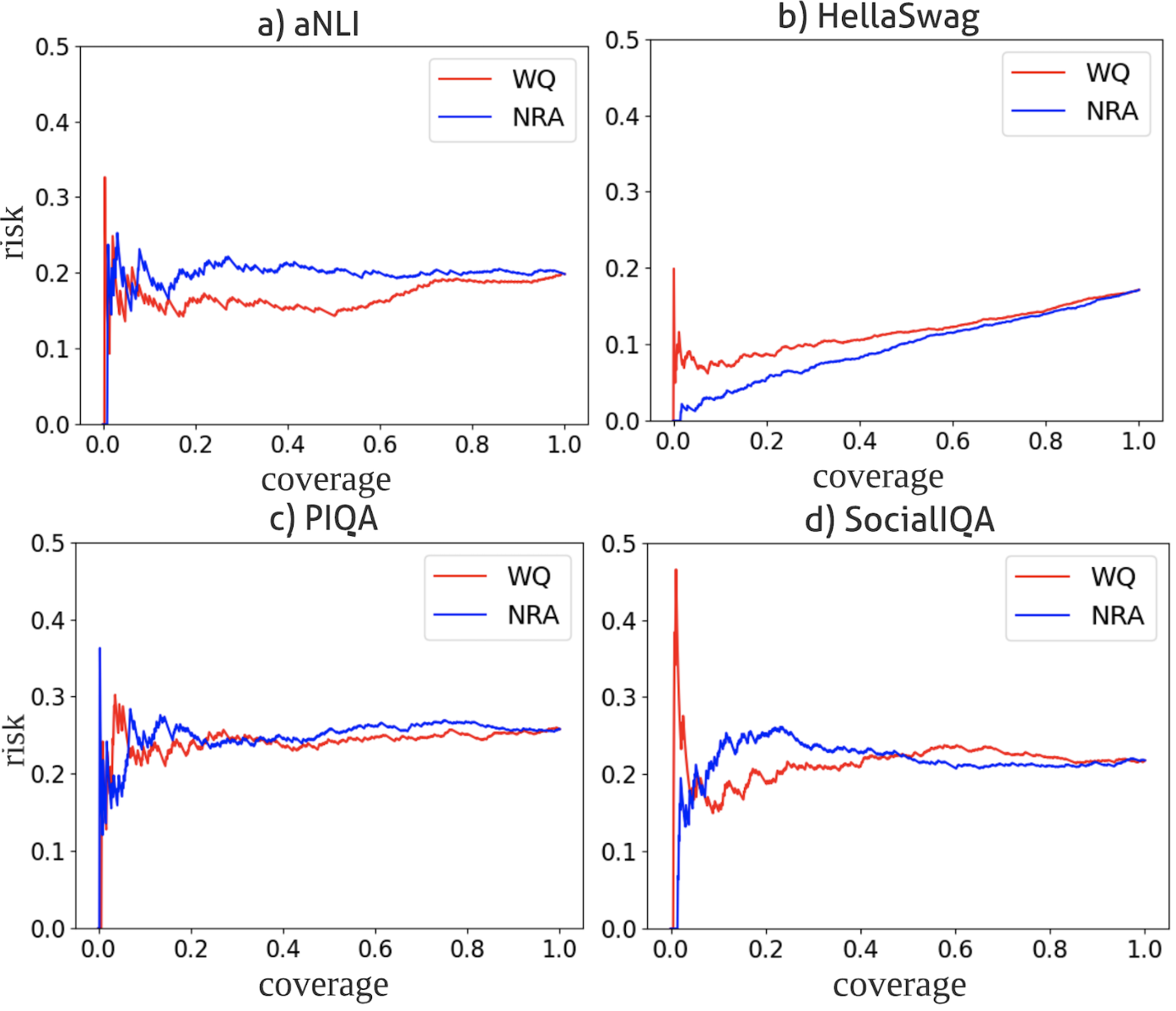
📊 实验亮点
实验结果表明,该框架能够使LLM自信地响应额外的20.1%的低风险推理任务,这些任务原本可能被错误地分类为高风险。同时,该框架还能使LLM跳过19.8%的高风险任务,避免给出错误的答案。这些结果表明,该框架能够有效提高LLM的置信度校准能力,并降低其在实际应用中的风险。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的自然语言处理任务,例如智能客服、医疗诊断辅助、金融风险评估等。通过降低LLM的置信度偏差,可以提高其在这些领域的应用价值,并减少因错误答案带来的潜在风险。未来,该方法可以进一步推广到其他类型的LLM和任务中。
📄 摘要(原文)
Despite their impressive performance, large language models (LLMs) such as ChatGPT are known to pose important risks. One such set of risks arises from misplaced confidence, whether over-confidence or under-confidence, that the models have in their inference. While the former is well studied, the latter is not, leading to an asymmetry in understanding the comprehensive risk of the model based on misplaced confidence. In this paper, we address this asymmetry by defining two types of risk (decision and composite risk), and proposing an experimental framework consisting of a two-level inference architecture and appropriate metrics for measuring such risks in both discriminative and generative LLMs. The first level relies on a decision rule that determines whether the underlying language model should abstain from inference. The second level (which applies if the model does not abstain) is the model's inference. Detailed experiments on four natural language commonsense reasoning datasets using both an open-source ensemble-based RoBERTa model and ChatGPT, demonstrate the practical utility of the evaluation framework. For example, our results show that our framework can get an LLM to confidently respond to an extra 20.1% of low-risk inference tasks that other methods might misclassify as high-risk, and skip 19.8% of high-risk tasks, which would have been answered incorrectly.