QAEA-DR: A Unified Text Augmentation Framework for Dense Retrieval
作者: Hongming Tan, Shaoxiong Zhan, Hai Lin, Hai-Tao Zheng, Wai Kin Chan
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-07-29 (更新: 2025-03-01)
DOI: 10.1109/TKDE.2025.3543203
💡 一句话要点
QAEA-DR:一种用于稠密检索的统一文本增强框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稠密检索 文本增强 大型语言模型 问答生成 事件抽取 零样本学习 信息检索
📋 核心要点
- 稠密检索中长文本嵌入易导致信息损失,低质量文本难以与查询对齐,现有方法侧重于改进模型或检索过程。
- QAEA-DR框架通过LLM零样本提示,将原始文档转换为信息密集的问答对和元素驱动事件,增强文本表示。
- 引入基于评分的评估和再生机制,提升生成文本质量。实验结果表明QAEA-DR模型对稠密检索有积极影响。
📝 摘要(中文)
在稠密检索中,将长文本嵌入到稠密向量中可能导致信息丢失,从而导致不准确的查询-文本匹配。此外,包含过多噪声或关键信息稀疏的低质量文本不太可能与相关查询良好对齐。最近的研究主要集中在改进句子嵌入模型或检索过程。本文提出了一种用于稠密检索的新型文本增强框架。该框架将原始文档转换为信息密集的文本格式,这些格式补充了原始文本,从而有效地解决了上述问题,而无需修改嵌入或检索方法。通过大型语言模型(LLM)的零样本提示生成两种文本表示:问答对和元素驱动的事件。我们将这种方法称为QAEA-DR:在文本增强框架中统一问答生成和事件抽取以进行稠密检索。为了进一步提高生成文本的质量,在LLM提示中引入了基于评分的评估和再生机制。理论分析和实验结果表明,我们的QAEA-DR模型对稠密检索具有积极影响。
🔬 方法详解
问题定义:稠密检索面临长文本信息损失和低质量文本难以匹配的问题。现有方法主要集中在改进句子嵌入模型或检索过程,忽略了对原始文本进行增强以提高其信息密度和质量。
核心思路:通过文本增强,将原始文档转换为信息更密集的格式,从而提高查询-文本匹配的准确性。核心思想是利用大型语言模型(LLM)生成更易于检索的文本表示,而无需修改现有的嵌入或检索方法。
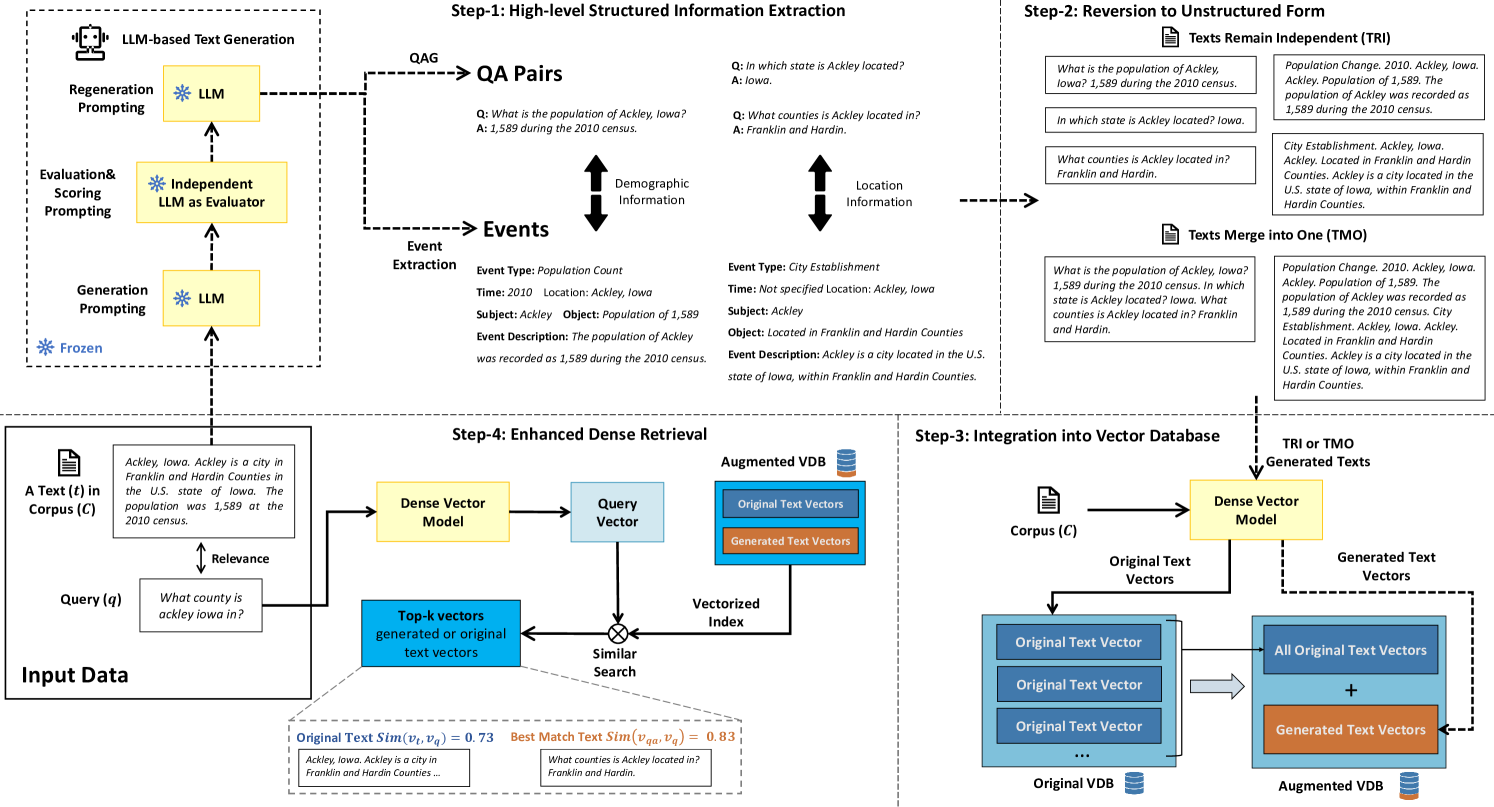
技术框架:QAEA-DR框架包含以下主要模块:1) LLM零样本提示生成问答对(QA)和元素驱动的事件(Element-driven Events);2) 基于评分的评估模块,评估生成文本的质量;3) 再生模块,根据评估结果对低质量文本进行重新生成。整体流程是将原始文档输入LLM,生成QA和事件,然后评估其质量,对低质量部分进行再生,最后将增强后的文本用于稠密检索。
关键创新:QAEA-DR的关键创新在于:1) 提出了一种统一的文本增强框架,将问答生成和事件抽取结合起来,生成信息密集的文本表示;2) 引入了基于评分的评估和再生机制,提高了生成文本的质量;3) 无需修改现有的嵌入或检索方法,即可提升稠密检索的性能。与现有方法相比,QAEA-DR更加灵活,可以与各种稠密检索模型结合使用。
关键设计:LLM采用零样本提示,提示词的设计对生成文本的质量至关重要。评分模块的设计需要考虑多个因素,例如文本的流畅性、信息密度和与原始文档的相关性。再生模块的触发阈值需要根据实验结果进行调整。论文中没有明确说明具体的参数设置、损失函数或网络结构,因为该框架主要依赖于LLM的生成能力,而不是特定的模型结构。
🖼️ 关键图片

📊 实验亮点
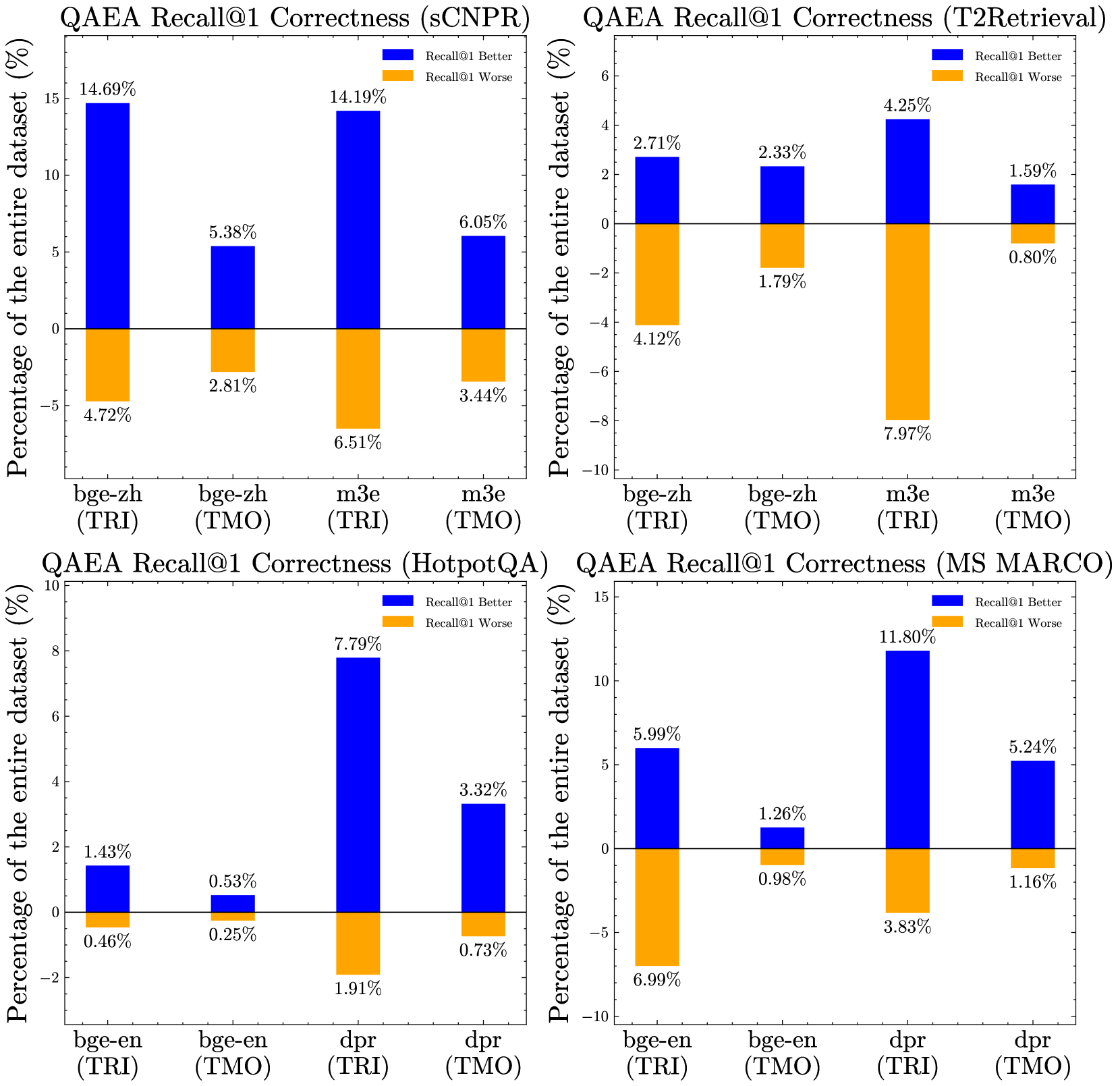
实验结果表明,QAEA-DR模型在稠密检索任务上取得了显著的性能提升。具体来说,通过生成问答对和事件,模型能够更好地捕捉文本中的关键信息,从而提高查询-文本匹配的准确性。此外,基于评分的评估和再生机制有效地提高了生成文本的质量,进一步提升了检索性能。具体的性能数据和对比基线在论文中进行了详细的描述。
🎯 应用场景
QAEA-DR框架可应用于各种需要信息检索的场景,例如问答系统、文档检索、知识库构建等。通过增强原始文本的信息密度和质量,可以提高检索的准确性和效率。该框架还可以用于处理低质量或噪声较多的文本,例如社交媒体数据或用户生成内容,从而提高信息检索的鲁棒性。未来,可以将QAEA-DR框架与其他文本增强技术结合使用,进一步提高检索性能。
📄 摘要(原文)
In dense retrieval, embedding long texts into dense vectors can result in information loss, leading to inaccurate query-text matching. Additionally, low-quality texts with excessive noise or sparse key information are unlikely to align well with relevant queries. Recent studies mainly focus on improving the sentence embedding model or retrieval process. In this work, we introduce a novel text augmentation framework for dense retrieval. This framework transforms raw documents into information-dense text formats, which supplement the original texts to effectively address the aforementioned issues without modifying embedding or retrieval methodologies. Two text representations are generated via large language models (LLMs) zero-shot prompting: question-answer pairs and element-driven events. We term this approach QAEA-DR: unifying question-answer generation and event extraction in a text augmentation framework for dense retrieval. To further enhance the quality of generated texts, a scoring-based evaluation and regeneration mechanism is introduced in LLM prompting. Our QAEA-DR model has a positive impact on dense retrieval, supported by both theoretical analysis and empirical experiments.