Evaluating the Impact of Advanced LLM Techniques on AI-Lecture Tutors for a Robotics Course
作者: Sebastian Kahl, Felix Löffler, Martin Maciol, Fabian Ridder, Marius Schmitz, Jennifer Spanagel, Jens Wienkamp, Christopher Burgahn, Malte Schilling
分类: cs.CL, cs.AI, cs.CY, cs.RO
发布日期: 2024-08-02
备注: The article is an extended version of a paper presented at the International Workshop on AI in Education and Educational Research (AIEER) at ECAI-2024 (27th European Conference on Artificial Intelligence)
💡 一句话要点
评估LLM技术在机器人课程AI辅导中的应用效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 检索增强生成 提示工程 AI辅导 机器人教育
📋 核心要点
- 现有AI辅导系统在知识获取和响应生成方面存在不足,难以提供高质量的个性化教学。
- 利用提示工程、RAG和微调等技术,优化LLM在机器人课程辅导中的表现,提升知识准确性和响应质量。
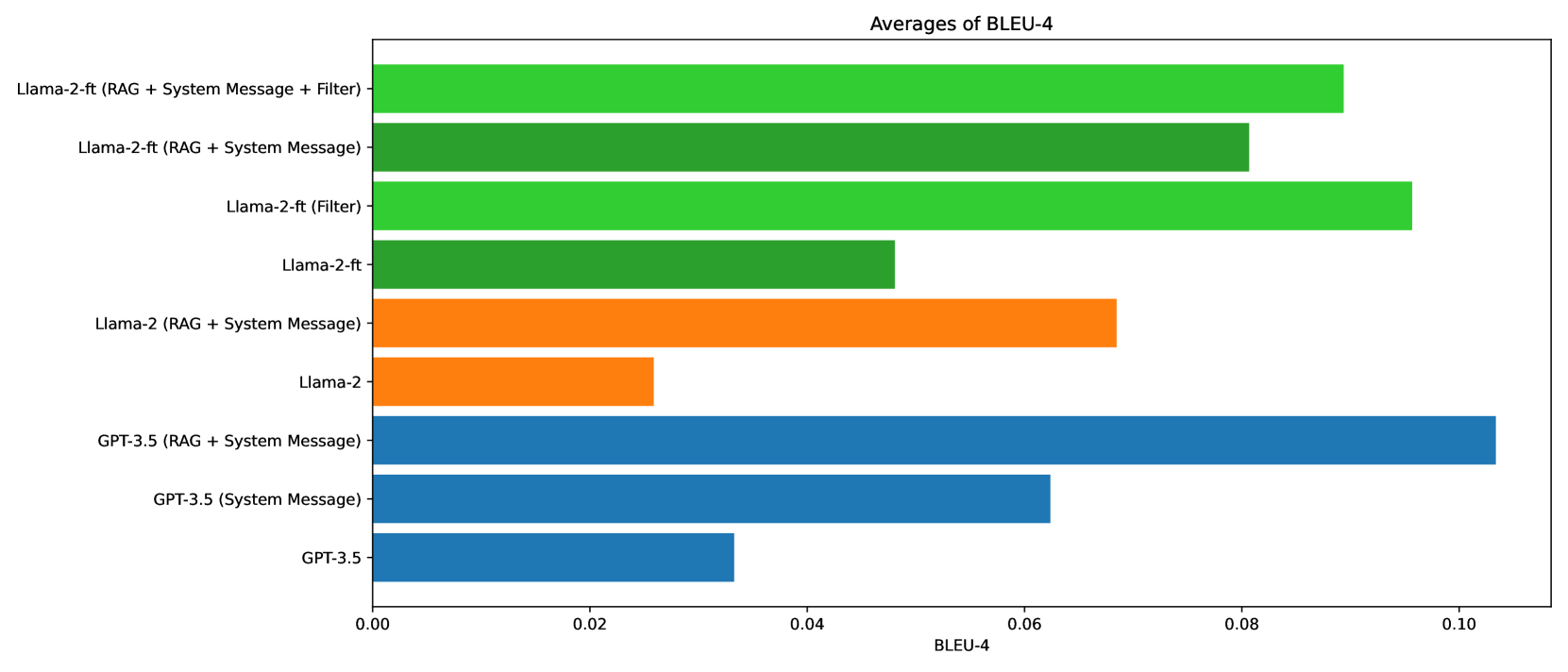
- 实验表明,RAG结合提示工程显著提升模型响应质量和事实准确性,但微调存在过拟合风险。
📝 摘要(中文)
本研究评估了大型语言模型(LLM)作为大学课程中基于人工智能的辅导员的性能。特别地,研究利用了不同的先进技术,例如提示工程、检索增强生成(RAG)和微调。我们使用常见的相似性指标(如BLEU-4、ROUGE和BERTScore)评估了不同的模型和应用的技术,并辅以对有用性和可信度的小型人工评估。我们的研究结果表明,RAG与提示工程相结合可以显著增强模型响应,并产生更好的事实性答案。在教育背景下,RAG似乎是一种理想的技术,因为它基于使用通常已存在于大学课程中的附加信息和材料来丰富模型的输入。另一方面,微调可以产生相当小但仍然强大的专家模型,但存在过度拟合的风险。我们的研究进一步探讨了如何衡量LLM的性能,以及当前的衡量标准在多大程度上代表了正确性或相关性?我们发现相似性指标之间存在高度相关性,并且大多数这些指标都偏向于较短的响应。总的来说,我们的研究指出了将LLM集成到教育环境中的潜力和挑战,表明需要平衡的训练方法和先进的评估框架。
🔬 方法详解
问题定义:论文旨在解决如何有效利用大型语言模型(LLM)作为机器人课程的AI辅导员的问题。现有方法可能存在知识覆盖不全、回答不够准确、无法根据学生具体问题进行个性化指导等痛点。此外,如何客观评价LLM在教育场景下的性能也是一个挑战。
核心思路:论文的核心思路是探索不同的LLM增强技术,包括提示工程、检索增强生成(RAG)和微调,并评估它们在机器人课程辅导中的效果。通过比较不同技术的优缺点,找到最适合教育场景的LLM应用方案。同时,研究还关注如何使用合适的指标来衡量LLM的性能,并探讨现有指标的局限性。
技术框架:整体框架包括以下几个主要步骤:1) 选择合适的LLM作为基础模型;2) 应用不同的增强技术,包括提示工程(优化输入提示)、RAG(从课程资料中检索相关信息)和微调(使用课程数据训练模型);3) 使用BLEU-4、ROUGE和BERTScore等相似性指标以及人工评估来评估模型的性能;4) 分析实验结果,比较不同技术的优缺点,并探讨如何改进LLM在教育场景中的应用。
关键创新:论文的关键创新在于系统性地评估了多种LLM增强技术在机器人课程辅导中的效果,并指出了RAG在教育场景中的优势。此外,论文还探讨了如何使用合适的指标来衡量LLM的性能,并指出了现有指标的局限性。
关键设计:在RAG方面,关键设计在于如何构建高质量的课程资料索引,以及如何设计有效的检索策略,以便从索引中检索到与学生问题最相关的信息。在微调方面,关键设计在于如何选择合适的训练数据和超参数,以避免过拟合。在评估方面,关键设计在于如何结合自动评估指标和人工评估,以全面评估模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RAG与提示工程相结合可以显著增强模型响应,并产生更好的事实性答案。相似性指标之间存在高度相关性,但大多数指标都偏向于较短的响应。研究还发现,微调虽然可以产生较小的专家模型,但也存在过拟合的风险。人工评估结果与自动评估指标具有一定的相关性,但人工评估更能体现模型的有用性和可信度。
🎯 应用场景
该研究成果可应用于在线教育平台、智能辅导系统等领域,为学生提供个性化的学习支持。通过集成LLM技术,可以显著提升教学效率和学习效果,尤其是在机器人、编程等需要大量实践和问题解决的学科中。未来,该技术有望实现更智能化的教学模式,例如根据学生的学习进度和掌握程度动态调整教学内容。
📄 摘要(原文)
This study evaluates the performance of Large Language Models (LLMs) as an Artificial Intelligence-based tutor for a university course. In particular, different advanced techniques are utilized, such as prompt engineering, Retrieval-Augmented-Generation (RAG), and fine-tuning. We assessed the different models and applied techniques using common similarity metrics like BLEU-4, ROUGE, and BERTScore, complemented by a small human evaluation of helpfulness and trustworthiness. Our findings indicate that RAG combined with prompt engineering significantly enhances model responses and produces better factual answers. In the context of education, RAG appears as an ideal technique as it is based on enriching the input of the model with additional information and material which usually is already present for a university course. Fine-tuning, on the other hand, can produce quite small, still strong expert models, but poses the danger of overfitting. Our study further asks how we measure performance of LLMs and how well current measurements represent correctness or relevance? We find high correlation on similarity metrics and a bias of most of these metrics towards shorter responses. Overall, our research points to both the potential and challenges of integrating LLMs in educational settings, suggesting a need for balanced training approaches and advanced evaluation frameworks.