A Universal Prompting Strategy for Extracting Process Model Information from Natural Language Text using Large Language Models
作者: Julian Neuberger, Lars Ackermann, Han van der Aa, Stefan Jablonski
分类: cs.CL, cs.AI
发布日期: 2024-07-26
💡 一句话要点
提出一种通用提示策略,利用大型语言模型从自然语言文本中提取流程模型信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 流程模型提取 自然语言处理 提示工程 信息提取
📋 核心要点
- 现有流程信息提取方法依赖规则和机器学习,面临数据稀缺挑战,限制了深度学习的应用。
- 提出一种通用提示策略,利用大型语言模型直接从文本中提取流程元素和关系。
- 实验表明,该策略在多个LLM上优于现有机器学习方法,F1分数提升高达8%。
📝 摘要(中文)
过去十年,大量研究致力于从文本流程描述中提取信息。尽管自然语言处理(NLP)取得了显著进展,但业务流程管理领域的信息提取仍然主要依赖于基于规则的系统和机器学习方法。数据稀缺性阻碍了深度学习技术的成功应用。然而,生成式大型语言模型(LLM)的快速发展使得无需大量数据即可高质量地解决许多NLP任务成为可能。因此,我们系统地研究了LLM在从文本流程描述中提取信息方面的潜力,目标是检测流程元素(如活动和参与者)以及它们之间的关系。通过启发式算法,我们证明了提取的信息适用于流程模型生成。基于一种新颖的提示策略,我们表明LLM能够超越最先进的机器学习方法,在三个不同的数据集上实现了高达8%的$F_1$分数绝对性能提升。我们在八个不同的LLM上评估了我们的提示策略,表明它具有普遍适用性,同时分析了提示的某些部分对提取质量的影响。示例文本的数量、定义的具体性和格式指令的严格性被认为是提高提取信息准确性的关键。我们的代码、提示和数据已公开。
🔬 方法详解
问题定义:论文旨在解决从自然语言文本描述中自动提取业务流程模型信息的问题。现有方法,如基于规则的系统和传统机器学习方法,在处理复杂和多样化的文本描述时表现不足,并且需要大量标注数据。数据稀缺是制约深度学习方法应用的关键痛点。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的生成能力和对自然语言的理解能力,通过精心设计的提示(prompting)策略,引导LLM直接从文本中提取流程模型所需的关键信息,例如活动、参与者以及它们之间的关系。这种方法避免了对大量标注数据的依赖,并能够处理更复杂的文本描述。
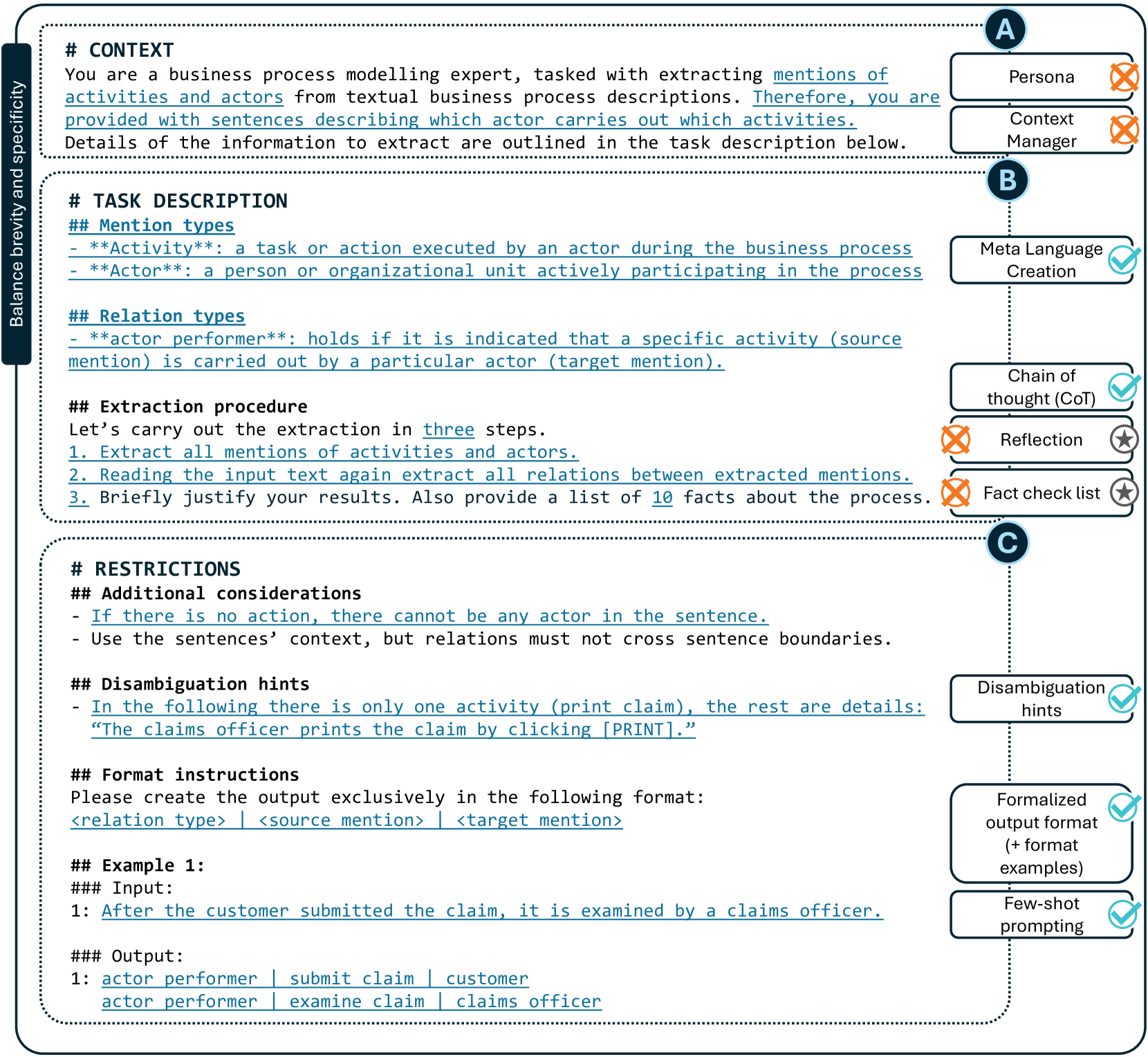
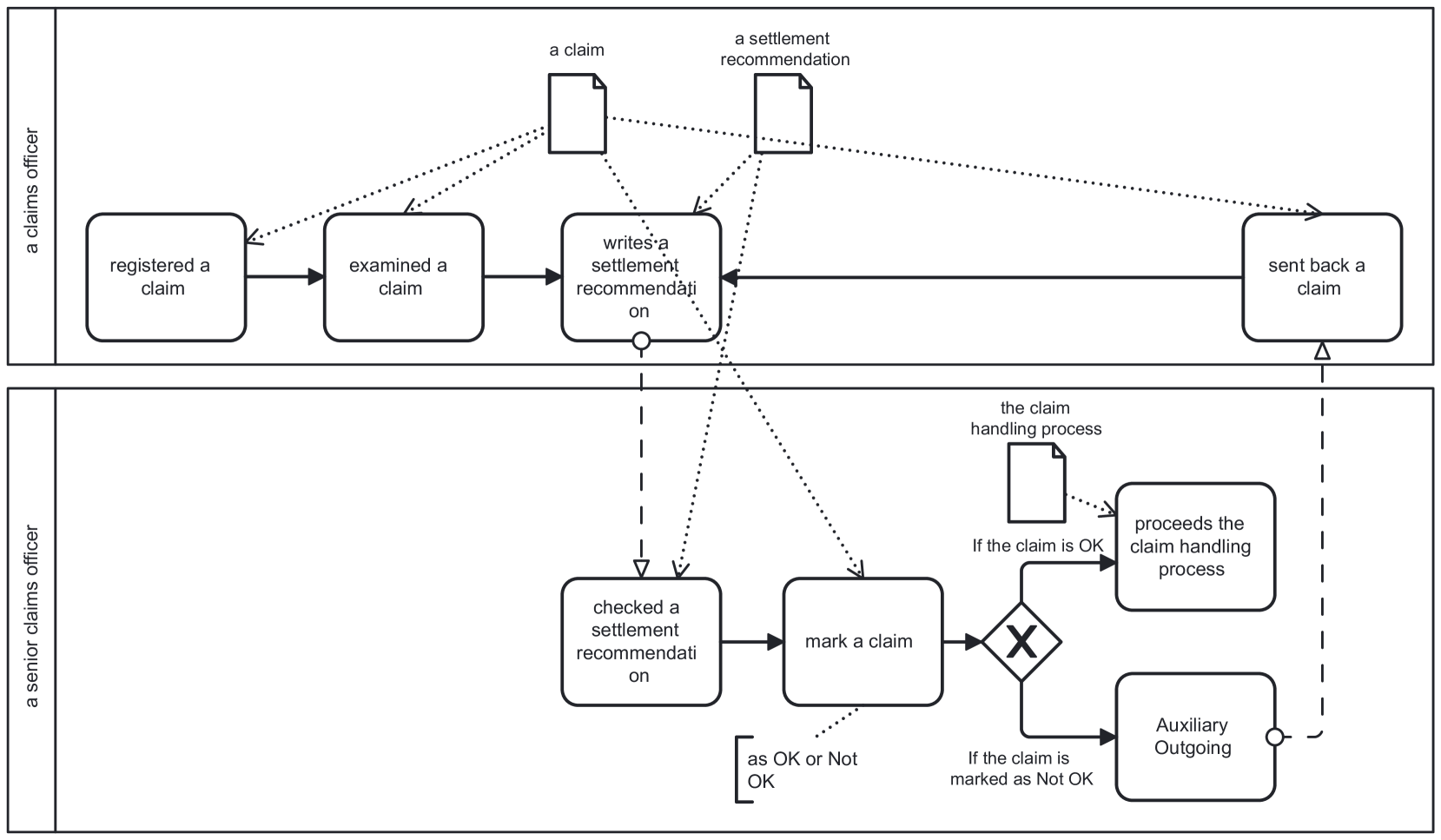
技术框架:该方法的核心是提示工程。首先,构建包含任务定义、格式要求和少量示例的提示。然后,将包含流程描述的文本输入到LLM中,LLM根据提示生成包含提取信息的结构化输出。最后,使用启发式算法将提取的信息转换为流程模型。整个流程包括:1. 提示构建;2. LLM推理;3. 流程模型生成。
关键创新:该论文的关键创新在于提出了一种通用的提示策略,该策略能够有效地引导不同的LLM从自然语言文本中提取流程模型信息。这种策略的关键在于提示的设计,包括任务定义、格式要求和示例的选择。该方法避免了传统机器学习方法对大量标注数据的依赖,并且能够处理更复杂的文本描述。
关键设计:提示的设计是关键。论文强调了以下几个关键设计:1. 示例文本的数量:更多的示例可以帮助LLM更好地理解任务;2. 定义的具体性:清晰明确的任务定义可以减少LLM的歧义;3. 格式指令的严格性:严格的格式指令可以确保LLM生成结构化的输出。此外,论文还探索了不同的LLM对提示的敏感性,并分析了不同提示部分对提取质量的影响。没有提及具体的损失函数或网络结构,因为该方法直接利用了预训练的LLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该提示策略在八个不同的LLM上均有效,并且在三个不同的数据集上优于最先进的机器学习方法,F1分数提升高达8%。实验还分析了提示的各个部分对提取质量的影响,发现示例文本的数量、定义的具体性和格式指令的严格性是提高提取信息准确性的关键因素。
🎯 应用场景
该研究成果可应用于业务流程自动化、流程挖掘和流程改进等领域。通过自动从文档中提取流程模型,可以加速流程建模过程,降低建模成本,并提高流程模型的准确性。此外,该方法还可以用于分析大量的文本数据,以发现潜在的流程改进机会。
📄 摘要(原文)
Over the past decade, extensive research efforts have been dedicated to the extraction of information from textual process descriptions. Despite the remarkable progress witnessed in natural language processing (NLP), information extraction within the Business Process Management domain remains predominantly reliant on rule-based systems and machine learning methodologies. Data scarcity has so far prevented the successful application of deep learning techniques. However, the rapid progress in generative large language models (LLMs) makes it possible to solve many NLP tasks with very high quality without the need for extensive data. Therefore, we systematically investigate the potential of LLMs for extracting information from textual process descriptions, targeting the detection of process elements such as activities and actors, and relations between them. Using a heuristic algorithm, we demonstrate the suitability of the extracted information for process model generation. Based on a novel prompting strategy, we show that LLMs are able to outperform state-of-the-art machine learning approaches with absolute performance improvements of up to 8\% $F_1$ score across three different datasets. We evaluate our prompting strategy on eight different LLMs, showing it is universally applicable, while also analyzing the impact of certain prompt parts on extraction quality. The number of example texts, the specificity of definitions, and the rigour of format instructions are identified as key for improving the accuracy of extracted information. Our code, prompts, and data are publicly available.