Self-Training with Direct Preference Optimization Improves Chain-of-Thought Reasoning
作者: Tianduo Wang, Shichen Li, Wei Lu
分类: cs.CL
发布日期: 2024-07-25
备注: ACL 2024. Code and data are available at https://github.com/TianduoWang/DPO-ST
💡 一句话要点
提出基于直接偏好优化的自训练方法,提升小规模语言模型的思维链推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自训练 直接偏好优化 思维链推理 数学推理 语言模型 知识蒸馏 偏好学习
📋 核心要点
- 高质量的监督微调数据是训练语言模型进行数学推理的关键,但获取成本高昂。
- 论文提出结合直接偏好优化(DPO)的自训练方法,利用模型自身输出来提升推理能力。
- 实验表明,该方法在提升推理性能的同时,降低了对大型专有模型的依赖,更具性价比。
📝 摘要(中文)
本文提出了一种通过自训练来增强小规模语言模型推理能力的方法。该方法利用模型自身的输出来进行学习,并结合直接偏好优化(DPO)算法,通过偏好数据引导语言模型生成更准确和多样化的思维链推理过程。实验结果表明,该方法不仅提高了语言模型的推理性能,而且与依赖大型专有语言模型相比,提供了一种更具成本效益和可扩展性的解决方案。该方法在各种数学推理任务上进行了评估,并使用了不同的基础模型。
🔬 方法详解
问题定义:现有语言模型在数学推理任务中,需要高质量的监督微调数据。一种常见的替代方案是从大型语言模型中采样,但这种知识蒸馏方法成本高昂且不稳定,尤其是在依赖像GPT-4这样行为不可预测的闭源专有模型时。因此,如何以更经济有效的方式提升小规模语言模型的推理能力是一个关键问题。
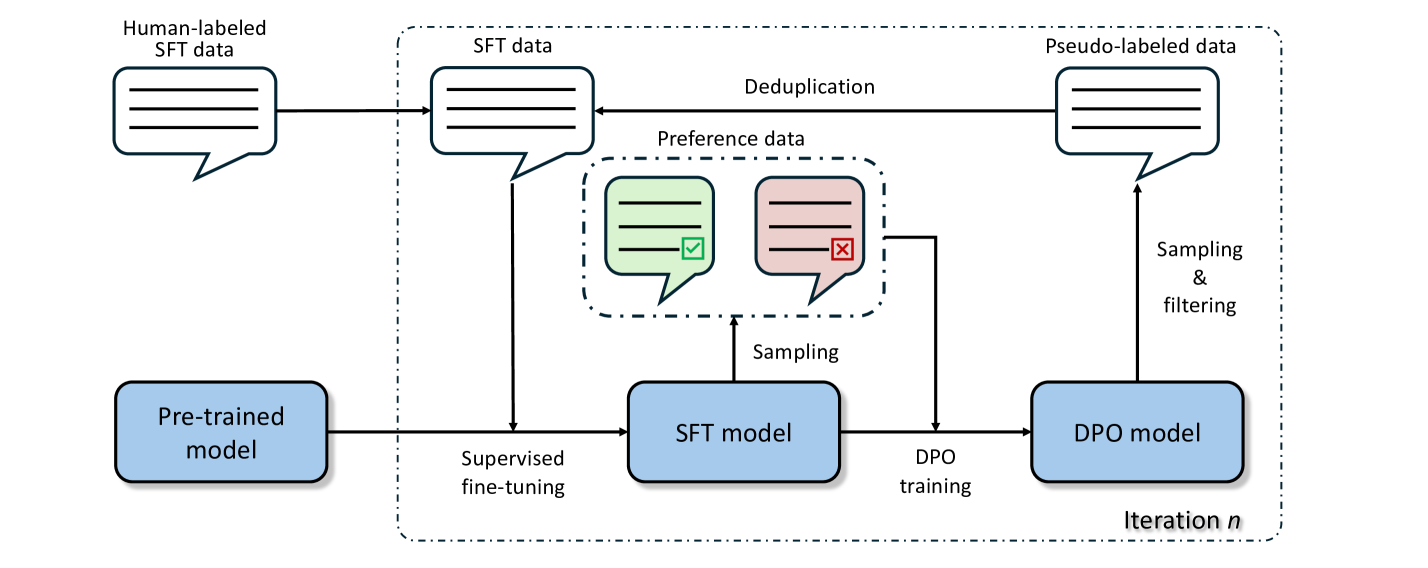
核心思路:论文的核心思路是通过自训练,让模型从自身的输出中学习,并结合直接偏好优化(DPO)算法,利用偏好数据来引导语言模型生成更准确和多样化的思维链推理过程。DPO算法能够直接优化语言模型的策略,使其更符合人类的偏好,从而提高推理的准确性。
技术框架:该方法主要包含两个阶段:首先,使用语言模型生成思维链推理过程的样本;然后,利用DPO算法,根据偏好数据(例如,正确答案的推理过程优于错误答案的推理过程)来优化语言模型。这个过程可以迭代进行,不断提升模型的推理能力。整体框架是一个自训练的循环,其中DPO作为关键的优化步骤。
关键创新:该方法最重要的创新点在于将直接偏好优化(DPO)算法融入到自训练过程中。传统的自训练方法通常只是简单地使用模型的输出来进行学习,而DPO的引入使得模型能够根据偏好数据进行更有效的学习,从而生成更准确和多样化的思维链推理过程。与现有方法的本质区别在于,它不是简单地模仿大型模型的输出,而是通过偏好学习来提升自身的推理能力。
关键设计:关键设计包括:1) 如何定义偏好数据:论文可能采用了基于答案正确性的偏好,即正确答案对应的推理过程被认为是更优的;2) DPO算法的具体实现:包括奖励函数的设计、优化器的选择等;3) 自训练的迭代次数和学习率等超参数的设置。这些参数的设置会直接影响到模型的最终性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,结合DPO的自训练方法能够显著提升小规模语言模型在数学推理任务上的性能。具体而言,该方法在多个数学推理数据集上都取得了优于传统自训练方法的结果,并且在某些情况下,甚至可以与大型专有模型相媲美,同时降低了训练成本。
🎯 应用场景
该研究成果可应用于各种需要数学推理能力的场景,例如自动答题系统、智能教育平台、金融分析等。通过降低对大型专有模型的依赖,该方法使得小规模语言模型也能在这些领域发挥重要作用,具有广泛的应用前景和实际价值。未来,该方法可以进一步扩展到其他类型的推理任务,例如常识推理、逻辑推理等。
📄 摘要(原文)
Effective training of language models (LMs) for mathematical reasoning tasks demands high-quality supervised fine-tuning data. Besides obtaining annotations from human experts, a common alternative is sampling from larger and more powerful LMs. However, this knowledge distillation approach can be costly and unstable, particularly when relying on closed-source, proprietary LMs like GPT-4, whose behaviors are often unpredictable. In this work, we demonstrate that the reasoning abilities of small-scale LMs can be enhanced through self-training, a process where models learn from their own outputs. We also show that the conventional self-training can be further augmented by a preference learning algorithm called Direct Preference Optimization (DPO). By integrating DPO into self-training, we leverage preference data to guide LMs towards more accurate and diverse chain-of-thought reasoning. We evaluate our method across various mathematical reasoning tasks using different base models. Our experiments show that this approach not only improves LMs' reasoning performance but also offers a more cost-effective and scalable solution compared to relying on large proprietary LMs.