Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval
作者: Yanfei Chen, Jinsung Yoon, Devendra Singh Sachan, Qingze Wang, Vincent Cohen-Addad, Mohammadhossein Bateni, Chen-Yu Lee, Tomas Pfister
分类: cs.CL
发布日期: 2024-08-03 (更新: 2024-09-20)
备注: EMNLP Findings 2024
💡 一句话要点
Re-Invoke:一种用于零样本工具检索的工具调用重写方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具检索 大型语言模型 零样本学习 无监督学习 意图识别
📋 核心要点
- 现有方法难以在大规模工具集中有效检索相关工具,阻碍了LLM自主Agent的可靠工具利用。
- Re-Invoke通过生成多样化合成查询、提取用户查询意图和多视角相似性排序来解决工具检索问题。
- 实验表明,Re-Invoke在ToolE数据集上,单工具检索nDCG@5提升20%,多工具检索提升39%。
📝 摘要(中文)
随着大型语言模型(LLMs)的进步,自主Agent能够利用各种工具进行复杂的推理和完成任务。然而,随着工具集规模的增长,如何有效地识别与给定任务最相关的工具成为一个关键瓶颈,阻碍了可靠的工具利用。为了解决这个问题,我们提出了一种名为Re-Invoke的无监督工具检索方法,该方法旨在有效地扩展到大型工具集而无需训练。具体来说,我们首先生成一组多样化的合成查询,这些查询全面覆盖了工具索引阶段与每个工具文档相关的查询空间的不同方面。其次,我们利用LLM的查询理解能力,从推理阶段的用户查询中提取关键的工具相关上下文和潜在意图。最后,我们采用一种基于意图的新型多视角相似性排序策略,以精确定位每个查询最相关的工具。我们的评估表明,Re-Invoke在单工具和多工具场景中均显著优于最先进的替代方案,所有这些都在完全无监督的环境中进行。值得注意的是,在ToolE数据集上,我们在单工具检索的nDCG@5上实现了20%的相对改进,在多工具检索上实现了39%的改进。
🔬 方法详解
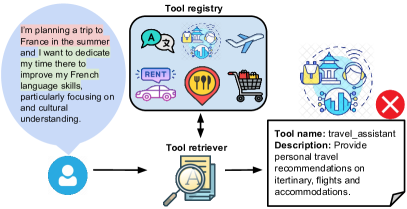
问题定义:论文旨在解决大型语言模型(LLMs)驱动的自主Agent在面对大规模工具集时,如何准确高效地检索到最相关的工具的问题。现有方法在工具集规模增大时,检索效率和准确率显著下降,成为制约Agent能力提升的关键瓶颈。这些方法通常依赖于有监督训练或简单的文本匹配,难以泛化到未见过的工具或复杂的用户意图。
核心思路:Re-Invoke的核心思路是通过“重写”工具调用过程,将工具检索问题转化为一个更易于处理的相似度匹配问题。具体来说,它通过生成多样化的合成查询来扩展工具的表示,并利用LLM理解用户查询的深层意图,从而实现更准确的工具检索。这种方法的核心在于弥合了用户查询和工具描述之间的语义鸿沟。
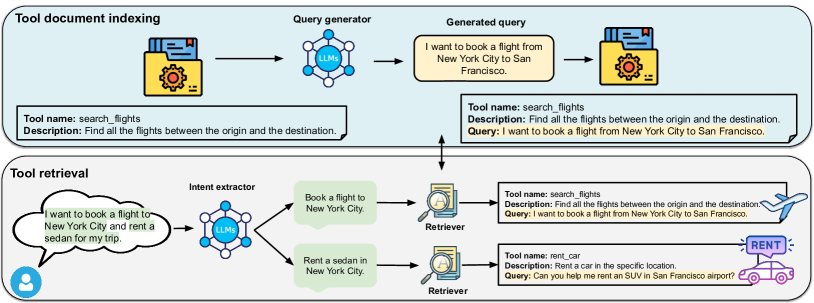
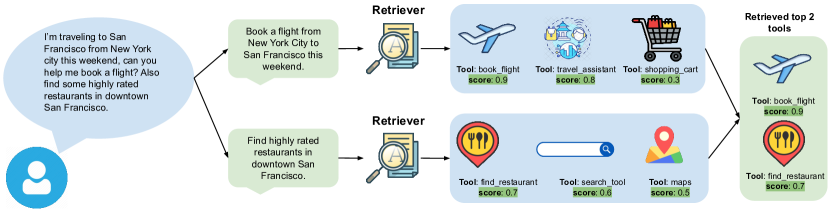
技术框架:Re-Invoke主要包含三个阶段:工具索引阶段、查询理解阶段和相似性排序阶段。在工具索引阶段,为每个工具生成一组多样化的合成查询,以覆盖其功能和使用场景。在查询理解阶段,利用LLM从用户查询中提取关键的工具相关上下文和潜在意图。在相似性排序阶段,采用一种基于意图的多视角相似性排序策略,计算用户查询和工具之间的相似度,并返回最相关的工具。
关键创新:Re-Invoke的关键创新在于其无监督的工具检索方法,该方法无需任何训练数据即可有效扩展到大型工具集。此外,它还创新性地利用LLM的查询理解能力来提取用户查询的深层意图,并采用多视角相似性排序策略来提高检索准确率。与现有方法相比,Re-Invoke更加灵活、高效,且具有更强的泛化能力。
关键设计:Re-Invoke的关键设计包括:1) 合成查询生成策略,用于生成多样化的、覆盖工具不同方面的查询;2) 基于LLM的意图提取模块,用于从用户查询中提取关键的工具相关上下文和潜在意图;3) 多视角相似性排序策略,用于综合考虑用户查询和工具之间的多种相似性,并返回最相关的工具。具体的参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
Re-Invoke在ToolE数据集上取得了显著的性能提升。在单工具检索任务中,nDCG@5指标相对提升了20%;在多工具检索任务中,nDCG@5指标相对提升了39%。这些结果表明,Re-Invoke在无监督工具检索方面具有显著的优势,能够有效地提高工具检索的准确率和效率。
🎯 应用场景
Re-Invoke具有广泛的应用前景,可用于各种需要工具检索的场景,例如智能助手、自动化流程、软件开发等。它可以帮助用户更快速、更准确地找到所需的工具,提高工作效率和用户体验。未来,Re-Invoke可以进一步扩展到支持更复杂的工具和更广泛的应用领域,例如机器人控制、智能家居等。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled autonomous agents with complex reasoning and task-fulfillment capabilities using a wide range of tools. However, effectively identifying the most relevant tools for a given task becomes a key bottleneck as the toolset size grows, hindering reliable tool utilization. To address this, we introduce Re-Invoke, an unsupervised tool retrieval method designed to scale effectively to large toolsets without training. Specifically, we first generate a diverse set of synthetic queries that comprehensively cover different aspects of the query space associated with each tool document during the tool indexing phase. Second, we leverage LLM's query understanding capabilities to extract key tool-related context and underlying intents from user queries during the inference phase. Finally, we employ a novel multi-view similarity ranking strategy based on intents to pinpoint the most relevant tools for each query. Our evaluation demonstrates that Re-Invoke significantly outperforms state-of-the-art alternatives in both single-tool and multi-tool scenarios, all within a fully unsupervised setting. Notably, on the ToolE datasets, we achieve a 20% relative improvement in nDCG@5 for single-tool retrieval and a 39% improvement for multi-tool retrieval.