Towards Effective and Efficient Continual Pre-training of Large Language Models
作者: Jie Chen, Zhipeng Chen, Jiapeng Wang, Kun Zhou, Yutao Zhu, Jinhao Jiang, Yingqian Min, Wayne Xin Zhao, Zhicheng Dou, Jiaxin Mao, Yankai Lin, Ruihua Song, Jun Xu, Xu Chen, Rui Yan, Zhewei Wei, Di Hu, Wenbing Huang, Ji-Rong Wen
分类: cs.CL
发布日期: 2024-07-26
备注: 16 pages, 10 figures, 16 tables
🔗 代码/项目: GITHUB
💡 一句话要点
Llama-3持续预训练:增强中文能力与科学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续预训练 大语言模型 Llama-3 科学推理 数据合成 课程学习 中文能力 领域自适应
📋 核心要点
- 现有持续预训练方法在特定领域或任务上微调大语言模型时,难以兼顾新能力提升和原有能力保持。
- 本文通过设计特定的数据混合和课程策略,并合成高质量数据集,在持续预训练过程中增强模型的新能力并保留原有能力。
- 实验结果表明,该方法在通用能力和科学推理能力上均有显著提升,且未损害原有能力,具有良好的性能表现。
📝 摘要(中文)
本文提出了一种针对Llama-3(8B)的持续预训练(CPT)技术报告,旨在显著提升该模型在中文语言能力和科学推理方面的表现。为了在增强新能力的同时保留原有能力,我们设计了特定的数据混合和课程策略,利用现有数据集并合成高质量数据集。具体而言,我们基于相关网页合成了多学科的科学问答(QA)对,并将这些合成数据纳入训练,以提高Llama-3的科学推理能力。我们将经过CPT后的模型称为Llama-3-SynE(Synthetic data Enhanced Llama-3)。此外,我们还使用相对较小的模型TinyLlama进行了调优实验,并将获得的发现应用于骨干模型的训练。在多个评估基准上的大量实验表明,我们的方法可以大幅提高骨干模型的性能,包括通用能力(C-Eval +8.81,CMMLU +6.31)和科学推理能力(MATH +12.00,SciEval +4.13),同时不损害其原有能力。我们的模型、数据和代码已在https://github.com/RUC-GSAI/Llama-3-SynE上提供。
🔬 方法详解
问题定义:本文旨在解决如何有效地对Llama-3等大型语言模型进行持续预训练,使其在特定领域(如中文和科学推理)的能力得到显著提升,同时避免遗忘模型原有的通用能力。现有方法在持续预训练过程中,往往难以平衡新能力的获取和原有能力的保持,容易出现灾难性遗忘等问题。
核心思路:本文的核心思路是通过精心设计的数据混合策略和课程学习策略,以及合成高质量的特定领域数据,来引导模型在持续预训练过程中学习新的知识和技能,同时避免对原有知识的过度干扰。通过小模型的实验结果指导大模型的训练,提升训练效率。
技术框架:整体框架包括以下几个主要阶段:1) 数据准备:收集现有数据集,并基于相关网页合成多学科科学问答对;2) 数据混合:设计特定的数据混合比例,平衡通用数据和特定领域数据;3) 课程学习:采用课程学习策略,逐步增加训练难度,引导模型学习;4) 模型训练:使用Llama-3作为骨干模型,进行持续预训练;5) 模型评估:在多个评估基准上评估模型的性能。
关键创新:本文的关键创新在于:1) 提出了针对Llama-3的持续预训练方法,并开源了模型、数据和代码;2) 设计了特定的数据混合和课程策略,有效平衡了新能力获取和原有能力保持;3) 合成了高质量的多学科科学问答对,显著提升了模型的科学推理能力。
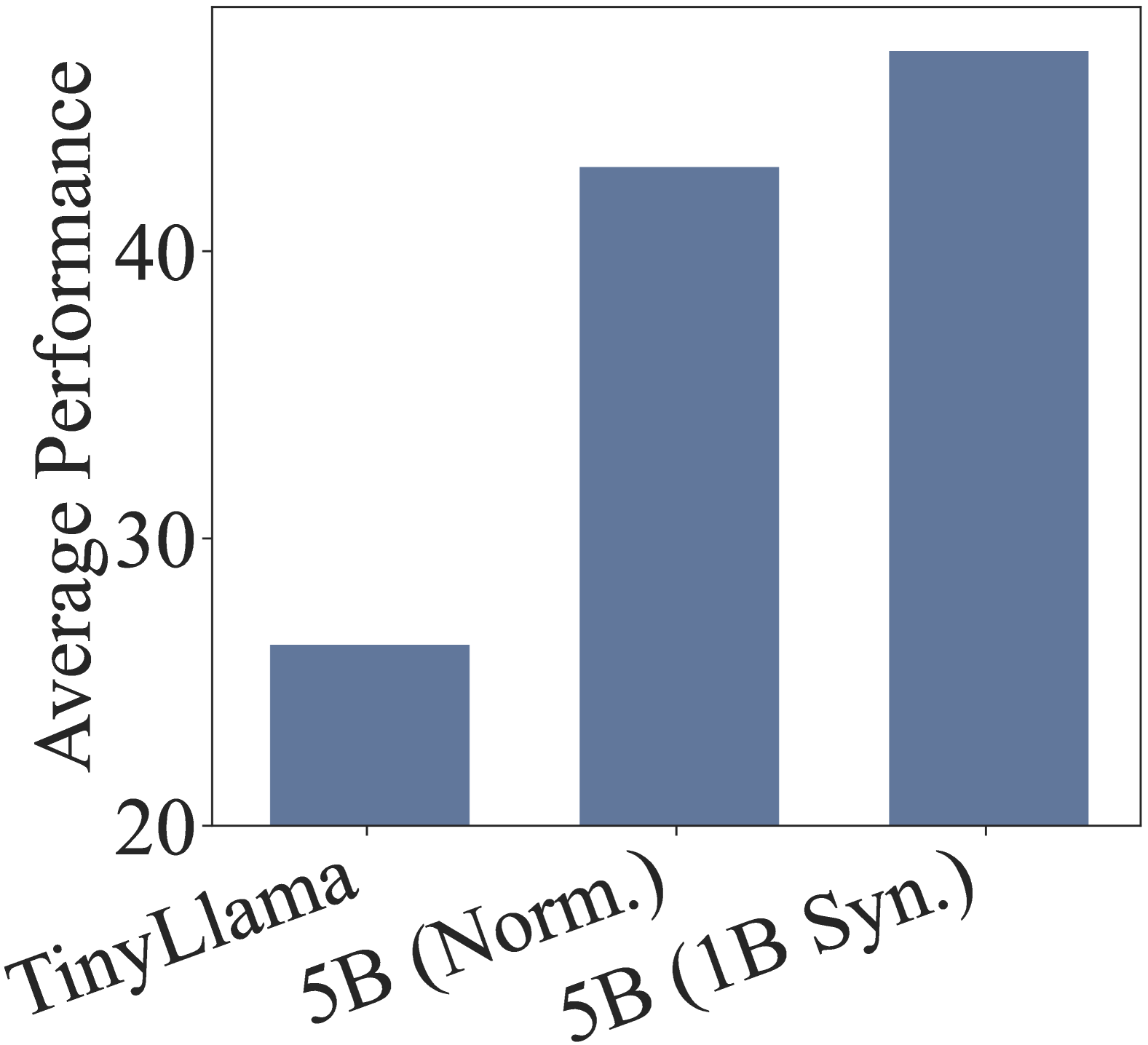
关键设计:数据混合比例的设计需要根据不同数据集的特点和模型的需求进行调整。课程学习策略可以采用由易到难的方式,例如先使用通用数据进行预热,再逐步增加特定领域数据的比例。损失函数可以使用标准的交叉熵损失函数,也可以根据具体任务进行调整。在TinyLlama上的实验结果,可以指导Llama-3的训练,例如学习率、batch size等超参数的设置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Llama-3-SynE在通用能力和科学推理能力上均有显著提升。在C-Eval上提升了8.81,在CMMLU上提升了6.31,在MATH上提升了12.00,在SciEval上提升了4.13。这些结果表明,该方法可以在不损害原有能力的前提下,有效提升模型的特定领域能力。
🎯 应用场景
该研究成果可应用于各种需要特定领域知识的大语言模型应用场景,例如智能客服、教育辅导、科研助手等。通过持续预训练,可以使模型更好地适应特定领域的需求,提供更准确、更专业的服务。未来,该方法可以推广到其他大型语言模型和领域,进一步提升模型的通用性和专业性。
📄 摘要(原文)
Continual pre-training (CPT) has been an important approach for adapting language models to specific domains or tasks. To make the CPT approach more traceable, this paper presents a technical report for continually pre-training Llama-3 (8B), which significantly enhances the Chinese language ability and scientific reasoning ability of the backbone model. To enhance the new abilities while retaining the original abilities, we design specific data mixture and curriculum strategies by utilizing existing datasets and synthesizing high-quality datasets. Specifically, we synthesize multidisciplinary scientific question and answer (QA) pairs based on related web pages, and subsequently incorporate these synthetic data to improve the scientific reasoning ability of Llama-3. We refer to the model after CPT as Llama-3-SynE (Synthetic data Enhanced Llama-3). We also present the tuning experiments with a relatively small model -- TinyLlama, and employ the derived findings to train the backbone model. Extensive experiments on a number of evaluation benchmarks show that our approach can largely improve the performance of the backbone models, including both the general abilities (+8.81 on C-Eval and +6.31 on CMMLU) and the scientific reasoning abilities (+12.00 on MATH and +4.13 on SciEval), without hurting the original capacities. Our model, data, and codes are available at https://github.com/RUC-GSAI/Llama-3-SynE.