Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic
作者: Fakhraddin Alwajih, Gagan Bhatia, Muhammad Abdul-Mageed
分类: cs.CL, cs.AI
发布日期: 2024-07-25 (更新: 2024-07-26)
💡 一句话要点
Dallah:一种面向阿拉伯语方言的多模态大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 阿拉伯语 方言识别 大型语言模型 图像描述 LLaMA-2 跨模态理解
📋 核心要点
- 现有多模态大语言模型主要集中在英语,缺乏对阿拉伯语等其他语言的支持,阻碍了相关应用的发展。
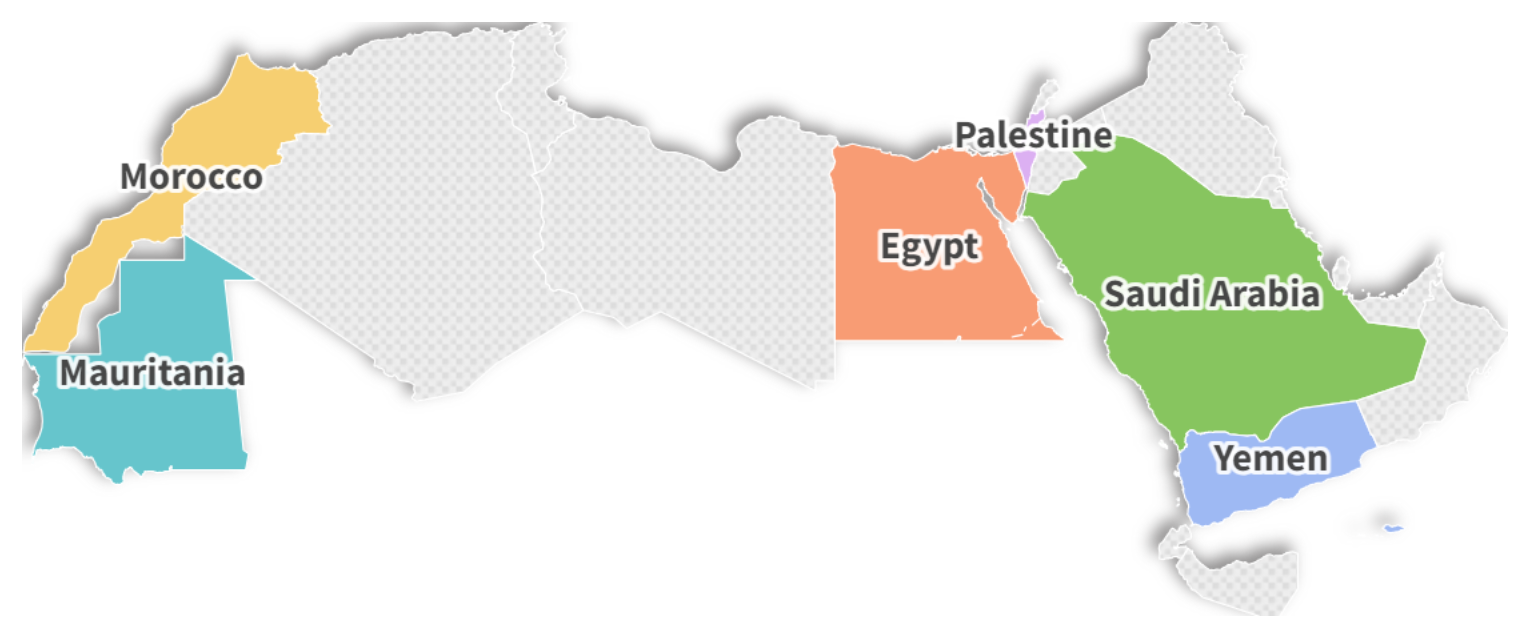
- Dallah模型基于LLaMA-2,通过微调六种阿拉伯语方言,实现了对包含文本和视觉元素的多模态方言交互的处理。
- Dallah在现代标准阿拉伯语和方言响应的基准测试中表现出色,为后续方言感知的阿拉伯语MLLM开发奠定基础。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在生成和理解图像到文本内容方面的能力取得了显著进展。然而,由于其他语言中高质量多模态资源的稀缺,这些进展主要局限于英语。这一限制阻碍了阿拉伯语等语言中具有竞争力的模型的发展。为了缓解这种情况,我们引入了一种高效的阿拉伯语多模态助手,名为Dallah,它利用基于LLaMA-2的先进语言模型来促进多模态交互。Dallah在阿拉伯语MLLM中展示了最先进的性能。通过微调六种阿拉伯语方言,Dallah展示了其处理包含文本和视觉元素的复杂方言交互的能力。该模型在两个基准测试中表现出色:一个评估其在现代标准阿拉伯语(MSA)上的性能,另一个专门设计用于评估方言响应。除了其在多模态交互任务中的强大性能外,Dallah还有可能为进一步开发方言感知的阿拉伯语MLLM铺平道路。
🔬 方法详解
问题定义:现有的大型多模态模型主要针对英语设计,缺乏对阿拉伯语,特别是其多种方言的支持。这限制了阿拉伯语用户使用多模态模型进行信息检索、内容创作等任务的能力。现有方法难以有效处理阿拉伯语的复杂语法和方言差异,导致性能下降。
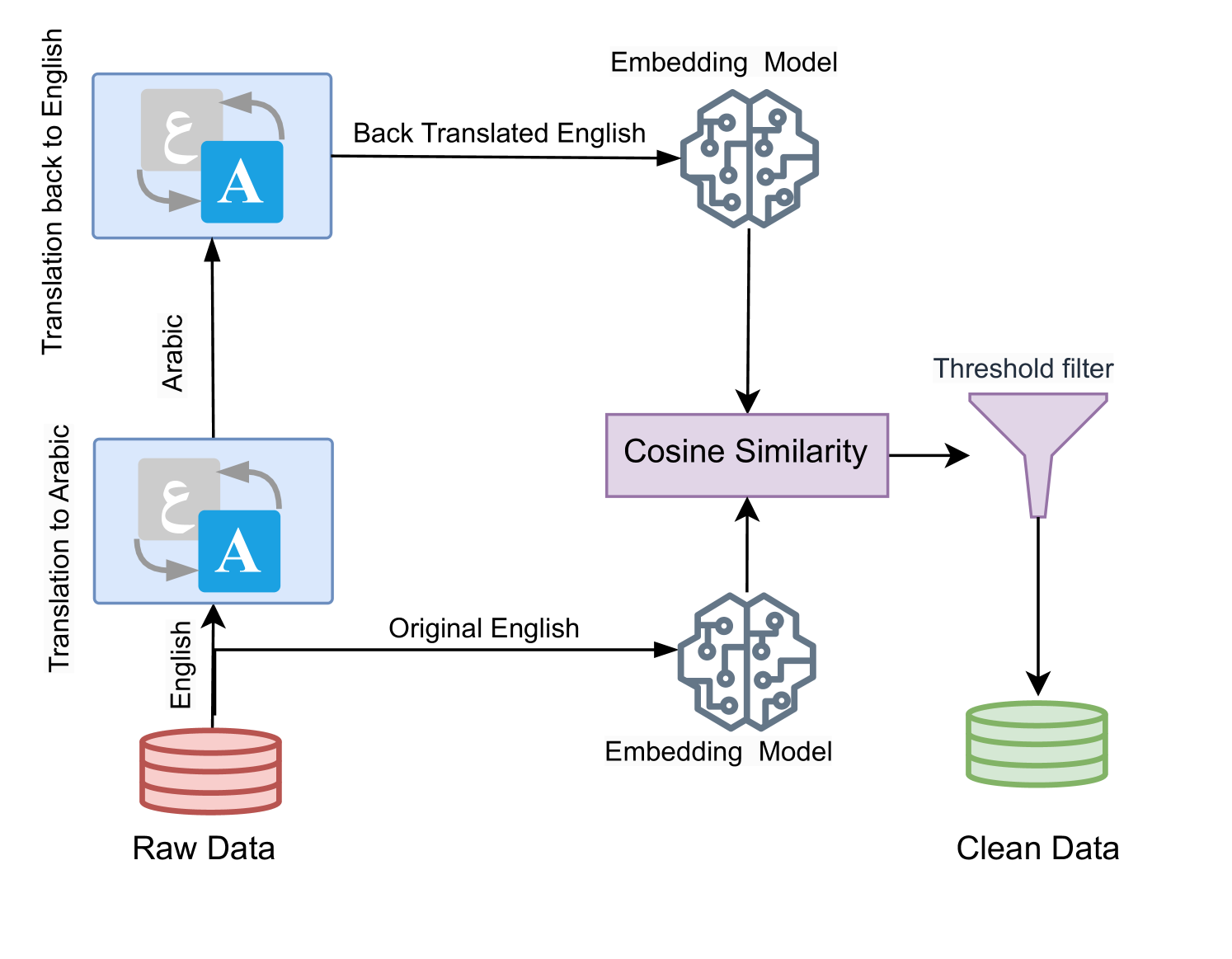
核心思路:Dallah的核心思路是构建一个能够理解和生成阿拉伯语,特别是各种方言的多模态模型。通过在包含图像和文本的阿拉伯语数据集上进行微调,使模型能够学习到图像和文本之间的对应关系,并能够根据图像生成相应的阿拉伯语描述,或者根据阿拉伯语文本生成相应的图像。
技术框架:Dallah基于LLaMA-2构建,并采用了一种多模态融合框架。该框架包含以下几个主要模块:1) 图像编码器:用于将输入图像编码成视觉特征向量。2) 文本编码器:用于将输入文本编码成文本特征向量。3) 多模态融合模块:用于将视觉特征向量和文本特征向量进行融合,得到多模态特征向量。4) 解码器:用于根据多模态特征向量生成阿拉伯语文本。
关键创新:Dallah的关键创新在于其对阿拉伯语方言的处理能力。通过在包含六种阿拉伯语方言的数据集上进行微调,Dallah能够理解和生成不同方言的文本,从而提高了模型在实际应用中的可用性。此外,Dallah还采用了先进的多模态融合技术,提高了图像和文本之间的关联性。
关键设计:Dallah使用了预训练的LLaMA-2模型作为基础语言模型,并在此基础上进行了微调。图像编码器可以使用预训练的视觉模型,如CLIP或ViT。多模态融合模块可以使用注意力机制或Transformer结构。损失函数可以使用交叉熵损失或对比学习损失。具体的参数设置需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
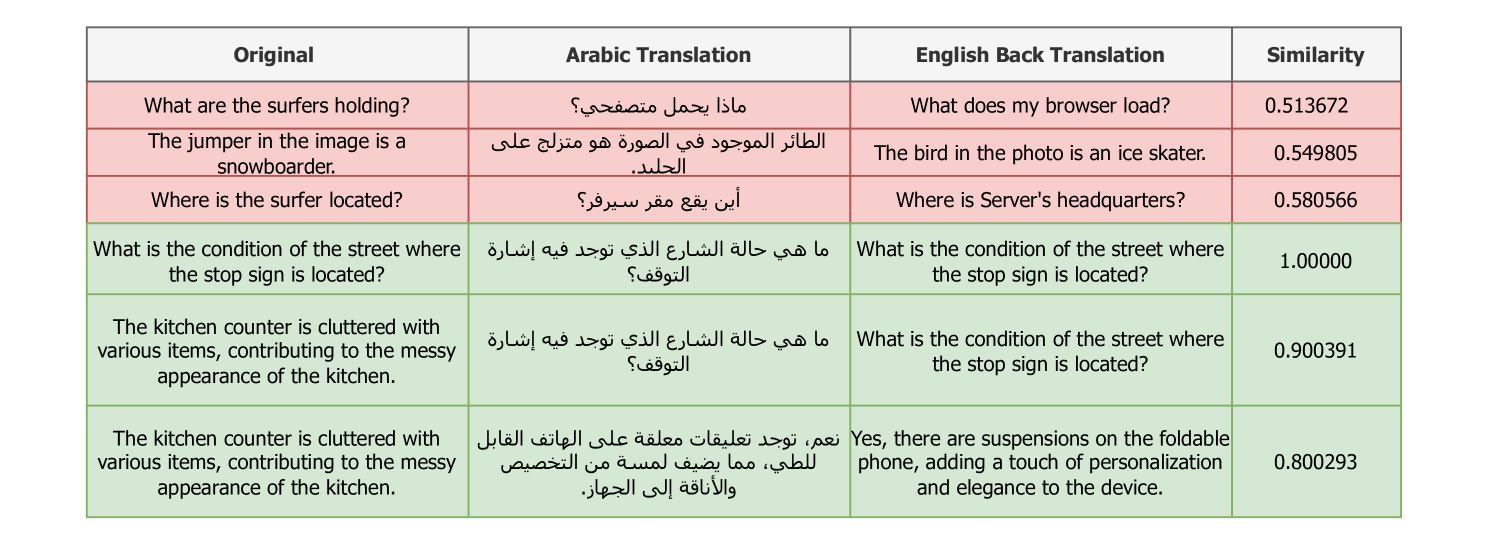
Dallah在阿拉伯语多模态任务上取得了state-of-the-art的性能。通过微调六种阿拉伯语方言,Dallah在处理复杂方言交互方面表现出色。在现代标准阿拉伯语和方言响应的基准测试中,Dallah均取得了优异的成绩,证明了其在阿拉伯语多模态理解和生成方面的强大能力。
🎯 应用场景
Dallah可应用于多种场景,例如:智能客服、教育辅助、社交媒体内容理解、文化遗产保护等。它可以帮助用户更方便地获取信息、创作内容,并促进不同文化之间的交流。未来,Dallah有望成为阿拉伯语地区多模态人工智能应用的重要基础设施。
📄 摘要(原文)
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.