Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances
作者: Zehui Wu, Ziwei Gong, Lin Ai, Pengyuan Shi, Kaan Donbekci, Julia Hirschberg
分类: cs.CL, cs.AI
发布日期: 2024-07-31 (更新: 2024-12-23)
💡 一句话要点
提出SpeechCueLLM,利用语音特征描述增强LLM在情感识别中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音情感识别 大型语言模型 多模态学习 自然语言描述 语音特征提取
📋 核心要点
- 语音情感识别需要理解语音内容和语音细微差别,现有方法难以有效融合这两种信息。
- SpeechCueLLM将语音特征转化为自然语言描述,使LLM能够通过文本提示进行多模态情感分析。
- 实验表明,SpeechCueLLM在IEMOCAP和MELD数据集上显著提高了情感识别准确率,F1分数提升超过2%。
📝 摘要(中文)
本文提出了一种新颖的情感识别方法,该方法利用大型语言模型(LLM)在自然语言理解方面的卓越能力。为了克服LLM在处理音频输入方面的固有局限性,我们提出了SpeechCueLLM,该方法将语音特征转化为自然语言描述,从而允许LLM通过文本提示执行多模态情感分析,而无需任何架构上的修改。我们的方法简洁有效,优于需要结构修改的基线模型。我们在IEMOCAP和MELD两个数据集上评估了SpeechCueLLM,结果表明情感识别准确率显著提高,尤其是在高质量音频数据上。我们还探讨了各种特征表示和微调策略对不同LLM的有效性。实验表明,结合语音描述使IEMOCAP上的平均加权F1分数提高了2%以上(从70.111%提高到72.596%)。
🔬 方法详解
问题定义:论文旨在解决语音情感识别中,大型语言模型(LLM)难以直接处理音频输入的问题。现有方法通常需要对LLM的架构进行修改,或者依赖复杂的音频处理模块,增加了模型的复杂性和训练难度。这些方法难以充分利用LLM强大的自然语言理解能力,并且在处理不同质量的音频数据时表现不稳定。
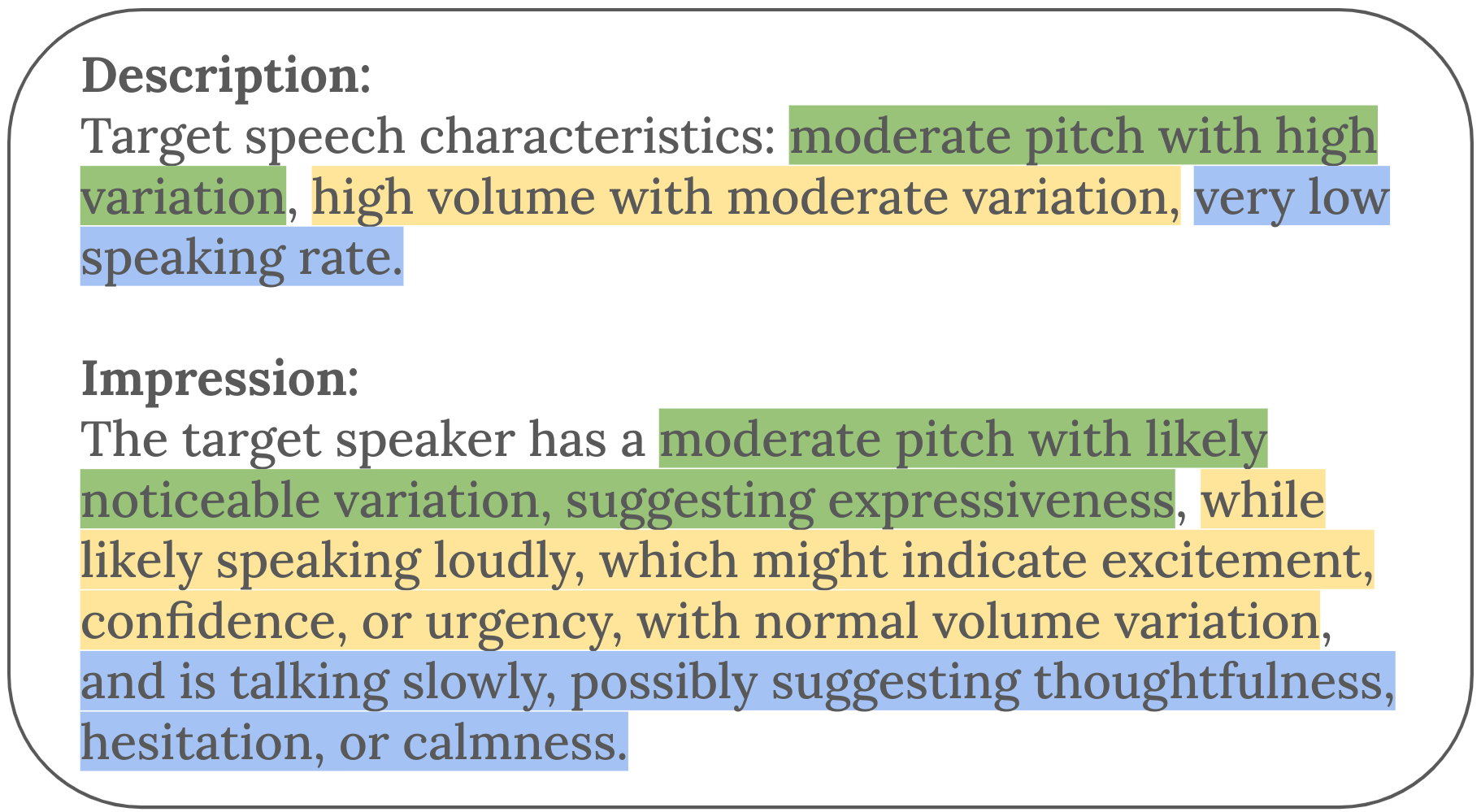
核心思路:论文的核心思路是将语音的声学特征转化为自然语言描述,然后将这些描述作为LLM的输入提示(prompt)。这样,LLM就可以利用其强大的文本理解能力来分析语音中的情感信息,而无需直接处理原始音频信号。这种方法充分利用了LLM的现有能力,避免了对LLM架构的修改,降低了模型的复杂性。
技术框架:SpeechCueLLM的整体框架包括以下几个主要步骤:1) 语音特征提取:从原始音频信号中提取声学特征,例如梅尔频率倒谱系数(MFCC)、音高(pitch)、能量(energy)等。2) 特征描述生成:将提取的声学特征转化为自然语言描述。例如,可以将音高描述为“声音很高亢”,将能量描述为“声音很洪亮”。3) LLM情感分析:将生成的自然语言描述作为LLM的输入提示,让LLM分析语音中的情感信息。4) 情感分类:LLM输出情感分类结果。
关键创新:该方法最重要的技术创新点在于将语音特征转化为自然语言描述,从而实现了LLM在语音情感识别中的应用,而无需对LLM的架构进行修改。与现有方法相比,SpeechCueLLM更加简洁有效,并且能够充分利用LLM强大的自然语言理解能力。
关键设计:在特征描述生成阶段,论文探索了不同的特征表示方法和描述模板。例如,可以使用不同的词汇来描述音高和能量的变化。在LLM情感分析阶段,论文尝试了不同的LLM模型和微调策略。例如,可以使用不同的预训练模型作为LLM的骨干网络,并使用情感识别数据集对LLM进行微调。此外,论文还研究了不同长度的输入提示对情感识别结果的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SpeechCueLLM在IEMOCAP数据集上的平均加权F1分数从70.111%提高到72.596%,提升超过2%。尤其是在高质量音频数据上,SpeechCueLLM的表现更加出色。此外,实验还表明,不同的特征表示方法和微调策略对情感识别结果有显著影响,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于智能客服、心理健康监测、人机交互等领域。通过分析语音中的情感信息,可以更准确地理解用户的需求和情绪状态,从而提供更个性化、更人性化的服务。未来,该方法有望扩展到其他语音分析任务,例如语音识别、语音合成等。
📄 摘要(原文)
Emotion recognition in speech is a challenging multimodal task that requires understanding both verbal content and vocal nuances. This paper introduces a novel approach to emotion detection using Large Language Models (LLMs), which have demonstrated exceptional capabilities in natural language understanding. To overcome the inherent limitation of LLMs in processing audio inputs, we propose SpeechCueLLM, a method that translates speech characteristics into natural language descriptions, allowing LLMs to perform multimodal emotion analysis via text prompts without any architectural changes. Our method is minimal yet impactful, outperforming baseline models that require structural modifications. We evaluate SpeechCueLLM on two datasets: IEMOCAP and MELD, showing significant improvements in emotion recognition accuracy, particularly for high-quality audio data. We also explore the effectiveness of various feature representations and fine-tuning strategies for different LLMs. Our experiments demonstrate that incorporating speech descriptions yields a more than 2% increase in the average weighted F1 score on IEMOCAP (from 70.111% to 72.596%).