Robust Claim Verification Through Fact Detection
作者: Nazanin Jafari, James Allan
分类: cs.CL, cs.AI
发布日期: 2024-07-25
💡 一句话要点
提出FactDetect,通过从证据中提取事实增强声明验证的鲁棒性和推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 声明验证 事实检测 大型语言模型 多任务学习 零样本学习
📋 核心要点
- 现有声明验证方法在处理复杂推理和证据理解方面存在不足,尤其是在科学领域。
- FactDetect的核心思想是从证据中提取简洁的事实性陈述,并利用这些事实来增强声明验证过程。
- 实验结果表明,FactDetect在监督和零样本声明验证中均取得了显著的性能提升,尤其是在科学数据集上。
📝 摘要(中文)
声明验证是一项具有挑战性的任务。本文提出了一种通过从证据中提取简短事实来增强自动声明验证的鲁棒性和推理能力的方法。我们提出的新方法FactDetect,利用大型语言模型(LLMs)从证据中生成简洁的事实陈述,并根据这些事实与声明和证据的语义相关性对其进行标记。然后将生成的事实与声明和证据相结合。为了训练轻量级的监督模型,我们将事实检测任务作为多任务方法整合到声明验证过程中,以提高性能和可解释性。我们还表明,在声明验证提示中增强FactDetect可以提高LLM在零样本声明验证中的性能。我们的方法在具有挑战性的科学声明验证数据集上评估时,在监督声明验证模型中表现出具有竞争力的结果,F1分数提高了15%。我们还证明了FactDetect可以与声明和证据一起增强,用于LLM中的零样本提示(AugFactDetect)以进行结论预测。我们表明,AugFactDetect在三个具有挑战性的科学声明验证数据集上,以统计学意义显著地优于基线,与表现最佳的基线相比,平均性能提升了17.3%。
🔬 方法详解
问题定义:论文旨在解决声明验证任务中,现有方法对复杂证据推理能力不足的问题。特别是在科学声明验证领域,证据通常包含大量的专业术语和复杂的逻辑关系,使得传统的声明验证方法难以有效提取关键信息并进行准确判断。现有方法的痛点在于缺乏对证据进行细粒度分析和推理的能力,导致验证结果的准确性和鲁棒性较低。
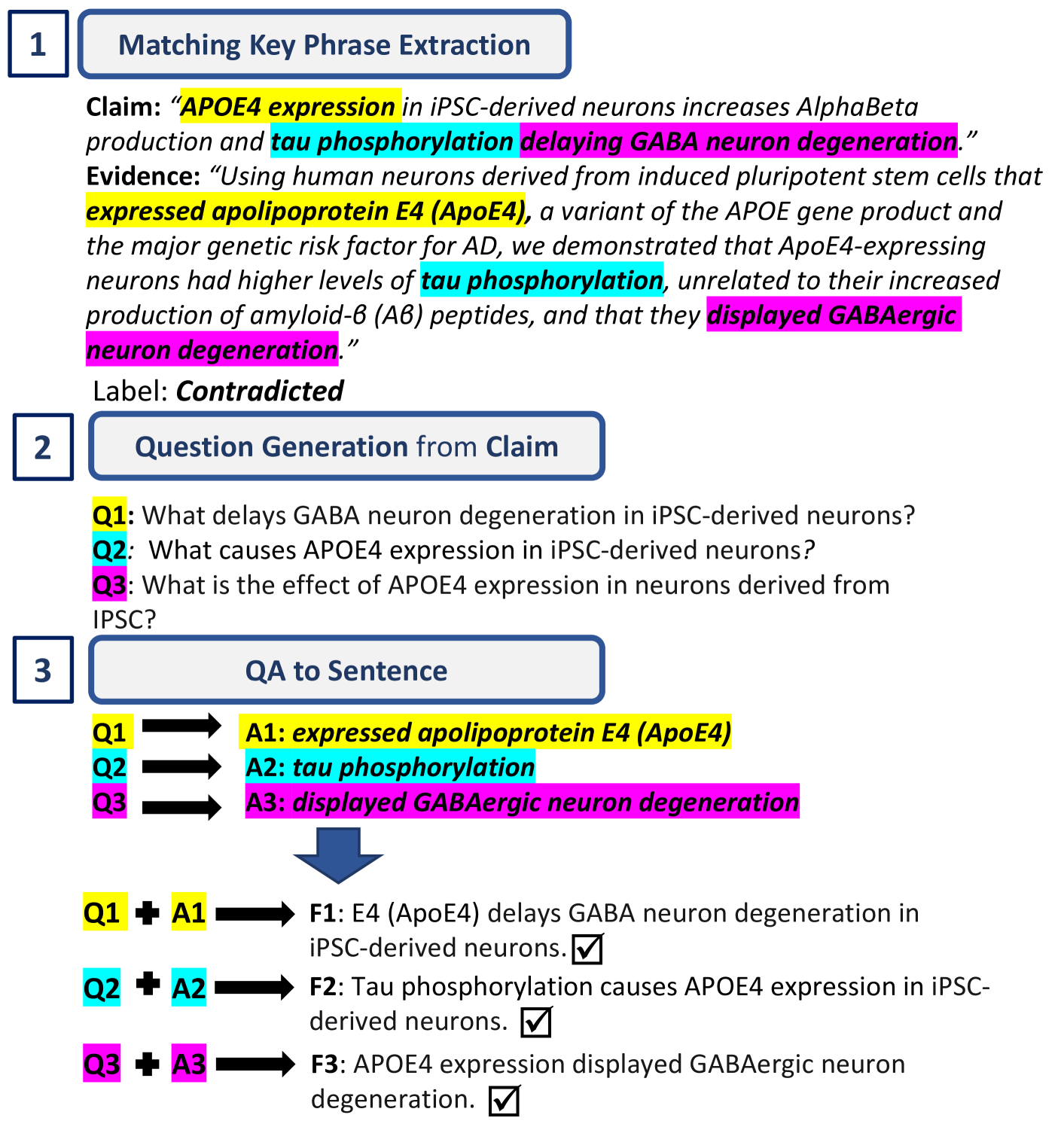
核心思路:论文的核心解决思路是引入“事实检测”这一中间步骤,通过从证据中提取简洁的事实性陈述,将复杂的证据信息分解为更易于理解和处理的单元。这样做的目的是增强模型对证据的理解能力,并提高声明验证的准确性和可解释性。通过将事实检测任务与声明验证任务相结合,可以实现多任务学习,从而提高模型的泛化能力。
技术框架:FactDetect的整体框架包含以下几个主要模块:1) 事实生成模块:利用大型语言模型(LLMs)从证据中生成简洁的事实陈述。2) 事实标注模块:根据生成的事实与声明和证据的语义相关性,对事实进行标注。3) 声明验证模块:将生成的事实与声明和证据相结合,输入到声明验证模型中进行判断。对于零样本场景,则将提取的事实添加到LLM的prompt中。
关键创新:论文的关键创新在于将事实检测任务融入到声明验证流程中,并提出了一种新的方法FactDetect。该方法通过从证据中提取事实,增强了模型对证据的理解能力,并提高了声明验证的准确性和可解释性。此外,论文还提出了一种基于FactDetect的零样本提示方法AugFactDetect,进一步提高了LLM在声明验证任务中的性能。
关键设计:在事实生成模块中,使用了大型语言模型(LLMs)进行事实提取,具体使用的LLM类型未知。事实标注模块根据事实与声明和证据的语义相关性进行标注,具体的标注策略未知。声明验证模块可以使用各种监督学习模型,论文中使用了轻量级的监督模型,具体模型结构未知。在零样本提示方法AugFactDetect中,如何将提取的事实融入到prompt中,以及prompt的具体形式未知。
🖼️ 关键图片


📊 实验亮点
FactDetect在监督声明验证模型中,F1分数提高了15%。AugFactDetect在三个具有挑战性的科学声明验证数据集上,与表现最佳的基线相比,平均性能提升了17.3%,且具有统计学意义。这些结果表明,FactDetect能够有效提高声明验证的准确性和鲁棒性,尤其是在处理复杂的科学证据时。
🎯 应用场景
该研究成果可应用于多个领域,包括新闻事实核查、科学文献验证、医疗诊断辅助等。通过自动提取和验证声明的事实依据,可以提高信息的可信度,减少虚假信息的传播,并为决策提供更可靠的支持。未来,该技术有望在智能客服、舆情分析等领域发挥更大的作用。
📄 摘要(原文)
Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.