Comparative Analysis of Encoder-Based NER and Large Language Models for Skill Extraction from Russian Job Vacancies
作者: Nikita Matkin, Aleksei Smirnov, Mikhail Usanin, Egor Ivanov, Kirill Sobyanin, Sofiia Paklina, Petr Parshakov
分类: cs.CL
发布日期: 2024-07-29 (更新: 2024-09-15)
💡 一句话要点
对比Encoder与LLM,用于俄语招聘信息技能提取,发现传统NER模型更优
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体识别 技能提取 大型语言模型 俄语NLP 招聘信息
📋 核心要点
- 当前劳动力市场技能需求快速变化,职位描述中技能识别面临雇主要求各异和关键技能遗漏的挑战。
- 该研究对比了基于Encoder的传统NER方法和大型语言模型(LLM)在俄语职位空缺中提取技能的性能。
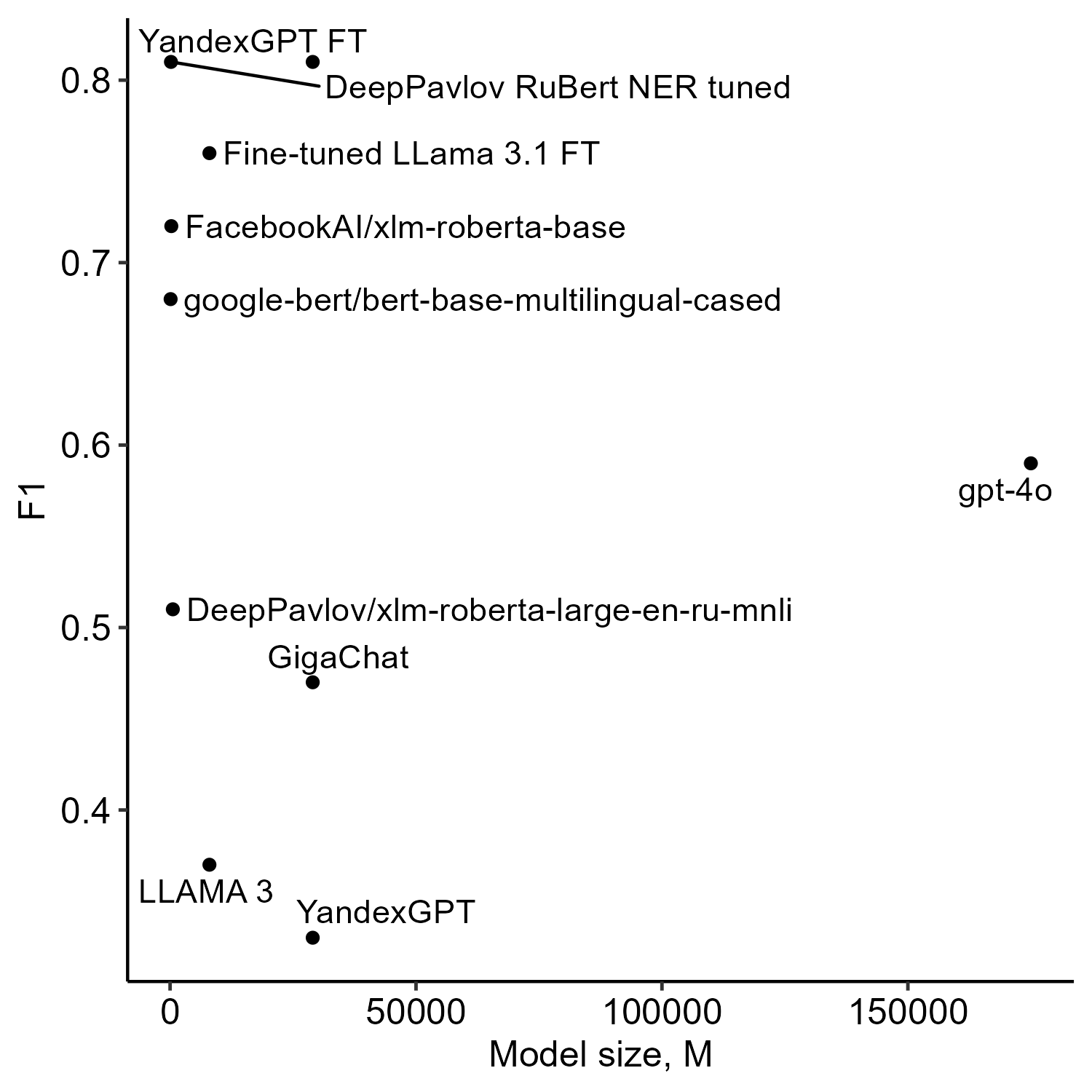
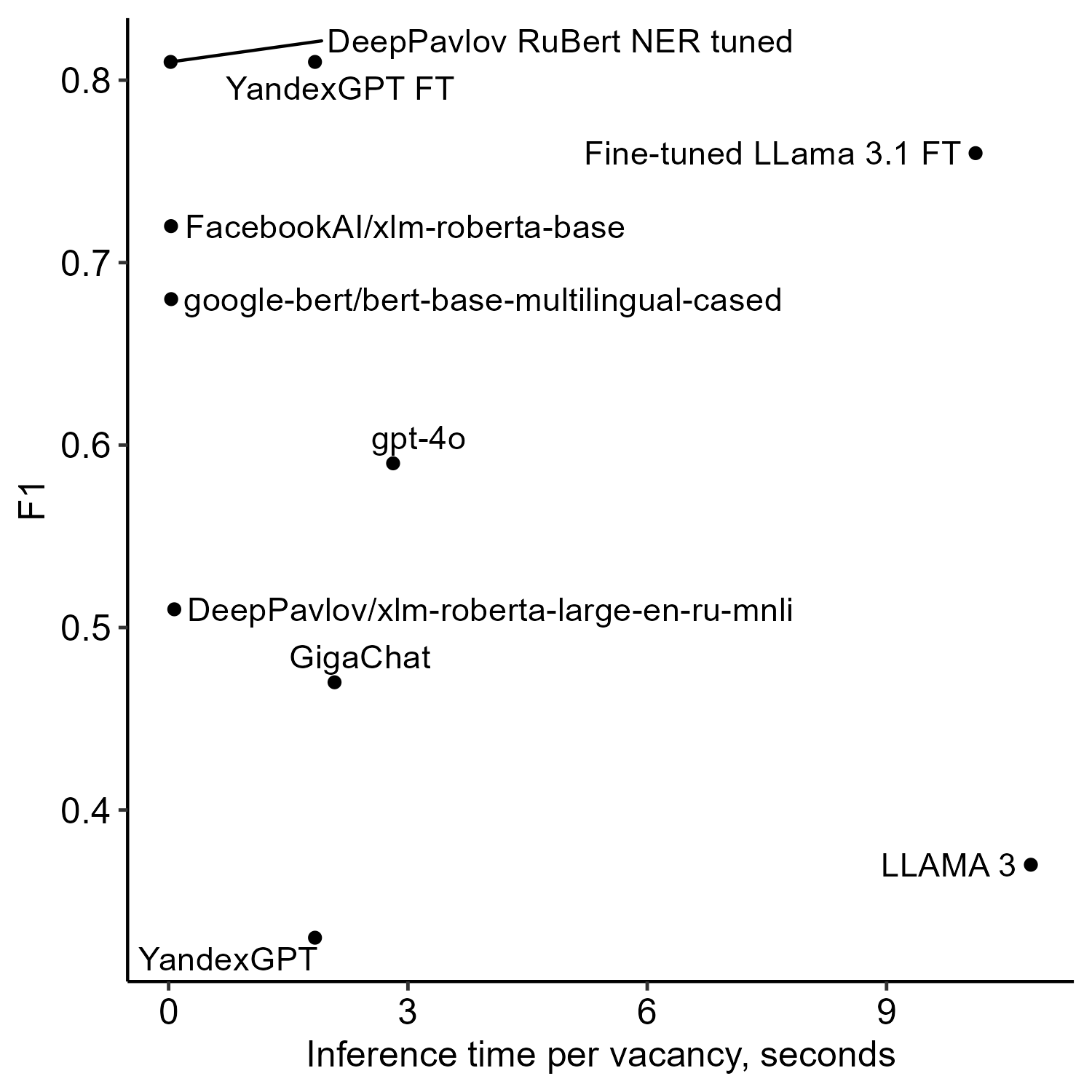
- 实验结果表明,经过调整的DeepPavlov RuBERT NER等传统NER模型在各项指标上优于LLM,更适合技能提取。
📝 摘要(中文)
劳动力市场正经历快速变化,对求职者的要求不断提高,职位空缺激增。从职位描述中识别关键技能和能力具有挑战性,因为雇主的要求各不相同,并且常常遗漏关键技能。本研究通过比较基于Encoder的传统命名实体识别(NER)方法与大型语言模型(LLM)在从俄语职位空缺中提取技能方面的性能来应对这些挑战。使用包含4000个职位空缺的标记数据集进行训练,1472个进行测试,评估了两种方法的性能。结果表明,传统的NER模型,特别是经过调整的DeepPavlov RuBERT NER,在准确率、精确率、召回率和推理时间等各种指标上均优于LLM。研究结果表明,传统的NER模型为技能提取提供了更有效和高效的解决方案,提高了职位要求的清晰度,并帮助求职者使其资格与雇主的期望相符。这项研究为自然语言处理(NLP)领域及其在劳动力市场中的应用做出了贡献,尤其是在非英语环境中。
🔬 方法详解
问题定义:论文旨在解决从俄语招聘信息中准确高效地提取技能这一问题。现有方法,特别是直接应用大型语言模型(LLM),在处理特定领域(如招聘信息)的技能提取任务时,可能存在准确率不高、推理时间较长等问题,难以满足实际应用的需求。
核心思路:论文的核心思路是对比传统的基于Encoder的命名实体识别(NER)模型与大型语言模型(LLM)在技能提取任务中的性能。通过实验评估,确定哪种方法更适合俄语招聘信息的技能提取,并为实际应用提供参考。
技术框架:整体框架包括以下几个主要步骤:1) 构建和标注俄语招聘信息数据集;2) 选择和训练基于Encoder的NER模型(如DeepPavlov RuBERT NER)和LLM;3) 使用测试集评估两种模型的性能,包括准确率、精确率、召回率和推理时间;4) 对比分析实验结果,得出结论。
关键创新:该研究的关键创新在于对传统NER模型和LLM在俄语招聘信息技能提取任务上的直接比较。虽然LLM在许多NLP任务中表现出色,但该研究表明,针对特定领域和语言,经过良好训练的传统NER模型可能更有效。
关键设计:论文的关键设计包括:1) 使用高质量的俄语招聘信息数据集进行训练和测试;2) 选择DeepPavlov RuBERT NER作为代表性的基于Encoder的NER模型,并进行针对性调优;3) 采用标准的NER评估指标(准确率、精确率、召回率)和推理时间作为性能评估标准;4) 对比不同模型的性能,并进行统计显著性分析(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过调整的DeepPavlov RuBERT NER模型在准确率、精确率、召回率和推理时间等各项指标上均优于LLM。具体性能数据(如F1-score)和提升幅度未在摘要中明确给出,但整体趋势表明传统NER模型在俄语招聘信息技能提取任务中更具优势。
🎯 应用场景
该研究成果可应用于招聘平台、人力资源管理系统等领域,帮助企业更准确地分析职位需求,提高招聘效率;同时,也能帮助求职者更好地了解市场需求,提升求职竞争力。未来,该方法可以扩展到其他语言和领域,例如教育、医疗等,具有广阔的应用前景。
📄 摘要(原文)
The labor market is undergoing rapid changes, with increasing demands on job seekers and a surge in job openings. Identifying essential skills and competencies from job descriptions is challenging due to varying employer requirements and the omission of key skills. This study addresses these challenges by comparing traditional Named Entity Recognition (NER) methods based on encoders with Large Language Models (LLMs) for extracting skills from Russian job vacancies. Using a labeled dataset of 4,000 job vacancies for training and 1,472 for testing, the performance of both approaches is evaluated. Results indicate that traditional NER models, especially DeepPavlov RuBERT NER tuned, outperform LLMs across various metrics including accuracy, precision, recall, and inference time. The findings suggest that traditional NER models provide more effective and efficient solutions for skill extraction, enhancing job requirement clarity and aiding job seekers in aligning their qualifications with employer expectations. This research contributes to the field of natural language processing (NLP) and its application in the labor market, particularly in non-English contexts.