Task Prompt Vectors: Effective Initialization through Multi-Task Soft-Prompt Transfer
作者: Robert Belanec, Simon Ostermann, Ivan Srba, Maria Bielikova
分类: cs.CL
发布日期: 2024-08-02 (更新: 2025-07-03)
💡 一句话要点
提出任务提示向量,通过多任务软提示迁移实现高效初始化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务提示向量 软提示 多任务学习 Prompt Tuning 知识迁移
📋 核心要点
- 现有软提示方法在新增任务时需重复训练,缺乏多任务模块化能力。
- 提出任务提示向量,通过计算调整后软提示与初始化的差异来实现任务迁移。
- 实验表明,任务提示向量在低资源场景下能有效初始化prompt tuning,且与模型架构无关。
📝 摘要(中文)
Prompt Tuning是训练大型语言模型(LLMs)的一种有效方法。然而,目前基于软提示的方法通常会牺牲多任务模块化,需要为每个新添加的任务完全或部分重复训练过程。虽然最近关于任务向量的工作将算术运算应用于完整的模型权重以实现所需的多任务性能,但软提示的类似方法仍然缺失。为此,我们引入了任务提示向量,它是通过调整后的软提示的权重与其随机初始化之间的元素差异创建的。在12个NLU数据集上的实验结果表明,任务提示向量可用于低资源设置中,以有效地初始化类似任务上的prompt tuning。此外,我们表明任务提示向量独立于两种不同语言模型架构上prompt tuning的随机初始化。这允许使用来自不同任务的预训练向量进行提示算术。通过多个任务的任务提示向量的算术加法,我们提供了一种与最先进基线相比具有竞争力的替代方案。
🔬 方法详解
问题定义:论文旨在解决软提示方法在多任务学习中效率低下的问题。现有方法在新增任务时需要重新训练或微调整个模型,计算成本高昂,且缺乏任务间的知识迁移能力。特别是在低资源场景下,从头开始训练prompt tuning效果不佳。
核心思路:论文的核心思路是利用任务提示向量(Task Prompt Vectors)来捕捉任务的特定信息,并通过向量运算实现任务间的知识迁移。任务提示向量代表了从随机初始化到任务特定prompt tuning的权重变化,可以看作是任务的“特征向量”。通过对这些向量进行算术运算,可以实现不同任务信息的组合,从而加速新任务的prompt tuning过程。
技术框架:该方法主要包含以下几个阶段:1) 对多个源任务分别进行prompt tuning,得到调整后的软提示权重。2) 计算每个源任务的任务提示向量,即调整后的软提示权重与随机初始化权重之间的差值。3) 对于新的目标任务,使用源任务的任务提示向量进行初始化。具体来说,可以将多个源任务的提示向量进行加权求和,然后加到目标任务的随机初始化prompt上,作为目标任务prompt tuning的初始值。4) 在目标任务上进行prompt tuning,进一步优化prompt。
关键创新:该方法最重要的创新点在于提出了任务提示向量的概念,并证明了其在多任务学习中的有效性。与直接对模型权重进行操作的方法相比,任务提示向量更加轻量级,易于操作和存储。此外,论文还证明了任务提示向量与模型架构的独立性,这意味着可以在不同的语言模型之间进行任务迁移。
关键设计:关键设计包括:1) 任务提示向量的计算方式,即调整后的软提示权重与随机初始化权重之间的差值。2) 任务提示向量的加权求和方式,可以根据任务之间的相似度进行加权。3) 目标任务prompt tuning的优化算法和超参数设置。论文中使用了标准的Adam优化器,并对学习率等超参数进行了调整。
🖼️ 关键图片

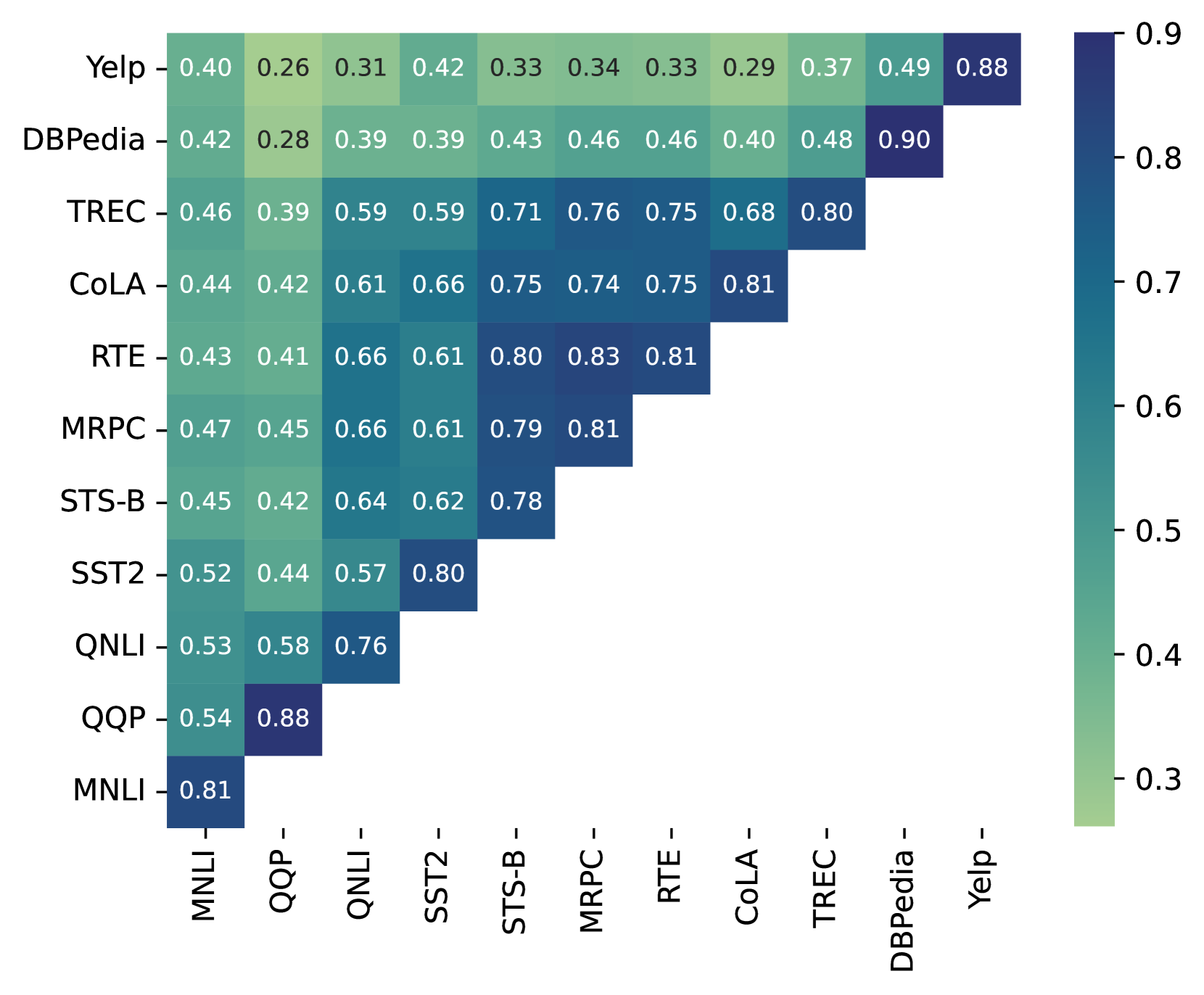
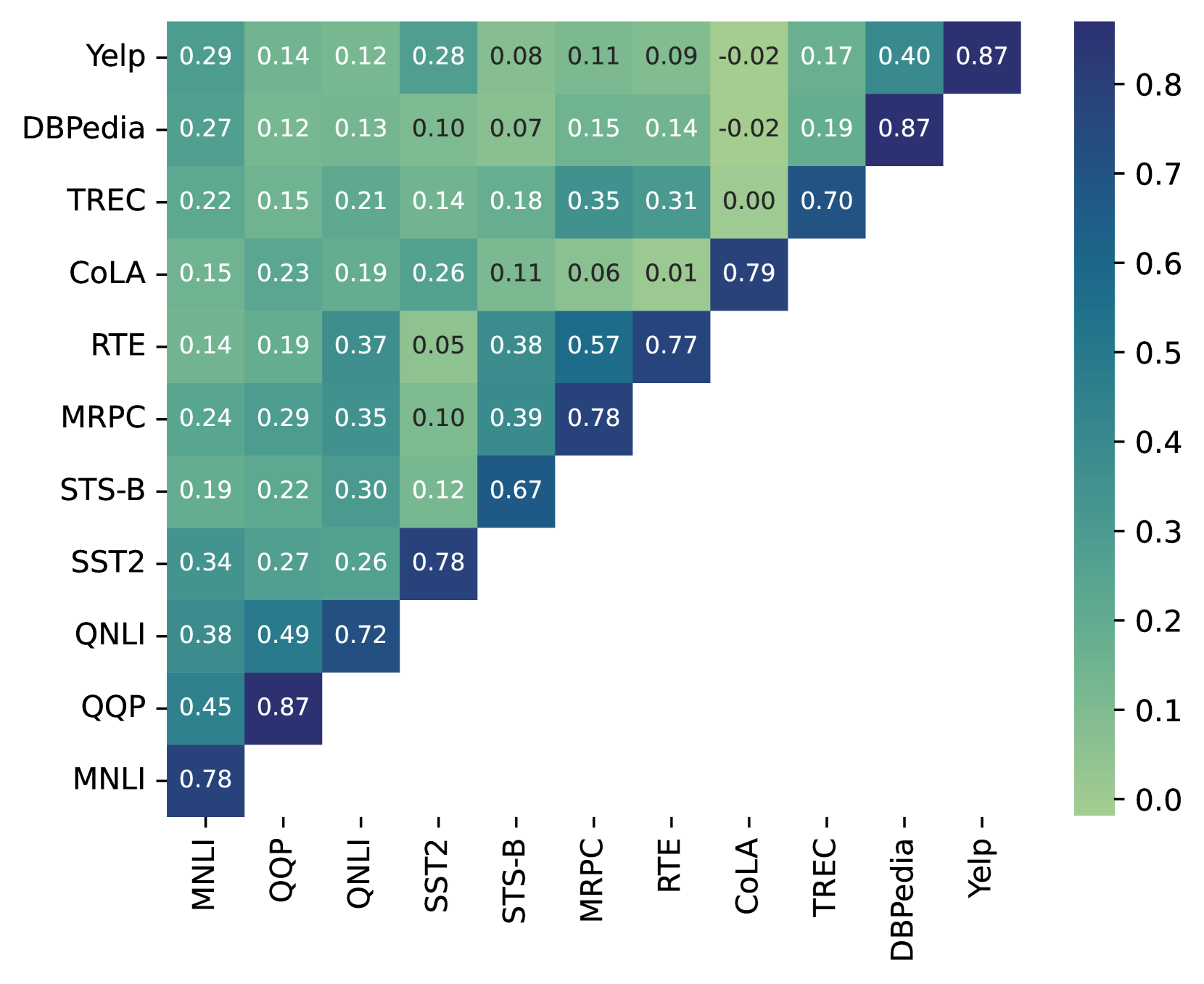
📊 实验亮点
实验结果表明,任务提示向量在12个NLU数据集上表现出色,尤其是在低资源场景下,能够有效地初始化prompt tuning。通过算术加法组合多个任务的提示向量,性能优于state-of-the-art基线方法。此外,实验还验证了任务提示向量与模型架构的独立性,证明了其跨模型迁移能力。
🎯 应用场景
该研究成果可应用于自然语言理解、文本分类、情感分析等领域。在实际应用中,可以利用已有的任务提示向量,快速适应新的任务,尤其是在数据资源有限的情况下,能够显著提升模型的性能和泛化能力。未来,该方法有望扩展到更多模态的任务中,例如图像分类、语音识别等。
📄 摘要(原文)
Prompt tuning is an efficient solution for training large language models (LLMs). However, current soft-prompt-based methods often sacrifice multi-task modularity, requiring the training process to be fully or partially repeated for each newly added task. While recent work on task vectors applied arithmetic operations on full model weights to achieve the desired multi-task performance, a similar approach for soft-prompts is still missing. To this end, we introduce Task Prompt Vectors, created by element-wise difference between weights of tuned soft-prompts and their random initialization. Experimental results on 12 NLU datasets show that task prompt vectors can be used in low-resource settings to effectively initialize prompt tuning on similar tasks. In addition, we show that task prompt vectors are independent of the random initialization of prompt tuning on 2 different language model architectures. This allows prompt arithmetics with the pre-trained vectors from different tasks. In this way, we provide a competitive alternative to state-of-the-art baselines by arithmetic addition of task prompt vectors from multiple tasks.