Towards interfacing large language models with ASR systems using confidence measures and prompting
作者: Maryam Naderi, Enno Hermann, Alexandre Nanchen, Sevada Hovsepyan, Mathew Magimai. -Doss
分类: eess.AS, cs.CL
发布日期: 2024-07-31
备注: 5 pages, 3 figures, 5 tables. Accepted to Interspeech 2024
期刊: Proc. Interspeech 2024, 2980-2984
DOI: 10.21437/Interspeech.2024-989
💡 一句话要点
提出基于置信度过滤和提示的大语言模型ASR转录后处理方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自动语音识别 置信度测量 后处理 提示学习
📋 核心要点
- 现有ASR系统后处理方法依赖于n-best列表重打分,未能充分利用大语言模型的强大能力。
- 论文提出利用大语言模型进行ASR转录后校正,并引入置信度过滤机制,避免引入新的错误。
- 实验结果表明,该方法能够有效提升竞争力较弱的ASR系统的性能,具有实际应用价值。
📝 摘要(中文)
随着大语言模型(LLMs)在参数规模和能力上的增长,例如通过提示进行交互,它们为自动语音识别(ASR)系统提供了一种新的接口方式,超越了重打分n-best列表。本研究探讨了使用LLMs对ASR转录进行后处理校正。为了避免将错误引入到可能准确的转录中,我们提出了一系列基于置信度的过滤方法。我们的结果表明,这可以提高竞争力较弱的ASR系统的性能。
🔬 方法详解
问题定义:论文旨在解决如何利用大语言模型(LLMs)提升自动语音识别(ASR)系统的转录准确率的问题。现有方法,如n-best列表重打分,无法充分利用LLMs的强大能力,且可能引入新的错误,尤其是在ASR系统本身性能不佳时。
核心思路:核心思路是使用LLMs对ASR转录进行后处理校正,但为了避免引入新的错误,引入基于置信度的过滤机制。只有当ASR系统对某些词的置信度较低时,才使用LLM进行校正。这样可以保留ASR系统已经正确识别的部分,并利用LLM纠正可能出错的部分。
技术框架:整体框架包含以下几个阶段:1) ASR系统生成初始转录和置信度分数;2) 基于置信度分数对转录进行过滤,确定需要LLM校正的部分;3) 使用提示(Prompting)技术,将需要校正的部分输入LLM,并获得LLM的校正结果;4) 将LLM的校正结果与原始转录进行融合,生成最终的转录结果。
关键创新:关键创新在于结合了置信度过滤和LLM提示技术。置信度过滤能够有效避免LLM引入新的错误,而LLM提示技术则能够充分利用LLM的语言理解和生成能力,提升转录的准确率。这种结合使得该方法在提升ASR系统性能的同时,保证了转录的可靠性。
关键设计:论文中关键的设计包括:1) 置信度阈值的选择,需要根据具体的ASR系统和数据集进行调整;2) 提示的设计,需要充分考虑LLM的输入格式和输出格式,以获得最佳的校正效果;3) 如何将LLM的校正结果与原始转录进行融合,例如可以使用加权平均或者规则的方式。
🖼️ 关键图片

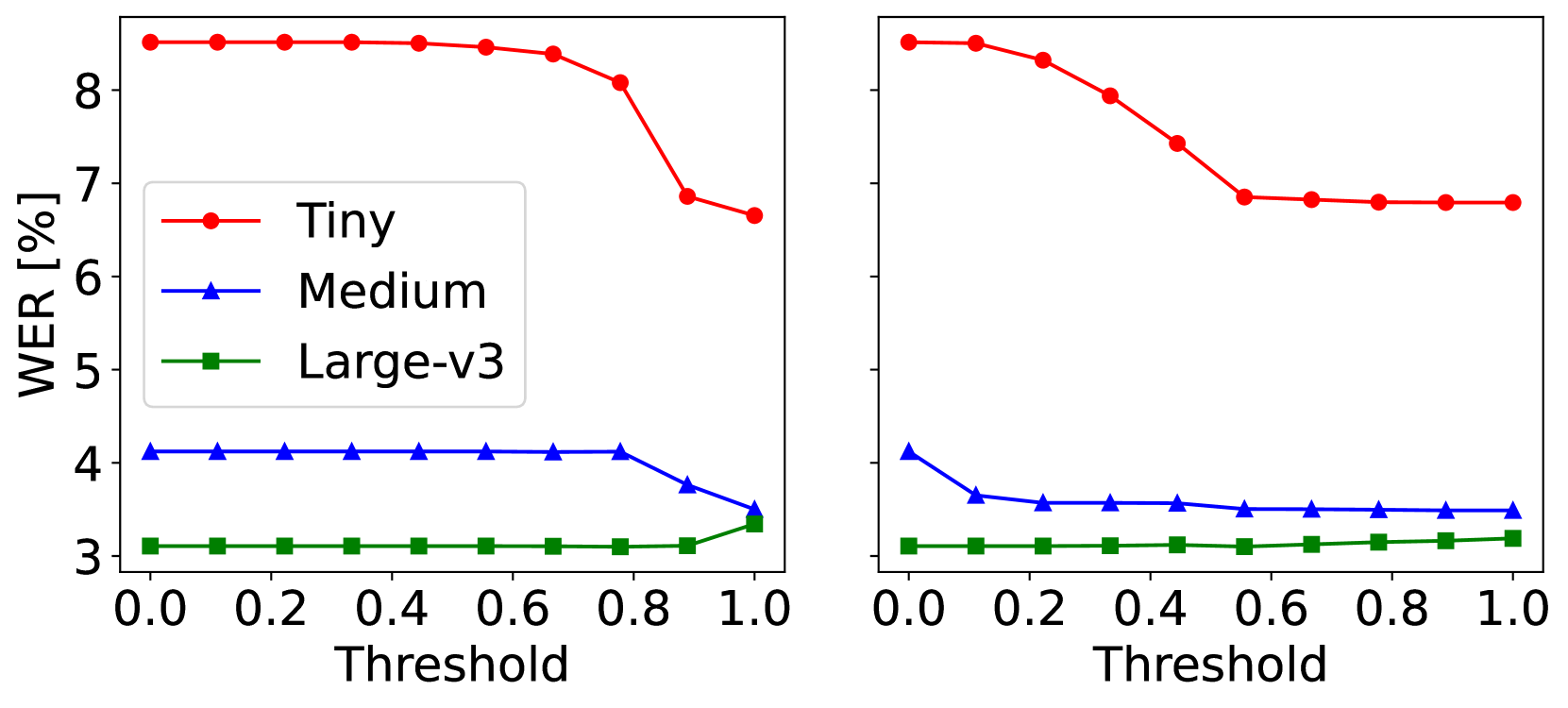
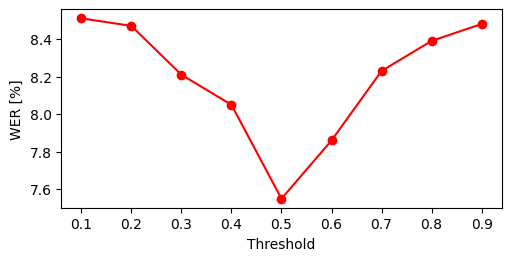
📊 实验亮点
实验结果表明,提出的基于置信度过滤和提示的大语言模型ASR转录后处理方法,能够有效提升竞争力较弱的ASR系统的性能。具体提升幅度取决于ASR系统的性能和置信度阈值的选择。该方法在避免引入新的错误的同时,利用LLM的强大能力纠正了ASR系统可能出错的部分。
🎯 应用场景
该研究成果可应用于语音助手、语音搜索、会议记录、字幕生成等领域。通过提升ASR系统的转录准确率,可以改善用户体验,提高工作效率。未来,该方法可以进一步扩展到多语言ASR系统,并与其他自然语言处理技术相结合,实现更智能的语音交互。
📄 摘要(原文)
As large language models (LLMs) grow in parameter size and capabilities, such as interaction through prompting, they open up new ways of interfacing with automatic speech recognition (ASR) systems beyond rescoring n-best lists. This work investigates post-hoc correction of ASR transcripts with LLMs. To avoid introducing errors into likely accurate transcripts, we propose a range of confidence-based filtering methods. Our results indicate that this can improve the performance of less competitive ASR systems.