Affective Computing in the Era of Large Language Models: A Survey from the NLP Perspective
作者: Yiqun Zhang, Xiaocui Yang, Xingle Xu, Zeran Gao, Yijie Huang, Shiyi Mu, Shi Feng, Daling Wang, Yifei Zhang, Kaisong Song, Ge Yu
分类: cs.CL, cs.CY
发布日期: 2024-07-30 (更新: 2025-09-07)
备注: Compared with the previous version, reinforcement learning has been added (as a new section), including RLHF, RLVR, and RLAIF
💡 一句话要点
综述:大型语言模型时代的情感计算——NLP视角下的研究进展与挑战
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感计算 大型语言模型 指令调优 提示工程 强化学习 情感理解 情感生成
📋 核心要点
- 现有情感计算方法,尤其是基于微调PLM的方法,在跨任务泛化能力和情感生成的多样性与情感匹配度上存在不足。
- 本研究综述了大型语言模型(LLM)在情感计算中的应用,重点关注情感理解和情感生成任务,并分析了各种适应技术。
- 论文总结了指令调优、提示工程和强化学习等技术在提升LLM情感计算能力方面的应用,并探讨了伦理、安全和评估等挑战。
📝 摘要(中文)
情感计算(AC)整合了计算机科学、心理学和认知科学,旨在使机器能够识别、解释和模拟人类情感,应用于社交媒体、金融、医疗保健和教育等领域。情感计算通常围绕两个任务族:情感理解(AU)和情感生成(AG)。虽然微调的预训练语言模型(PLM)在情感理解方面取得了显著的性能,但它们在跨任务泛化方面表现不佳,并且在情感生成方面仍然受到限制,尤其是在产生多样化、情感适当的响应方面。大型语言模型(LLM)(例如,ChatGPT和LLaMA)的出现通过提供上下文学习、更广泛的世界知识和更强的序列生成能力,催化了一场范式转变。本综述从NLP的角度概述了LLM时代的情感计算。我们(i)整合了传统的AC任务和初步的基于LLM的研究;(ii)回顾了改进AU/AG的适应技术,包括指令调优(完整和参数高效的方法,如LoRA、P-/Prompt-Tuning)、提示工程(零/少样本、思维链、基于代理的提示)和强化学习。对于后者,我们总结了来自人类偏好的强化学习(RLHF)、可验证/程序化奖励(RLVR)和AI反馈(RLAIF),它们提供了基于偏好或规则的优化信号,可以帮助引导AU/AG走向同理心、安全性和规划,实现更细粒度或多目标控制。为了评估进展,我们为AU和AG汇编了基准和评估实践。我们还讨论了开放的挑战——从伦理、数据质量和安全到稳健的评估和资源效率——并概述了研究方向。我们希望本综述能够阐明现状,并为构建具有情感意识、可靠和负责任的LLM系统提供实践指导。
🔬 方法详解
问题定义:情感计算旨在让机器理解和生成人类情感,传统方法在跨领域泛化和生成情感丰富、恰当的文本方面存在局限性。现有方法难以有效利用上下文信息,且生成的情感表达往往缺乏多样性和真实性。
核心思路:利用大型语言模型(LLM)强大的上下文学习能力、丰富的世界知识和卓越的序列生成能力,提升情感理解和情感生成的效果。通过合适的调优策略和提示工程,引导LLM更好地理解和表达情感。
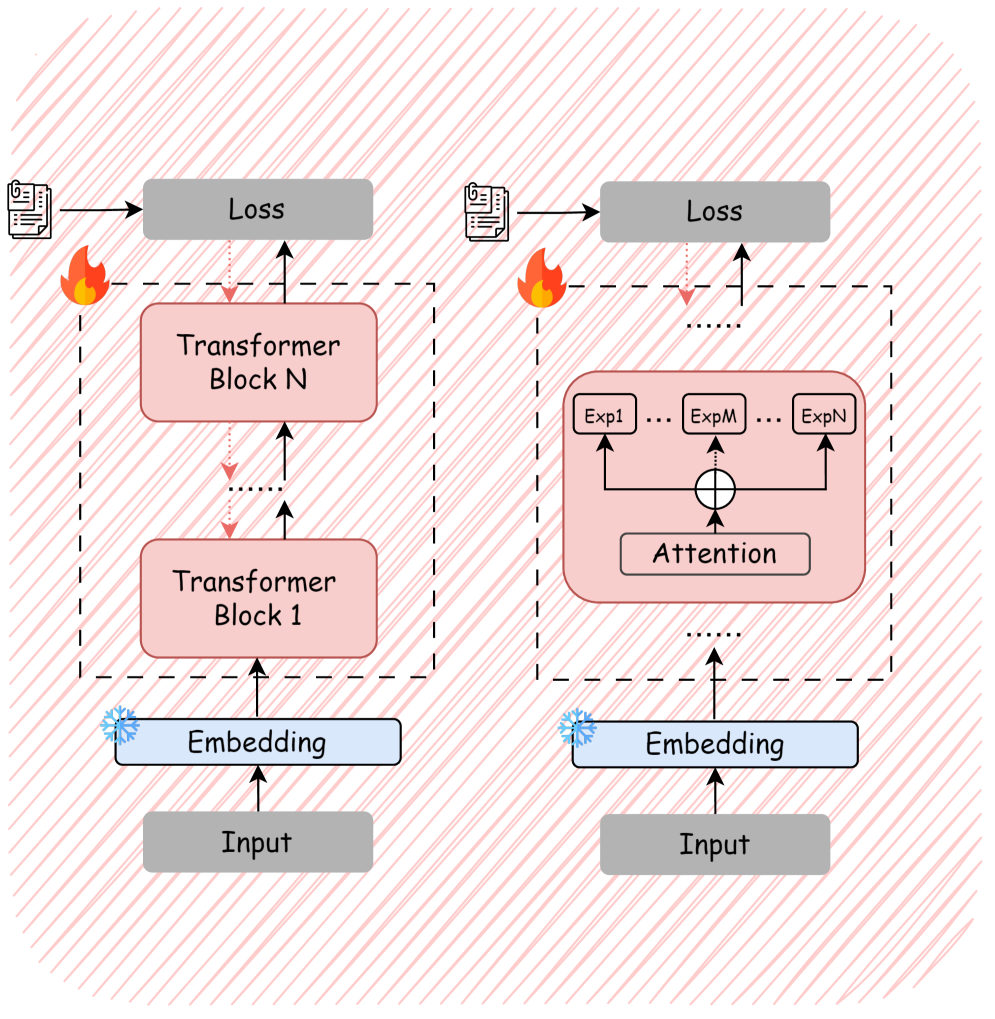
技术框架:该综述没有提出新的技术框架,而是对现有基于LLM的情感计算方法进行了系统性的梳理和总结。主要涉及三个方面:指令调优(Instruction Tuning)、提示工程(Prompt Engineering)和强化学习(Reinforcement Learning)。指令调优旨在通过指令微调使LLM更好地遵循指令并完成情感相关的任务。提示工程通过设计合适的提示词引导LLM生成期望的情感输出。强化学习则通过奖励机制优化LLM的情感表达能力。
关键创新:该综述的关键创新在于对LLM时代情感计算领域的研究进行了全面的总结和分析,并指出了未来的研究方向。它整合了传统情感计算任务与基于LLM的初步研究,并对各种适应技术进行了分类和比较。
关键设计:综述中讨论的关键设计包括:不同类型的指令调优方法(如LoRA、Prompt Tuning),不同类型的提示工程策略(如零/少样本学习、思维链提示),以及不同类型的强化学习方法(如RLHF、RLVR、RLAIF)。这些方法在情感计算中的应用和效果各不相同,需要根据具体任务进行选择和调整。
🖼️ 关键图片


📊 实验亮点
该综述总结了基于LLM的情感计算研究进展,强调了指令调优、提示工程和强化学习等技术在提升情感理解和生成能力方面的作用。通过对现有方法的分析和比较,为研究人员提供了有价值的参考,并指出了未来研究的潜在方向,例如如何解决伦理、安全和评估等挑战。
🎯 应用场景
该研究成果可应用于多个领域,如智能客服、情感聊天机器人、心理健康咨询、社交媒体情感分析等。通过提升机器的情感理解和生成能力,可以构建更具同理心和人情味的AI系统,从而改善人机交互体验,并为用户提供更个性化和贴心的服务。
📄 摘要(原文)
Affective Computing (AC) integrates computer science, psychology, and cognitive science to enable machines to recognize, interpret, and simulate human emotions across domains such as social media, finance, healthcare, and education. AC commonly centers on two task families: Affective Understanding (AU) and Affective Generation (AG). While fine-tuned pre-trained language models (PLMs) have achieved solid AU performance, they often generalize poorly across tasks and remain limited for AG, especially in producing diverse, emotionally appropriate responses. The advent of Large Language Models (LLMs) (e.g., ChatGPT and LLaMA) has catalyzed a paradigm shift by offering in-context learning, broader world knowledge, and stronger sequence generation. This survey presents an NLP-oriented overview of AC in the LLM era. We (i) consolidate traditional AC tasks and preliminary LLM-based studies; (ii) review adaptation techniques that improve AU/AG, including Instruction Tuning (full and parameter-efficient methods such as LoRA, P-/Prompt-Tuning), Prompt Engineering (zero/few-shot, chain-of-thought, agent-based prompting), and Reinforcement Learning. For the latter, we summarize RL from human preferences (RLHF), verifiable/programmatic rewards (RLVR), and AI feedback (RLAIF), which provide preference- or rule-grounded optimization signals that can help steer AU/AG toward empathy, safety, and planning, achieving finer-grained or multi-objective control. To assess progress, we compile benchmarks and evaluation practices for both AU and AG. We also discuss open challenges-from ethics, data quality, and safety to robust evaluation and resource efficiency-and outline research directions. We hope this survey clarifies the landscape and offers practical guidance for building affect-aware, reliable, and responsible LLM systems.