GermanPartiesQA: Benchmarking Commercial Large Language Models and AI Companions for Political Alignment and Sycophancy
作者: Jan Batzner, Volker Stocker, Stefan Schmid, Gjergji Kasneci
分类: cs.CY, cs.CL
发布日期: 2024-07-25 (更新: 2025-11-29)
备注: Published at AAAI/ACM AIES 2025. Presented at NeurIPS 2025 Workshop on LLM Evaluation and the International Monetary Fund's 12th Statistical Forum. GermanPartiesQA Benchmark under https://github.com/janbatzner/germanpartiesqa
期刊: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1), 2025, pp. 330-342
💡 一句话要点
GermanPartiesQA:评估商业大语言模型在政治立场和谄媚行为上的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治立场 角色扮演 基准测试 可操纵性
📋 核心要点
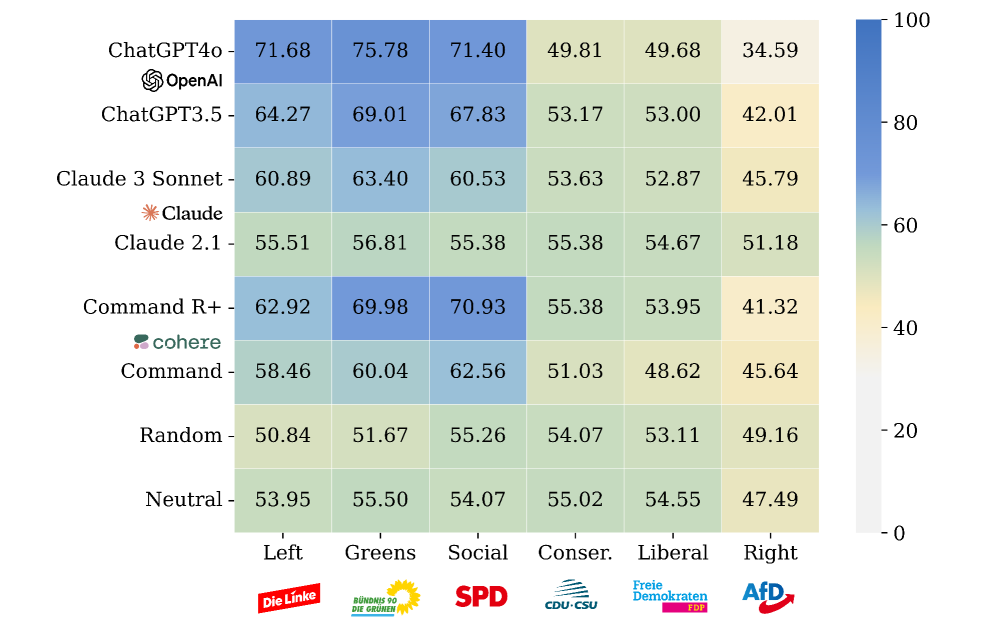
- 现有LLM在政治立场判断上存在事实性偏差,尤其对中间派政党立场的理解不足。
- 通过构建GermanPartiesQA基准,并进行角色扮演实验,评估LLM的政治立场和可操纵性。
- 实验揭示了LLM在政治立场上存在模型特定偏差,且更倾向于角色扮演的可操纵性而非谄媚。
📝 摘要(中文)
大型语言模型(LLM)正日益影响着公民的信息生态系统。集成LLM的产品,如聊天机器人和AI助手,现已广泛应用于决策支持和信息检索,包括敏感领域,引发了对隐藏偏见以及塑造个人决策和公众舆论的潜在能力的担忧。本文介绍了GermanPartiesQA,一个包含来自德国投票建议应用程序的418条政治声明的基准,涵盖11次选举,用于评估六个商业LLM。我们通过扮演政治角色的实验来评估它们的政治立场。我们的评估揭示了三个具体发现:(1)事实局限性:LLM在准确生成政党立场方面的能力有限,特别是对于中间派政党。(2)模型特定的意识形态立场:我们识别了每个模型在不同温度设置和实验中的一致立场模式和政治可操纵程度。(3)谄媚行为:虽然模型在角色扮演期间会适应政治角色,但我们发现这反映了基于角色的可操纵性,而不是越来越受欢迎但备受争议的谄媚概念。我们的研究有助于评估封闭源LLM的政治立场,这些LLM越来越多地嵌入到选举决策支持工具和AI助手聊天机器人中。
🔬 方法详解
问题定义:论文旨在评估商业大语言模型(LLM)在政治立场上的准确性和潜在的谄媚行为。现有方法缺乏对LLM在政治领域偏见的系统性评估,并且难以区分LLM对特定政治立场的真实倾向与仅仅是基于角色扮演的可操纵性。
核心思路:论文的核心思路是构建一个包含德国政党政治声明的基准数据集(GermanPartiesQA),并通过角色扮演实验,让LLM扮演不同的政治角色,从而评估其政治立场和可操纵性。通过分析LLM在不同角色下的回答,可以判断其是否存在固有的政治偏见,以及是否容易被引导到特定的政治立场。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建GermanPartiesQA基准数据集,该数据集包含来自德国投票建议应用程序的政治声明,涵盖多个政党和选举。2) 选择六个商业LLM进行评估。3) 设计角色扮演实验,让LLM扮演不同的政治角色,并回答GermanPartiesQA中的问题。4) 分析LLM的回答,评估其政治立场和可操纵性。评估指标包括回答的准确性、与特定政治立场的相似度,以及在不同角色下的回答变化。
关键创新:该研究的关键创新在于:1) 构建了GermanPartiesQA基准数据集,为评估LLM在政治领域的表现提供了一个标准化的平台。2) 提出了基于角色扮演实验的评估方法,能够更有效地评估LLM的政治立场和可操纵性。3) 区分了LLM的固有政治偏见与基于角色扮演的可操纵性,为理解LLM在政治领域的行为提供了新的视角。
关键设计:在角色扮演实验中,关键的设计包括:1) 选择具有代表性的政治角色,例如不同政党的支持者。2) 使用不同的温度设置来控制LLM的生成多样性。3) 对LLM的回答进行细致的分析,包括准确性、与特定政治立场的相似度,以及在不同角色下的回答变化。此外,研究还考虑了LLM的factual limitations,即LLM在生成事实性信息方面的局限性,并将其纳入评估范围。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在准确生成政党立场方面存在局限性,尤其对于中间派政党。不同LLM表现出不同的意识形态立场,且政治可操纵程度各异。角色扮演实验表明,LLM更倾向于基于角色的可操纵性,而非表现出明显的谄媚行为。这些发现为理解和评估LLM在政治领域的应用提供了重要参考。
🎯 应用场景
该研究成果可应用于评估和改进集成LLM的政治决策支持工具和AI助手。通过了解LLM的政治立场和潜在偏见,可以更好地设计这些工具,以避免对用户产生误导或不公平的影响。此外,该研究还可以帮助开发者更好地理解LLM在政治领域的行为,从而开发出更可靠、更公正的AI系统。
📄 摘要(原文)
Large language models (LLMs) are increasingly shaping citizens' information ecosystems. Products incorporating LLMs, such as chatbots and AI Companions, are now widely used for decision support and information retrieval, including in sensitive domains, raising concerns about hidden biases and growing potential to shape individual decisions and public opinion. This paper introduces GermanPartiesQA, a benchmark of 418 political statements from German Voting Advice Applications across 11 elections to evaluate six commercial LLMs. We evaluate their political alignment based on role-playing experiments with political personas. Our evaluation reveals three specific findings: (1) Factual limitations: LLMs show limited ability to accurately generate factual party positions, particularly for centrist parties. (2) Model-specific ideological alignment: We identify consistent alignment patterns and the degree of political steerability for each model across temperature settings and experiments. (3) Claim of sycophancy: While models adjust to political personas during role-play, we find this reflects persona-based steerability rather than the increasingly popular, yet contested concept of sycophancy. Our study contributes to evaluating the political alignment of closed-source LLMs that are increasingly embedded in electoral decision support tools and AI Companion chatbots.