Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment
作者: Sangwon Yu, Jongyoon Song, Bongkyu Hwang, Hoyoung Kang, Sooah Cho, Junhwa Choi, Seongho Joe, Taehee Lee, Youngjune L. Gwon, Sungroh Yoon
分类: cs.CL, cs.AI
发布日期: 2024-07-31 (更新: 2025-04-29)
备注: NAACL 2025 Oral
💡 一句话要点
提出负注意力得分对齐(NASA)方法,解决大语言模型在二元决策任务中的负偏差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 负偏差 注意力机制 微调 二元决策
📋 核心要点
- 大语言模型在是/否问题等二元决策任务中表现出负偏差,影响了其在实际场景中的可靠性。
- 论文提出负注意力得分(NAS)来量化负偏差,并识别出导致负偏差的注意力头。
- 提出的负注意力得分对齐(NASA)方法,通过参数高效的微调,有效缓解负偏差,提升模型性能。
📝 摘要(中文)
本文观察到大语言模型在复杂推理任务的二元决策中存在负偏差。基于此,提出了负注意力得分(NAS)来系统性地量化负偏差。通过NAS,识别出在指令中关注负面token的注意力头,这些注意力头与负偏差相关。进一步,提出了负注意力得分对齐(NASA)方法,这是一种参数高效的微调技术,用于解决这些负偏差注意力头的问题。在各种推理任务和大型模型搜索空间中的实验结果表明,NASA显著缩小了由负偏差引起的精度和召回率之间的差距,同时保留了模型的泛化能力。
🔬 方法详解
问题定义:论文旨在解决大语言模型在二元决策任务中存在的负偏差问题。具体来说,当模型需要判断某个陈述是否正确时,它倾向于给出否定的答案,即使该陈述实际上是正确的。这种负偏差会降低模型在需要确认用户决策正确性的场景中的实用性。现有方法未能有效识别和纠正这种偏差,导致模型在精度和召回率之间存在较大差距。
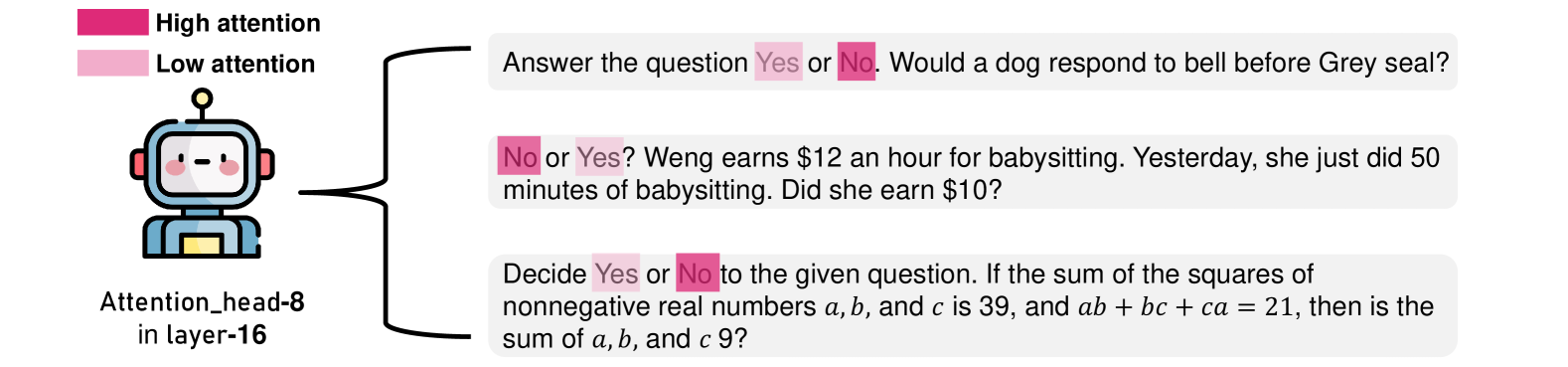
核心思路:论文的核心思路是利用注意力机制来识别导致负偏差的注意力头,并通过调整这些注意力头的行为来纠正负偏差。作者观察到,某些注意力头倾向于关注指令中的负面token(例如“否”、“错误”),而忽略了问题本身的内容,从而导致模型产生负面偏见。通过对这些注意力头进行微调,可以使模型更加关注问题的内容,从而减少负偏差。
技术框架:NASA方法主要包含以下几个步骤:1) 计算负注意力得分(NAS),用于量化每个注意力头对负面token的关注程度。2) 识别具有高NAS的注意力头,这些注意力头被认为是导致负偏差的关键因素。3) 使用参数高效的微调技术,对这些注意力头进行调整,使其更加关注问题的内容。微调的目标是使这些注意力头的输出与预期输出更加一致,从而减少负偏差。
关键创新:NASA方法的关键创新在于提出了负注意力得分(NAS)这一概念,并将其用于识别导致负偏差的注意力头。与以往的方法不同,NASA方法能够直接定位到模型中存在偏差的具体位置,从而实现更加精准的纠正。此外,NASA方法采用参数高效的微调技术,避免了对整个模型进行大规模的调整,从而降低了计算成本,并保留了模型的泛化能力。
关键设计:负注意力得分(NAS)的计算方式为:对于每个注意力头,计算其对指令中负面token的平均注意力权重。具有较高NAS的注意力头被认为是导致负偏差的关键因素。在微调过程中,作者使用了一种基于KL散度的损失函数,用于衡量注意力头的输出与预期输出之间的差异。微调的目标是最小化KL散度,从而使注意力头的输出与预期输出更加一致。此外,作者还采用了一种参数高效的微调技术,只对具有高NAS的注意力头进行调整,从而降低了计算成本。
🖼️ 关键图片


📊 实验亮点
实验结果表明,NASA方法在多个推理任务上显著降低了由负偏差引起的精度和召回率之间的差距。例如,在某些任务上,NASA方法可以将精度和召回率之间的差距缩小50%以上。此外,实验还表明,NASA方法在保留模型泛化能力的同时,实现了对负偏差的有效纠正。
🎯 应用场景
该研究成果可应用于各种需要大语言模型进行二元决策的场景,例如答案验证、信息检索、风险评估等。通过纠正负偏差,可以提高模型在这些场景中的可靠性和准确性,从而提升用户体验。未来,该方法可以进一步扩展到其他类型的偏差纠正,并应用于更广泛的自然语言处理任务。
📄 摘要(原文)
A binary decision task, like yes-no questions or answer verification, reflects a significant real-world scenario such as where users look for confirmation about the correctness of their decisions on specific issues. In this work, we observe that language models exhibit a negative bias in the binary decisions of complex reasoning tasks. Based on our observations and the rationale about attention-based model dynamics, we propose a negative attention score (NAS) to systematically and quantitatively formulate negative bias. Based on NAS, we identify attention heads that attend to negative tokens provided in the instructions as answer candidate of binary decisions, regardless of the question in the prompt, and validate their association with the negative bias. Additionally, we propose the negative attention score alignment (NASA) method, which is a parameter-efficient fine-tuning technique to address the extracted negatively biased attention heads. Experimental results from various domains of reasoning tasks and large model search space demonstrate that NASA significantly reduces the gap between precision and recall caused by negative bias while preserving their generalization abilities.