Fairness Definitions in Language Models Explained
作者: Zhipeng Yin, Zichong Wang, Avash Palikhe, Wenbin Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-07-26 (更新: 2026-01-15)
DOI: 10.1002/widm.70063
🔗 代码/项目: GITHUB
💡 一句话要点
针对语言模型公平性定义进行系统性综述,并提出基于Transformer架构的新分类方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 公平性 Transformer 偏见 自然语言处理
📋 核心要点
- 语言模型存在继承和放大社会偏见的风险,阻碍了其在实际应用中的部署,因此需要关注模型公平性。
- 论文提出了一种系统性的综述,对语言模型中的公平性定义进行梳理和分类,并基于Transformer架构提出了新的分类方法。
- 论文通过实验展示了各种公平性定义的实际意义和结果,并讨论了当前的研究挑战和未解决的问题。
📝 摘要(中文)
语言模型(LMs)在各种自然语言处理(NLP)任务中表现出卓越的性能。尽管取得了这些进步,但LMs可能会继承和放大与性别和种族等敏感属性相关的社会偏见,从而限制了它们在实际应用中的采用。因此,公平性在LMs中得到了广泛的探索,从而提出了各种公平性概念。然而,对于在特定上下文中应用哪种公平性定义缺乏明确的共识,并且理解这些定义之间的区别的复杂性可能会造成混淆并阻碍进一步的进展。为此,本文提出了一项系统性调查,阐明了公平性定义在LMs中的应用。具体来说,我们首先简要介绍LMs和LMs中的公平性,然后全面、最新地概述LMs中现有的公平性概念,并介绍一种新的分类法,该分类法根据其Transformer架构对这些概念进行分类:仅编码器、仅解码器和编码器-解码器LMs。我们通过实验进一步说明每个定义,展示它们的实际意义和结果。最后,我们讨论了当前的研究挑战和未解决的问题,旨在培养创新思想并推动该领域的发展。该存储库可在https://github.com/vanbanTruong/Fairness-in-Large-Language-Models/tree/main/definitions上公开获得。
🔬 方法详解
问题定义:现有语言模型在各种NLP任务中表现出色,但会继承和放大社会偏见,例如性别和种族歧视,导致实际应用受限。现有研究提出了多种公平性定义,但缺乏明确的共识和区分,导致研究人员难以选择和应用,阻碍了该领域的发展。
核心思路:论文的核心思路是对现有语言模型中的公平性定义进行系统性梳理和分类,并基于Transformer架构(encoder-only, decoder-only, encoder-decoder)提出一种新的分类方法。通过清晰的定义和分类,帮助研究人员更好地理解和选择合适的公平性定义。
技术框架:论文首先简要介绍了语言模型和语言模型中的公平性问题。然后,对现有的公平性定义进行了全面概述,并提出了基于Transformer架构的分类方法。接着,通过实验说明了每个定义的实际意义和结果。最后,讨论了当前的研究挑战和未解决的问题。整体框架为:问题引入 -> 文献综述与分类 -> 实验验证 -> 未来展望。
关键创新:论文的关键创新在于提出了基于Transformer架构的公平性定义分类方法。这种分类方法能够更好地反映不同类型语言模型的特点,并帮助研究人员根据具体的模型架构选择合适的公平性定义。此外,该论文还对现有的公平性定义进行了系统性的梳理和总结,为该领域的研究提供了重要的参考。
关键设计:论文的关键设计在于如何将现有的公平性定义映射到不同的Transformer架构上。具体来说,论文分析了encoder-only、decoder-only和encoder-decoder三种架构的特点,并针对每种架构,选择了合适的公平性定义进行实验验证。论文并未涉及新的损失函数或网络结构设计,而是侧重于对现有方法的整理和归纳。
🖼️ 关键图片
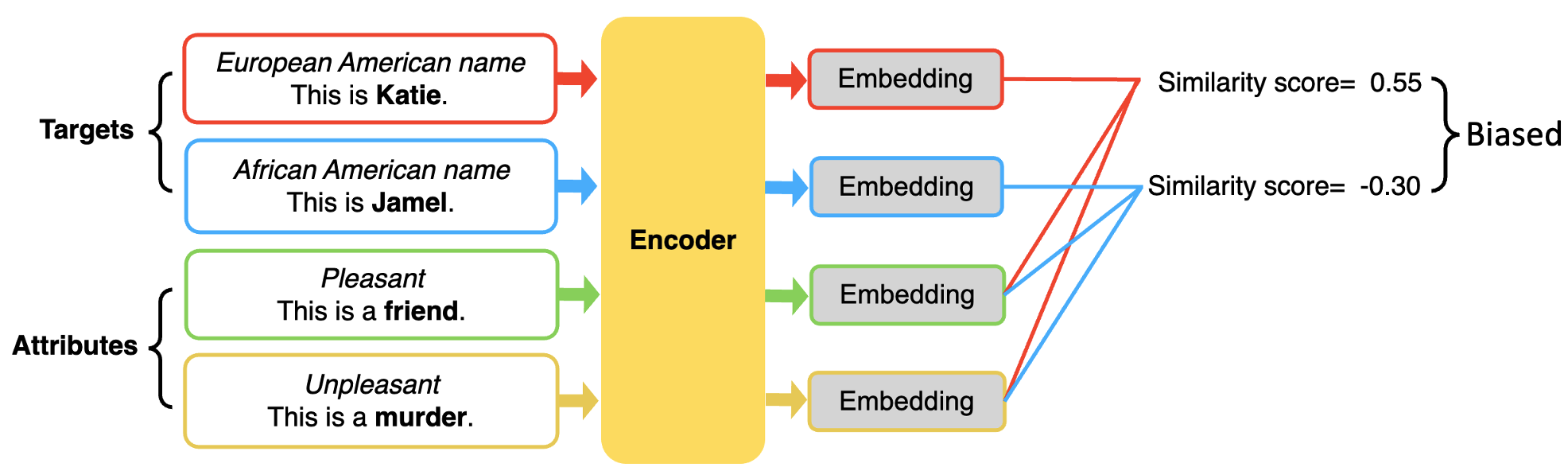
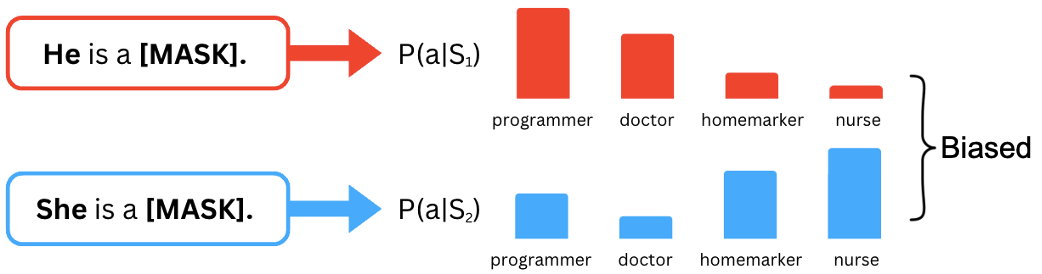
📊 实验亮点
论文通过实验展示了不同公平性定义在不同Transformer架构上的实际效果,例如在encoder-only模型上,某些公平性定义可能更有效;而在decoder-only模型上,另一些定义可能更适用。这些实验结果为研究人员选择合适的公平性定义提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务中,例如文本生成、情感分析、机器翻译等,以提高模型的公平性和减少偏见。该研究有助于推动语言模型在公平性方面的研究进展,并促进其在更广泛的实际应用中的部署,例如招聘、信贷评估等。
📄 摘要(原文)
Language Models (LMs) have demonstrated exceptional performance across various Natural Language Processing (NLP) tasks. Despite these advancements, LMs can inherit and amplify societal biases related to sensitive attributes such as gender and race, limiting their adoption in real-world applications. Therefore, fairness has been extensively explored in LMs, leading to the proposal of various fairness notions. However, the lack of clear agreement on which fairness definition to apply in specific contexts and the complexity of understanding the distinctions between these definitions can create confusion and impede further progress. To this end, this paper proposes a systematic survey that clarifies the definitions of fairness as they apply to LMs. Specifically, we begin with a brief introduction to LMs and fairness in LMs, followed by a comprehensive, up-to-date overview of existing fairness notions in LMs and the introduction of a novel taxonomy that categorizes these concepts based on their transformer architecture: encoder-only, decoder-only, and encoder-decoder LMs. We further illustrate each definition through experiments, showcasing their practical implications and outcomes. Finally, we discuss current research challenges and open questions, aiming to foster innovative ideas and advance the field. The repository is publicly available online at https://github.com/vanbanTruong/Fairness-in-Large-Language-Models/tree/main/definitions.