Misinforming LLMs: vulnerabilities, challenges and opportunities
作者: Bo Zhou, Daniel Geißler, Paul Lukowicz
分类: cs.CL, cs.AI
发布日期: 2024-08-02
💡 一句话要点
揭示大型语言模型脆弱性:信息误导漏洞、挑战与机遇
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息误导 脆弱性分析 可信AI 知识库 逻辑推理 自然语言处理 Transformer模型
📋 核心要点
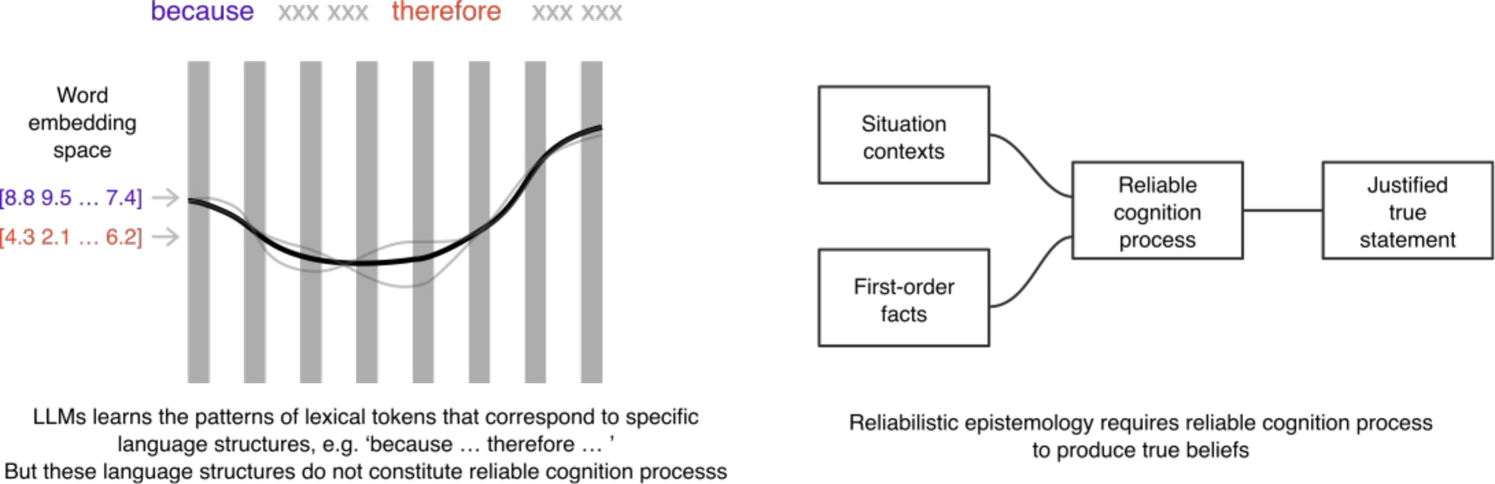
- 现有LLM依赖词嵌入统计模式,缺乏真正的认知能力,易受信息误导,产生“幻觉”现象。
- 论文提出结合生成式Transformer模型与事实库、逻辑编程语言,构建可信、可解释的LLM。
- 研究展望了未来LLM的发展方向,强调了结合事实依据和逻辑推理的重要性,以提升LLM的可靠性。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理领域取得了显著进展,但其底层机制常常被误解。尽管LLMs表现出连贯的回答和明显的推理行为,但它们依赖于词嵌入中的统计模式,而非真正的认知过程。这导致了诸如“幻觉”和信息误导等漏洞。本文认为,由于当前LLM架构依赖于词嵌入向量序列模式的相关性,因此本质上是不可信的。然而,将生成式Transformer模型与事实库和逻辑编程语言相结合的持续研究,可能会导致开发出可信的LLM,这些LLM能够基于给定的事实生成陈述,并解释其自我推理过程。
🔬 方法详解
问题定义:论文旨在探讨大型语言模型(LLMs)中存在的脆弱性,特别是容易被误导和产生不实信息的问题。现有LLM虽然在自然语言处理任务中表现出色,但其依赖于词嵌入的统计模式,缺乏真正的认知和推理能力。这种机制使得LLM容易受到恶意信息的攻击,产生“幻觉”现象,输出与事实不符的内容,严重影响了LLM的可靠性和可信度。
核心思路:论文的核心思路是,通过将生成式Transformer模型与外部的事实库和逻辑编程语言相结合,来增强LLM的知识储备和推理能力。这种方法旨在弥补LLM在认知和推理方面的不足,使其能够基于给定的事实生成陈述,并解释其推理过程,从而提高LLM的可靠性和可信度。
技术框架:论文并未提出一个完整的技术框架,而是提出了一个研究方向。未来的技术框架可能包含以下几个主要模块:1) 生成式Transformer模型:负责生成自然语言文本;2) 事实库:存储大量的结构化知识,为LLM提供事实依据;3) 逻辑编程语言:用于进行逻辑推理,帮助LLM验证信息的真伪;4) 融合模块:将Transformer模型的输出与事实库和逻辑编程语言的结果进行融合,生成最终的输出。
关键创新:论文的关键创新在于提出了一个构建可信LLM的新思路,即结合生成式模型与外部知识库和推理引擎。与现有方法相比,该思路不再仅仅依赖于大规模语料库的统计模式,而是引入了事实依据和逻辑推理,从而提高了LLM的可靠性和可解释性。
关键设计:论文并未涉及具体的参数设置、损失函数或网络结构等技术细节。未来的研究需要针对具体的任务和数据集,设计合适的参数设置、损失函数和网络结构,以实现最佳的性能。
🖼️ 关键图片

📊 实验亮点
该论文的核心亮点在于指出了当前大型语言模型在信息处理上的脆弱性,并提出了通过结合外部知识库和逻辑推理来增强模型可靠性的潜在解决方案。虽然没有提供具体的实验结果,但其提出的方向为未来LLM的研究提供了重要的指导意义,强调了可信性和可解释性在LLM发展中的重要性。
🎯 应用场景
该研究成果可应用于需要高度可靠性和可信度的自然语言处理任务中,例如智能客服、医疗诊断、金融分析等领域。通过构建可信的LLM,可以减少错误信息的传播,提高决策的准确性,并增强用户对人工智能系统的信任。未来,该研究还有助于开发更安全、更可靠的人工智能系统,为社会带来更大的价值。
📄 摘要(原文)
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as "hallucination" and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.