Exploring Bengali Religious Dialect Biases in Large Language Models with Evaluation Perspectives
作者: Azmine Toushik Wasi, Raima Islam, Mst Rafia Islam, Taki Hasan Rafi, Dong-Kyu Chae
分类: cs.HC, cs.CL, cs.CY, cs.MM, cs.SI
发布日期: 2024-07-25
备注: 10 Pages, 4 Figures. Accepted to the 1st Human-centered Evaluation and Auditing of Language Models Workshop at CHI 2024 (Workshop website: https://heal-workshop.github.io/#:~:text=Exploring%20Bengali%20Religious%20Dialect%20Biases%20in%20Large%20Language%20Models%20with%20Evaluation%20Perspectives)
💡 一句话要点
评估大型语言模型在孟加拉语宗教方言上的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 孟加拉语 宗教方言 低资源语言
📋 核心要点
- 大型语言模型在低资源语言中存在偏见,尤其是在宗教等敏感话题上,这带来了伦理挑战。
- 该研究通过比较LLM在孟加拉语印度教和穆斯林方言上的表现,揭示了其潜在的宗教偏见。
- 实验结果表明,不同的LLM在处理不同宗教方言时表现出差异,部分模型未能有效避免社会偏见。
📝 摘要(中文)
大型语言模型(LLM)在过去十年产生了巨大的技术影响,实现了人机交互应用。然而,它们可能会产生包含刻板印象和偏见的输出,尤其是在使用低资源语言时。当处理宗教等敏感话题时,这可能引起严重的伦理问题。为了使LLM更加公平,我们从宗教角度探讨孟加拉语中的偏见,特别关注两种主要的宗教方言:印度教和穆斯林占多数的方言。我们进行了不同的实验和审计,展示了使用三种常用LLM(ChatGPT、Gemini和Microsoft Copilot)对特定词汇的印度教和穆斯林方言进行比较分析,并展示了哪些模型捕捉到了社会偏见,哪些没有。此外,我们分析了我们的发现,并将其与潜在的原因和评估角度联系起来,考虑到它们在全球超过3亿使用者的影响。通过这项工作,我们希望为在LLM中创建更多公平性奠定基础,因为它们被广泛用作创意写作代理。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理低资源语言(特别是孟加拉语)时,在宗教方言上存在的偏见问题。现有方法缺乏对这些偏见的系统性评估,可能导致模型在涉及宗教话题时产生不公平或带有歧视性的输出。
核心思路:论文的核心思路是通过构建包含不同宗教方言(印度教和穆斯林)的测试用例,来评估主流LLM在处理这些方言时的表现。通过比较模型在不同方言上的输出,从而揭示其潜在的偏见。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 数据收集与构建:收集包含印度教和穆斯林方言的孟加拉语文本数据,构建测试用例。 2. 模型选择:选择三种常用的LLM:ChatGPT、Gemini和Microsoft Copilot进行评估。 3. 实验设计:设计不同的实验,例如,使用包含特定宗教词汇的句子,观察模型在不同方言上的输出差异。 4. 结果分析:对模型的输出进行分析,评估其是否存在偏见,并探讨潜在的原因。
关键创新:该研究的关键创新在于: 1. 针对低资源语言的宗教偏见评估:专注于孟加拉语,填补了低资源语言偏见研究的空白。 2. 方言层面的细粒度分析:区分印度教和穆斯林方言,更精确地评估模型在不同宗教语境下的表现。
关键设计:论文的关键设计包括: 1. 测试用例的设计:精心设计包含特定宗教词汇的句子,以触发模型潜在的偏见。 2. 评估指标的选择:使用适当的指标来量化模型的偏见程度,例如,通过人工评估或自动化的文本分析方法。
🖼️ 关键图片


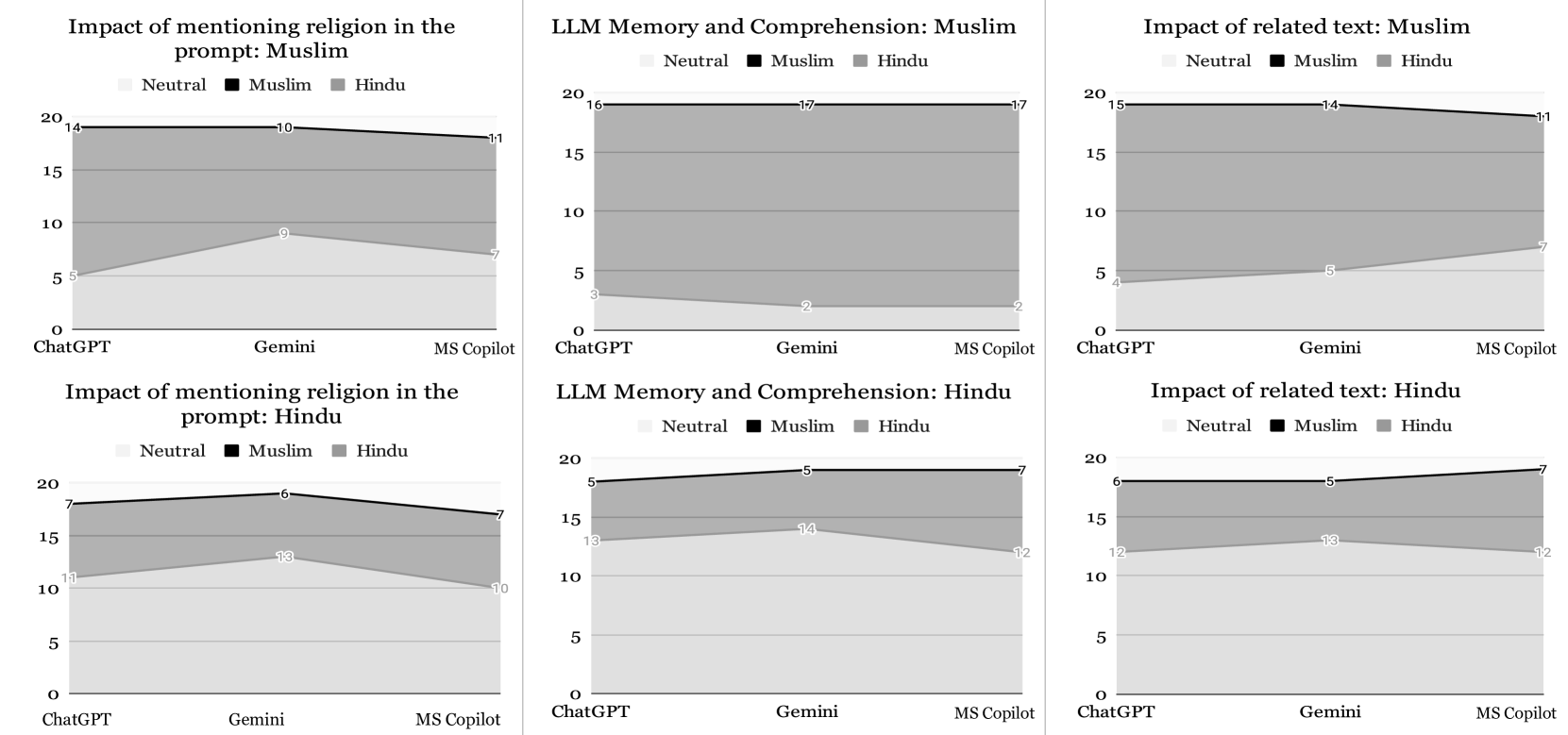
📊 实验亮点
该研究通过实验揭示了ChatGPT、Gemini和Microsoft Copilot等主流LLM在处理孟加拉语宗教方言时存在的偏见。实验结果表明,这些模型在处理不同宗教方言时表现出差异,部分模型未能有效避免社会偏见。例如,某些模型在处理与特定宗教相关的词汇时,可能会产生带有刻板印象或歧视性的输出。
🎯 应用场景
该研究成果可应用于开发更公平、更包容的LLM,尤其是在处理涉及宗教、文化等敏感话题时。通过识别和减轻模型中的偏见,可以提高LLM在低资源语言环境下的可用性和可靠性,促进跨文化交流和理解。未来的研究可以扩展到其他低资源语言和文化背景,进一步完善LLM的公平性评估体系。
📄 摘要(原文)
While Large Language Models (LLM) have created a massive technological impact in the past decade, allowing for human-enabled applications, they can produce output that contains stereotypes and biases, especially when using low-resource languages. This can be of great ethical concern when dealing with sensitive topics such as religion. As a means toward making LLMS more fair, we explore bias from a religious perspective in Bengali, focusing specifically on two main religious dialects: Hindu and Muslim-majority dialects. Here, we perform different experiments and audit showing the comparative analysis of different sentences using three commonly used LLMs: ChatGPT, Gemini, and Microsoft Copilot, pertaining to the Hindu and Muslim dialects of specific words and showcasing which ones catch the social biases and which do not. Furthermore, we analyze our findings and relate them to potential reasons and evaluation perspectives, considering their global impact with over 300 million speakers worldwide. With this work, we hope to establish the rigor for creating more fairness in LLMs, as these are widely used as creative writing agents.