I can listen but cannot read: An evaluation of two-tower multimodal systems for instrument recognition
作者: Yannis Vasilakis, Rachel Bittner, Johan Pauwels
分类: cs.SD, cs.CL, cs.IR, cs.LG, eess.AS
发布日期: 2024-07-25
备注: Accepted to ISMIR 2024
💡 一句话要点
评估双塔多模态系统在乐器识别中的性能,揭示文本编码器的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 乐器识别 双塔模型 多模态学习 零样本学习 文本编码器 音频编码器 语义分析
📋 核心要点
- 现有双塔多模态系统在乐器识别中,文本编码器性能不足,无法有效利用文本信息。
- 论文通过分析预联合和联合嵌入空间,揭示了文本编码器对特定词语的敏感性问题。
- 提出一种基于乐器本体的语义有意义性量化方法,评估文本空间,发现系统对乐器理解的不足。
📝 摘要(中文)
音乐双塔多模态系统将音频和文本模态集成到联合音频-文本空间中,从而可以直接比较歌曲及其对应的标签。这些系统为分类和检索提供了新方法,利用了两种模态。尽管它们在零样本分类和检索任务中显示出可喜的结果,但仍需要更仔细地检查嵌入。本文评估了联合音频-文本空间固有的零样本属性,以乐器识别为例。我们对用于零样本乐器识别的双塔系统进行了评估和分析,并详细分析了预联合和联合嵌入空间的属性。我们的研究结果表明,音频编码器本身表现出良好的质量,而文本编码器或联合空间投影仍然存在挑战。具体来说,双塔系统对特定词语表现出敏感性,偏爱通用提示而非音乐信息提示。尽管文本编码器尺寸很大,但它们尚未利用额外的文本上下文或从其描述中准确推断乐器。最后,提出了一种量化文本空间语义意义的新方法,该方法利用乐器本体。该方法揭示了系统对乐器的理解不足,并提供了需要对音乐数据上的文本编码器进行微调的证据。
🔬 方法详解
问题定义:论文旨在评估双塔多模态系统在零样本乐器识别任务中的性能。现有方法虽然在零样本分类和检索上取得了一定进展,但对联合嵌入空间的理解和文本编码器的有效性仍缺乏深入分析。现有文本编码器无法充分利用文本描述中的乐器信息,导致识别精度不高。
核心思路:论文的核心思路是通过深入分析音频和文本编码器产生的嵌入空间,特别是联合嵌入空间,来揭示双塔系统在乐器识别任务中的优势和不足。通过量化文本空间的语义意义,评估系统对乐器概念的理解程度,从而找出改进方向。
技术框架:论文采用典型的双塔结构,包含音频编码器和文本编码器两个主要模块。音频编码器负责将音频信号转换为音频嵌入,文本编码器负责将乐器描述转换为文本嵌入。然后,通过一个投影层将两个嵌入映射到联合嵌入空间,以便进行比较和分类。论文重点分析了预联合(音频和文本编码器输出)和联合嵌入空间的特性。
关键创新:论文的关键创新在于提出了一种基于乐器本体的语义有意义性量化方法。该方法利用乐器本体的结构信息,评估文本嵌入空间中乐器概念的分布和关系,从而量化系统对乐器语义的理解程度。这种方法为评估多模态系统中文本编码器的性能提供了一种新的视角。
关键设计:论文使用了预训练的音频和文本编码器,具体模型信息未知。关键设计在于语义有意义性量化方法,该方法需要一个乐器本体作为先验知识。具体实现细节,例如本体的构建方式、量化指标的选择等,论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片


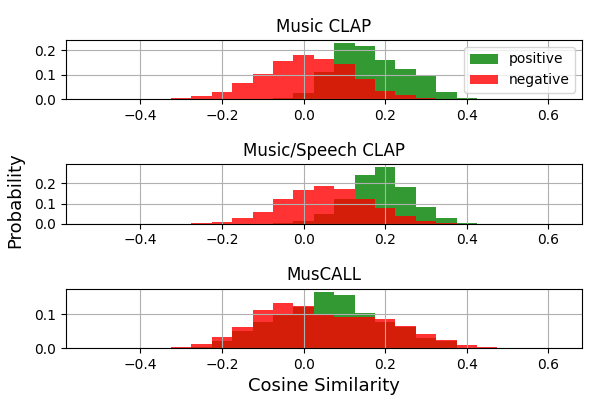
📊 实验亮点
实验结果表明,音频编码器表现良好,但文本编码器存在局限性,对特定词语敏感,无法有效利用文本上下文。基于乐器本体的语义有意义性量化方法揭示了系统对乐器理解的不足,为改进文本编码器提供了方向。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于音乐信息检索、自动音乐标注、音乐教育等领域。通过提升多模态系统对乐器的理解能力,可以实现更精准的音乐检索和推荐,辅助音乐学习者理解乐器知识,并为音乐创作提供灵感。
📄 摘要(原文)
Music two-tower multimodal systems integrate audio and text modalities into a joint audio-text space, enabling direct comparison between songs and their corresponding labels. These systems enable new approaches for classification and retrieval, leveraging both modalities. Despite the promising results they have shown for zero-shot classification and retrieval tasks, closer inspection of the embeddings is needed. This paper evaluates the inherent zero-shot properties of joint audio-text spaces for the case-study of instrument recognition. We present an evaluation and analysis of two-tower systems for zero-shot instrument recognition and a detailed analysis of the properties of the pre-joint and joint embeddings spaces. Our findings suggest that audio encoders alone demonstrate good quality, while challenges remain within the text encoder or joint space projection. Specifically, two-tower systems exhibit sensitivity towards specific words, favoring generic prompts over musically informed ones. Despite the large size of textual encoders, they do not yet leverage additional textual context or infer instruments accurately from their descriptions. Lastly, a novel approach for quantifying the semantic meaningfulness of the textual space leveraging an instrument ontology is proposed. This method reveals deficiencies in the systems' understanding of instruments and provides evidence of the need for fine-tuning text encoders on musical data.