Chain of Stance: Stance Detection with Large Language Models
作者: Junxia Ma, Changjiang Wang, Hanwen Xing, Dongming Zhao, Yazhou Zhang
分类: cs.CL, cs.AI
发布日期: 2024-08-03
💡 一句话要点
提出Chain of Stance方法,利用大语言模型提升立场检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立场检测 大型语言模型 提示学习 链式推理 自然语言处理
📋 核心要点
- 现有基于LLM的立场检测方法主要依赖大规模数据集的微调,忽略了LLM本身推理能力的挖掘。
- Chain of Stance (CoS)方法将立场检测分解为一系列中间断言,引导LLM逐步推理并做出最终判断。
- 在SemEval 2016数据集上的实验表明,CoS方法在少样本学习设置下取得了79.84的F1分数,达到SOTA水平。
📝 摘要(中文)
立场检测是自然语言处理中的一项活跃任务,旨在识别文本中作者对特定目标的立场。鉴于大型语言模型(LLM)卓越的语言理解能力和百科全书式的先验知识,如何探索LLM在立场检测中的潜力受到了广泛关注。与现有仅关注使用大规模数据集进行微调的基于LLM的方法不同,我们提出了一种新的提示方法,称为“Chain of Stance”(CoS)。具体而言,它通过将立场检测过程分解为一系列中间的、与立场相关的断言,最终得出最终判断,从而将LLM定位为专业的立场检测器。这种方法显著提高了分类性能。我们使用四个SOTA LLM在SemEval 2016数据集上进行了广泛的实验,涵盖了零样本和少样本学习设置。结果表明,所提出的方法在少样本设置中实现了最先进的结果,F1得分为79.84。
🔬 方法详解
问题定义:论文旨在解决立场检测问题,即判断文本作者对特定目标的态度(支持、反对或中立)。现有基于LLM的方法主要依赖于大规模数据集的微调,这种方法忽略了LLM本身所具备的知识和推理能力,并且微调需要大量的标注数据,成本较高。
核心思路:论文的核心思路是将立场检测任务分解为一系列中间推理步骤,类似于人类专家进行立场判断时的思考过程。通过引导LLM逐步进行与立场相关的断言,最终得出对目标立场的判断。这种“链式思考”的方式能够更好地利用LLM的先验知识和推理能力。
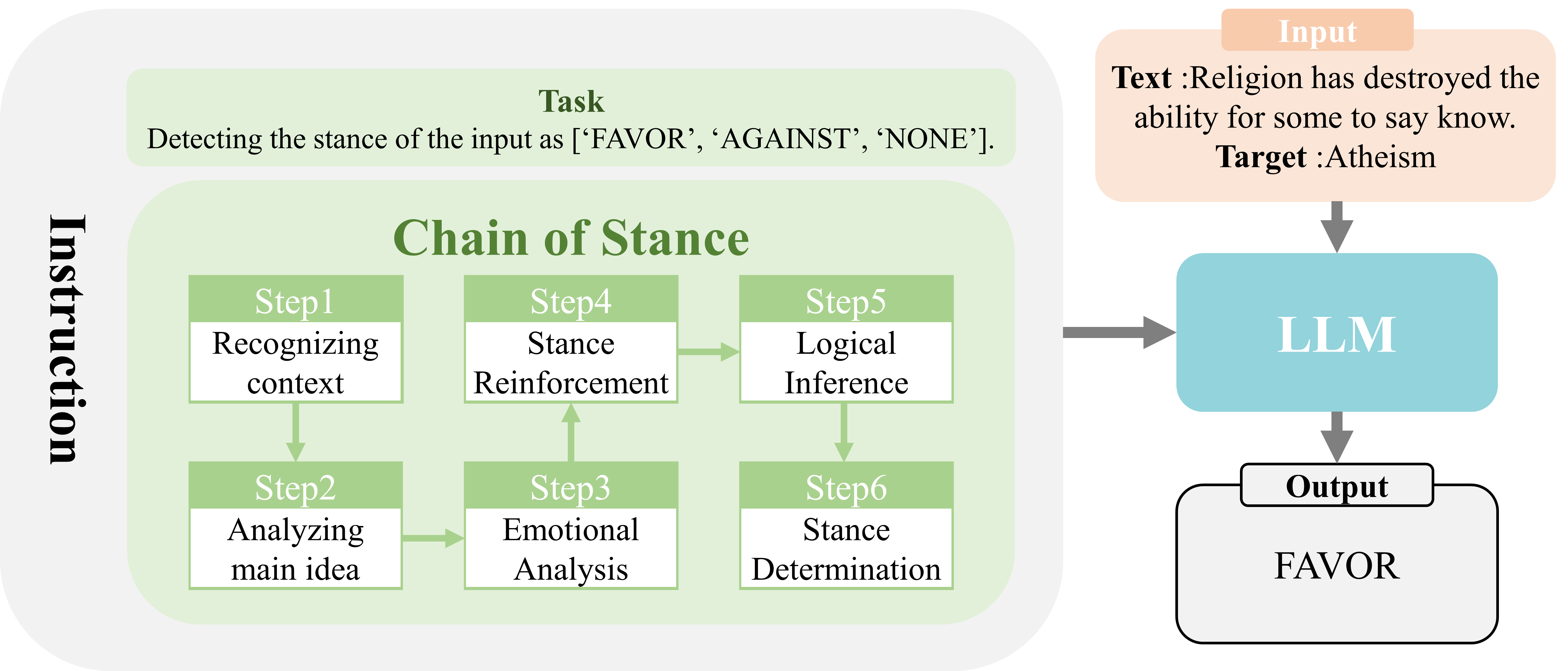
技术框架:Chain of Stance (CoS) 方法主要包含以下几个阶段:1) 问题分解:将立场检测问题分解为一系列与立场相关的中间问题,例如“作者是否认为目标X是好的?”、“作者是否认为目标X是有效的?”等。2) LLM推理:使用LLM对每个中间问题进行推理,生成相应的答案。3) 立场聚合:根据LLM对所有中间问题的答案,综合判断作者对目标的最终立场。
关键创新:CoS方法的关键创新在于其提示策略,它不是直接要求LLM给出立场判断,而是通过一系列中间问题引导LLM进行逐步推理。这种方法能够更好地利用LLM的知识和推理能力,并且不需要大量的标注数据进行微调。与现有方法相比,CoS方法更侧重于利用LLM的内在能力,而不是依赖外部数据。
关键设计:CoS方法的关键设计在于中间问题的选择。这些问题需要与立场判断密切相关,并且能够引导LLM进行有效的推理。论文中并没有明确说明如何自动生成这些中间问题,这可能需要人工设计或者使用其他技术(例如知识图谱)来辅助生成。此外,如何有效地聚合LLM对中间问题的答案也是一个重要的设计考虑,论文中可能使用了简单的投票或者加权平均等方法。
🖼️ 关键图片

📊 实验亮点
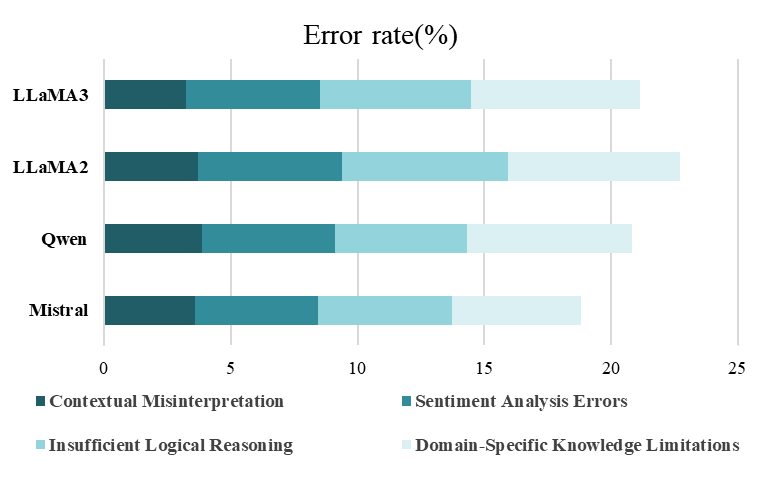
实验结果表明,提出的Chain of Stance方法在SemEval 2016数据集上取得了显著的性能提升。在少样本学习设置下,CoS方法达到了79.84的F1分数,超过了现有的SOTA方法。这表明CoS方法能够有效地利用LLM的知识和推理能力,并且在数据稀缺的情况下也能取得良好的性能。
🎯 应用场景
该研究成果可应用于舆情分析、新闻评论挖掘、社交媒体监控等领域。通过准确识别用户对特定事件或目标的立场,可以帮助政府、企业和个人更好地了解社会舆论,及时发现潜在风险,并做出相应的决策。未来,该方法还可以扩展到其他自然语言处理任务中,例如情感分析、观点挖掘等。
📄 摘要(原文)
Stance detection is an active task in natural language processing (NLP) that aims to identify the author's stance towards a particular target within a text. Given the remarkable language understanding capabilities and encyclopedic prior knowledge of large language models (LLMs), how to explore the potential of LLMs in stance detection has received significant attention. Unlike existing LLM-based approaches that focus solely on fine-tuning with large-scale datasets, we propose a new prompting method, called \textit{Chain of Stance} (CoS). In particular, it positions LLMs as expert stance detectors by decomposing the stance detection process into a series of intermediate, stance-related assertions that culminate in the final judgment. This approach leads to significant improvements in classification performance. We conducted extensive experiments using four SOTA LLMs on the SemEval 2016 dataset, covering the zero-shot and few-shot learning setups. The results indicate that the proposed method achieves state-of-the-art results with an F1 score of 79.84 in the few-shot setting.