Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding
作者: Bin Xiao, Lujun Gui, Lei Su, Weipeng Chen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-01
💡 一句话要点
Clover-2:高精度回归轻量级推测解码,提升大语言模型推理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 轻量级推测解码 大语言模型加速 RNN草稿模型 知识蒸馏 模型推理优化
📋 核心要点
- 现有大语言模型自回归解码效率低,与GPU架构不匹配,成为性能瓶颈。
- Clover-2通过改进RNN草稿模型,并结合知识蒸馏,在保证计算效率的同时提升预测精度。
- 实验表明,Clover-2在Vicuna 7B和LLaMA3-Instruct 8B模型上超越现有方法,具有良好的泛化性。
📝 摘要(中文)
大型语言模型(LLMs)常因自回归解码的需求与现代GPU架构的不匹配而效率低下。回归轻量级推测解码因其在文本生成任务中显著的效率提升而备受关注。该方法利用轻量级回归草稿模型(如循环神经网络RNN或单层Transformer解码器),通过序列信息迭代预测潜在的tokens。RNN草稿模型计算经济,但精度较低,而注意力解码器层模型则相反。本文提出了Clover-2,它是Clover的改进版本,Clover是一个基于RNN的草稿模型,旨在实现与注意力解码器层模型相当的精度,同时保持最小的计算开销。Clover-2增强了模型架构并结合了知识蒸馏,以提高Clover的精度并提升整体效率。我们使用开源的Vicuna 7B和LLaMA3-Instruct 8B模型进行了实验。结果表明,Clover-2在各种模型架构中均优于现有方法,展示了其有效性和鲁棒性。
🔬 方法详解
问题定义:大语言模型的自回归解码过程计算量大,效率低,严重制约了模型的推理速度。现有的轻量级推测解码方法,如基于RNN的草稿模型,虽然计算效率高,但预测精度不足,导致推测解码的接受率低,无法充分发挥加速效果。
核心思路:Clover-2的核心思路是在保持RNN草稿模型计算效率优势的前提下,通过改进模型结构和引入知识蒸馏技术,显著提升草稿模型的预测精度,从而提高推测解码的整体效率。这样既能降低计算开销,又能保证较高的推测准确率。
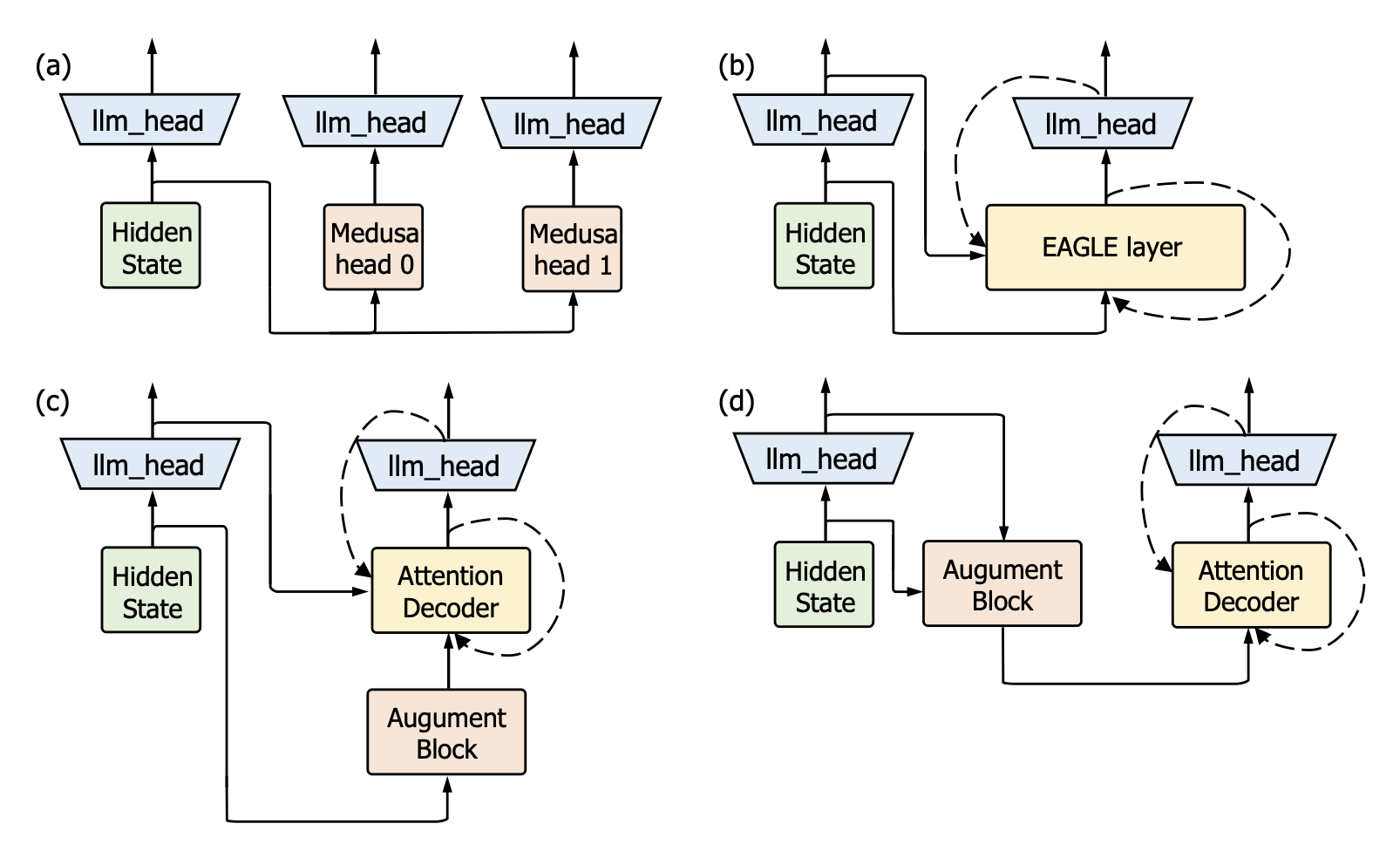
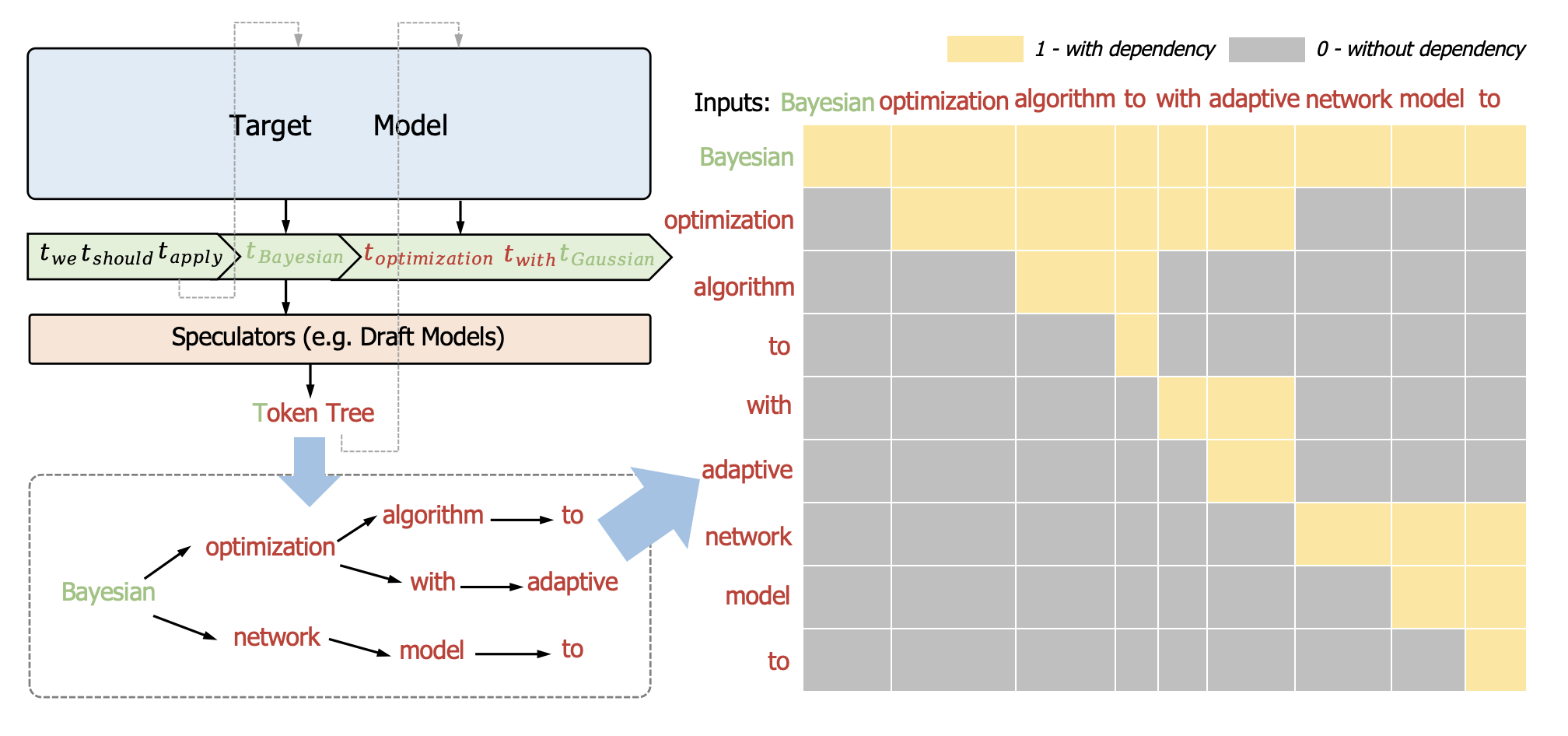
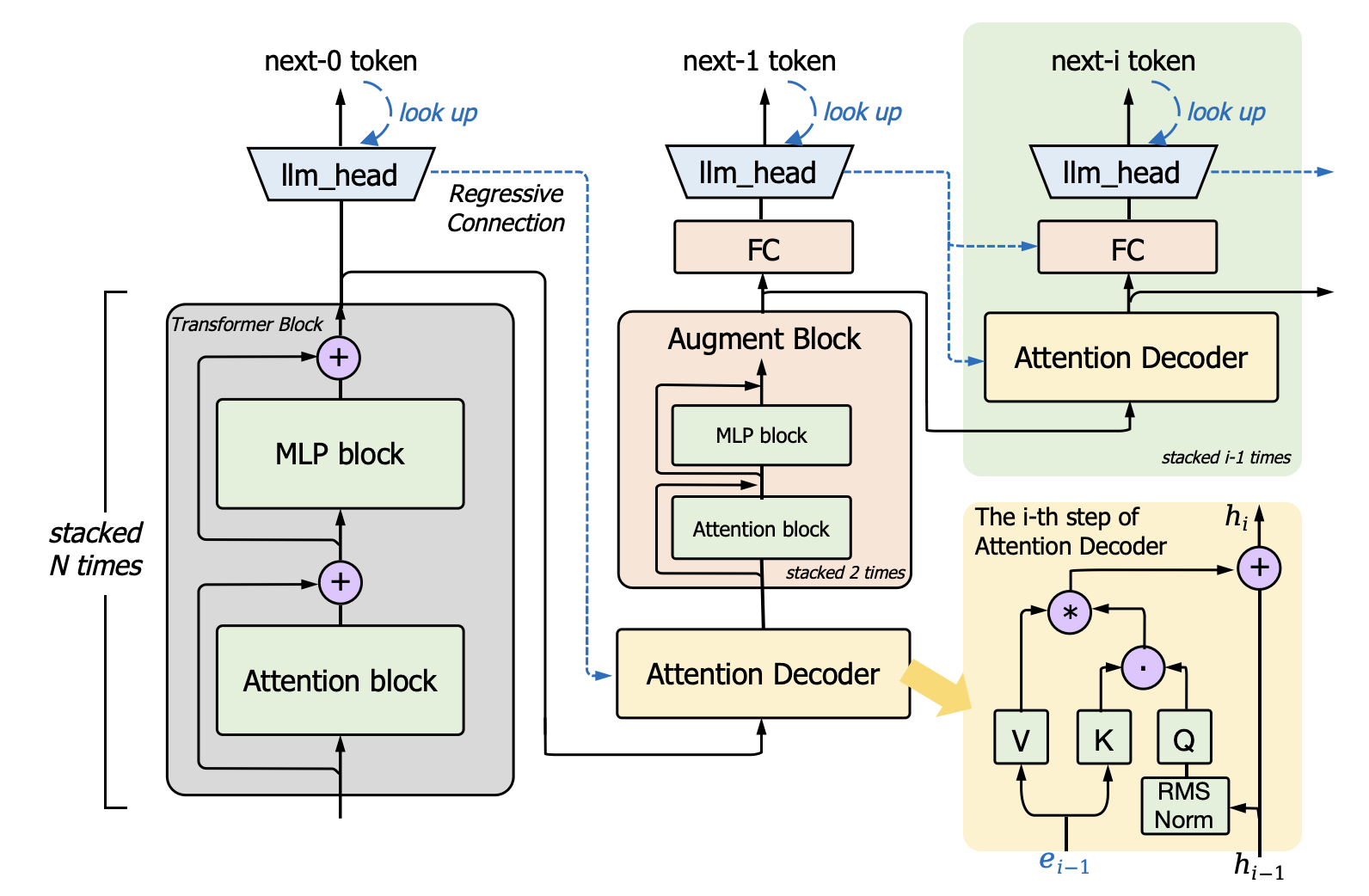
技术框架:Clover-2沿用回归轻量级推测解码的框架,主要包含两个模型:主模型(如Vicuna 7B或LLaMA3-Instruct 8B)和草稿模型(Clover-2)。草稿模型快速生成多个候选tokens,然后主模型并行验证这些tokens,接受正确的tokens并拒绝错误的tokens。Clover-2负责生成高质量的草稿,以供主模型验证。
关键创新:Clover-2的关键创新在于其对RNN草稿模型的改进,使其在精度上接近注意力解码器层模型,同时保持RNN的计算效率。此外,知识蒸馏技术的应用也进一步提升了Clover-2的性能。与现有方法相比,Clover-2在精度和效率之间取得了更好的平衡。
关键设计:Clover-2的具体网络结构细节未知,但摘要中提到增强了模型架构,并结合了知识蒸馏。知识蒸馏的具体实现方式(如使用的损失函数、蒸馏温度等)也未知。这些细节对Clover-2的性能至关重要,但论文摘要中并未详细描述。
🖼️ 关键图片
📊 实验亮点
Clover-2在Vicuna 7B和LLaMA3-Instruct 8B等开源模型上进行了实验,结果表明其性能优于现有方法。具体的性能提升数据未知,但摘要强调Clover-2在各种模型架构中均表现出优越性和鲁棒性,表明其具有良好的泛化能力。
🎯 应用场景
Clover-2可应用于各种需要快速文本生成的场景,例如智能对话机器人、机器翻译、文本摘要等。通过提高大语言模型的推理效率,Clover-2能够降低计算成本,并提升用户体验,使得大语言模型能够更广泛地部署在资源受限的设备上。
📄 摘要(原文)
Large Language Models (LLMs) frequently suffer from inefficiencies, largely attributable to the discord between the requirements of auto-regressive decoding and the architecture of contemporary GPUs. Recently, regressive lightweight speculative decoding has garnered attention for its notable efficiency improvements in text generation tasks. This approach utilizes a lightweight regressive draft model, like a Recurrent Neural Network (RNN) or a single transformer decoder layer, leveraging sequential information to iteratively predict potential tokens. Specifically, RNN draft models are computationally economical but tend to deliver lower accuracy, while attention decoder layer models exhibit the opposite traits. This paper presents Clover-2, an advanced iteration of Clover, an RNN-based draft model designed to achieve comparable accuracy to that of attention decoder layer models while maintaining minimal computational overhead. Clover-2 enhances the model architecture and incorporates knowledge distillation to increase Clover's accuracy and improve overall efficiency. We conducted experiments using the open-source Vicuna 7B and LLaMA3-Instruct 8B models. The results demonstrate that Clover-2 surpasses existing methods across various model architectures, showcasing its efficacy and robustness.