Accelerating Large Language Model Inference with Self-Supervised Early Exits
作者: Florian Valade
分类: cs.CL, cs.LG, stat.ML
发布日期: 2024-07-30
💡 一句话要点
提出自监督早期退出方法,加速大语言模型推理并保持精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理加速 早期退出 自监督学习 Transformer 置信度估计 实时处理
📋 核心要点
- 大型语言模型推理计算成本高昂,限制了其在资源受限环境中的应用。
- 通过在Transformer层添加早期退出头,并使用自监督学习训练,模型可以在保证精度的情况下提前终止推理。
- 该方法在特定任务上减少了计算时间,同时保持了原始模型的精度,无需大量重新训练。
📝 摘要(中文)
本文提出了一种加速大型预训练语言模型(LLM)推理的新技术,通过在推理过程中引入早期退出机制实现。鉴于这些模型在广泛应用中的巨大计算需求,该方法利用token复杂度的内在差异,实现推理过程的选择性加速。具体而言,我们在现有Transformer层之上集成了早期退出“头”,这些“头”基于置信度指标促进有条件的终止。这些“头”以自监督方式训练,使用模型自身的预测作为训练数据,从而无需额外的标注数据。置信度指标通过校准集建立,确保所需的精度水平,并在置信度超过预定阈值时实现早期终止。值得注意的是,我们的方法保留了原始精度,并在某些任务上减少了计算时间,利用了预训练LLM的现有知识,而无需进行广泛的再训练。这种轻量级、模块化的修改具有极大的潜力,可以显著提高LLM的实际可用性,尤其是在资源受限环境中的实时语言处理等应用中。
🔬 方法详解
问题定义:大型语言模型(LLM)在推理阶段计算量巨大,尤其是在处理长文本或实时性要求高的场景下,效率成为瓶颈。现有的方法通常需要对模型进行压缩或蒸馏,这可能会牺牲模型的精度。如何在不显著降低模型性能的前提下,加速LLM的推理过程是一个关键问题。
核心思路:本文的核心思路是利用不同token的复杂程度不同,对于简单的token,模型可能在较浅的层就能给出足够准确的预测,因此可以提前退出推理。通过在Transformer的中间层添加“早期退出头”,并根据置信度指标判断是否需要提前终止推理,从而减少不必要的计算。
技术框架:该方法在预训练的LLM的每个或部分Transformer层后添加一个早期退出头。每个退出头接收对应层的输出,并预测下一个token。同时,使用一个校准集来确定置信度阈值。在推理时,如果某个token的置信度超过阈值,则提前退出,否则继续执行后续层。整体流程包括:1) 在Transformer层后添加早期退出头;2) 使用自监督学习训练这些退出头;3) 使用校准集确定置信度阈值;4) 在推理时,根据置信度动态调整推理深度。
关键创新:该方法最大的创新在于使用自监督学习来训练早期退出头,避免了对额外标注数据的需求。此外,该方法是一种轻量级的模块化修改,可以方便地应用于现有的预训练LLM,而无需进行大量的重新训练。通过置信度指标动态调整推理深度,实现了在精度和效率之间的平衡。
关键设计:早期退出头通常是一个简单的分类器,例如一个线性层或一个小型MLP。损失函数通常是交叉熵损失,用于衡量预测token与真实token之间的差异。置信度指标的选择也很重要,可以使用softmax输出的最大概率值,或者使用其他更复杂的置信度估计方法。校准集的选择也很关键,需要能够代表模型在实际应用中可能遇到的各种情况。
🖼️ 关键图片
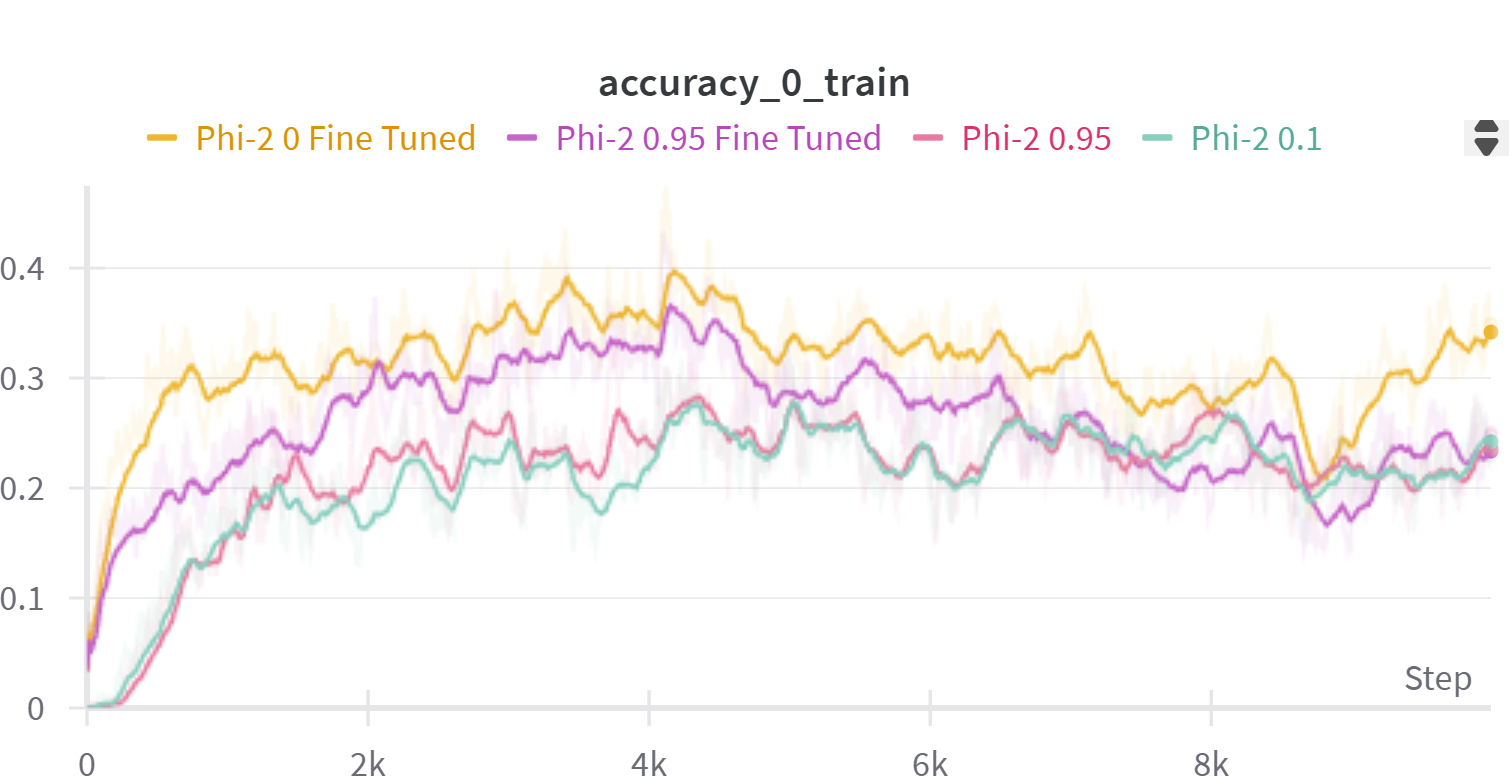
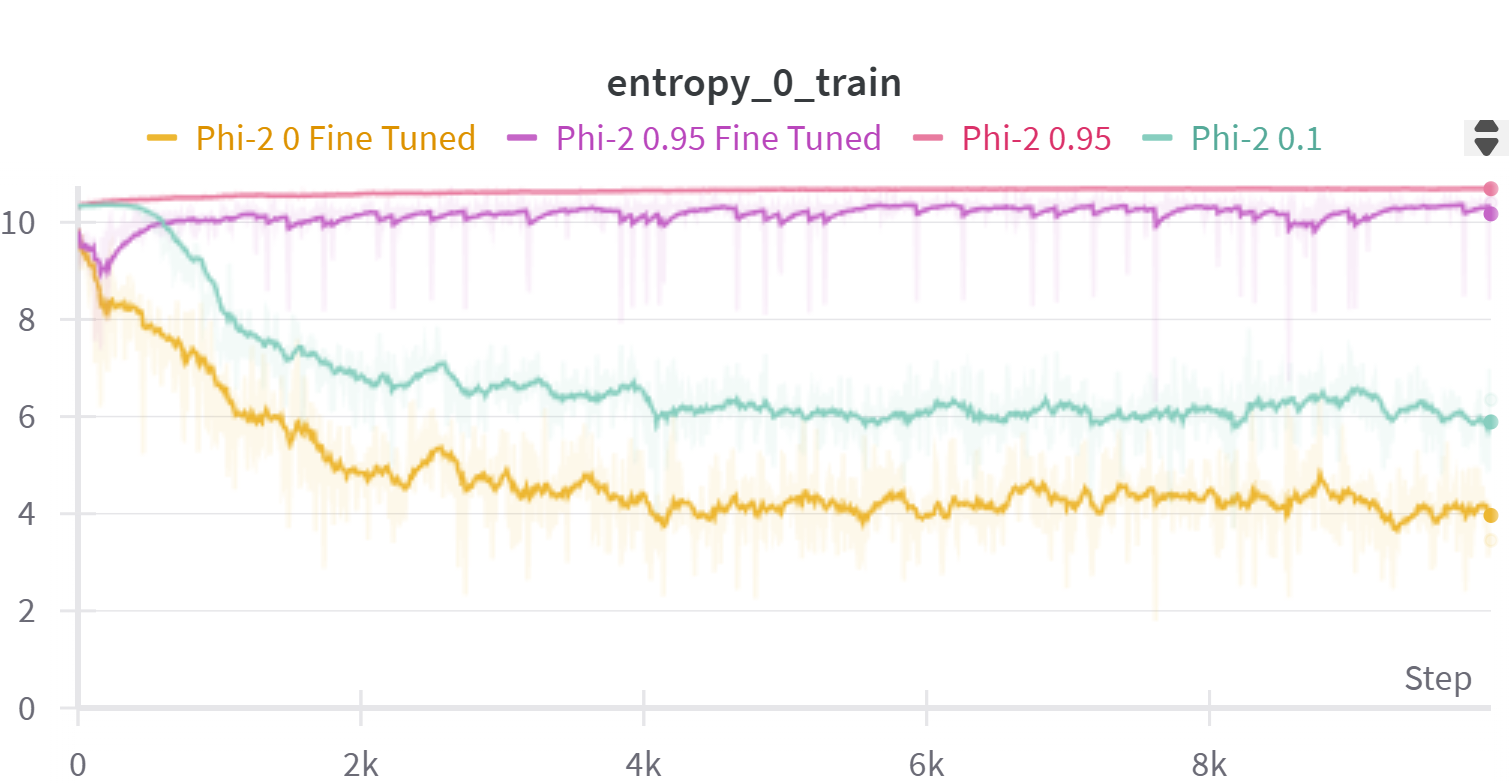
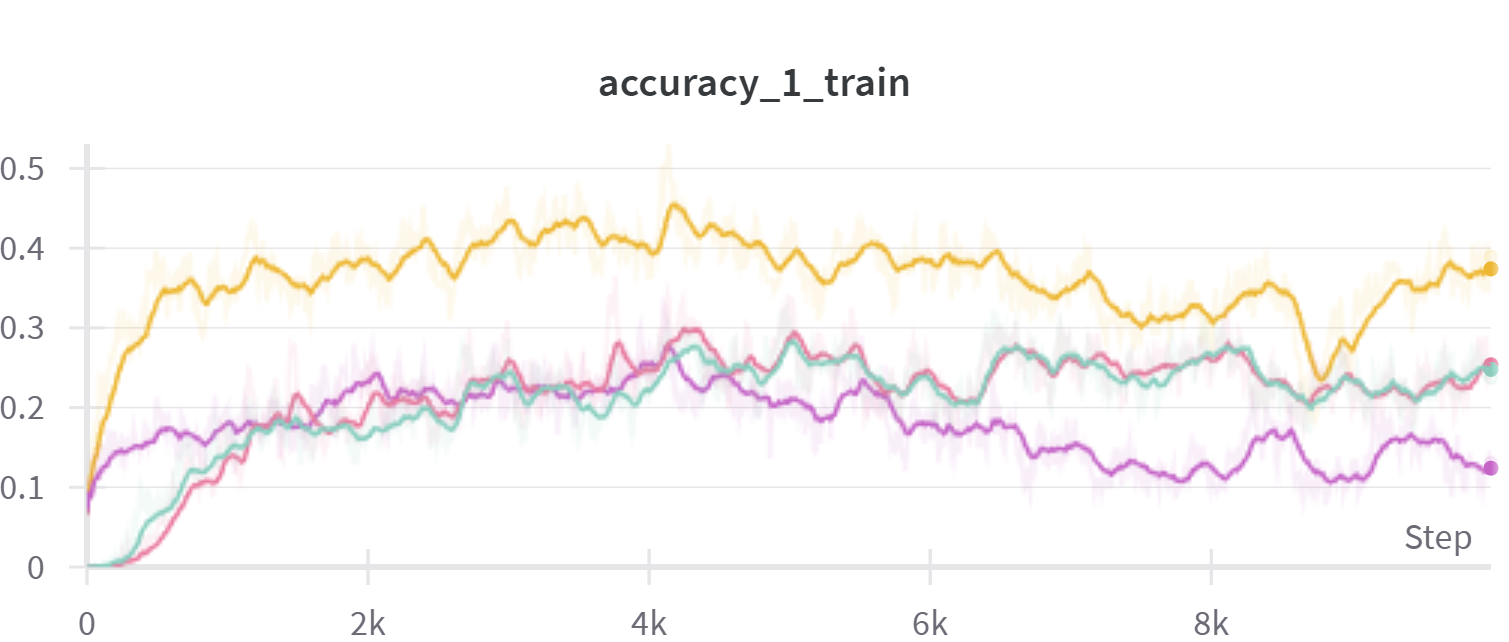
📊 实验亮点
论文提出的自监督早期退出方法能够在保持原始模型精度的前提下,显著加速LLM的推理速度。具体性能数据未知,但摘要强调该方法在特定任务上减少了计算时间,同时利用了预训练LLM的现有知识,无需进行大量的重新训练。该方法是一种轻量级的模块化修改,易于部署和应用。
🎯 应用场景
该研究成果可广泛应用于对延迟敏感的自然语言处理任务,如实时翻译、语音识别、对话系统等。在资源受限的设备上,如移动设备或嵌入式系统,该方法可以显著提高LLM的推理速度,使其能够部署在更广泛的应用场景中。此外,该技术还可以用于降低LLM的能耗,从而减少碳排放,实现更可持续的AI发展。
📄 摘要(原文)
This paper presents a novel technique for accelerating inference in large, pre-trained language models (LLMs) by introducing early exits during inference. The computational demands of these models, used across a wide range of applications, can be substantial. By capitalizing on the inherent variability in token complexity, our approach enables selective acceleration of the inference process. Specifically, we propose the integration of early exit ''heads'' atop existing transformer layers, which facilitate conditional terminations based on a confidence metric. These heads are trained in a self-supervised manner using the model's own predictions as training data, thereby eliminating the need for additional annotated data. The confidence metric, established using a calibration set, ensures a desired level of accuracy while enabling early termination when confidence exceeds a predetermined threshold. Notably, our method preserves the original accuracy and reduces computational time on certain tasks, leveraging the existing knowledge of pre-trained LLMs without requiring extensive retraining. This lightweight, modular modification has the potential to greatly enhance the practical usability of LLMs, particularly in applications like real-time language processing in resource-constrained environments.