Vision-Language Models Align with Human Neural Representations in Concept Processing
作者: Anna Bavaresco, Marianne de Heer Kloots, Sandro Pezzelle, Raquel Fernández
分类: cs.CL
发布日期: 2024-07-25 (更新: 2026-01-22)
备注: Accepted to EACL 2026 main
🔗 代码/项目: GITHUB
💡 一句话要点
研究表明视觉-语言模型在概念处理中与人类神经表征对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 概念处理 神经表征 fMRI 大脑对齐
📋 核心要点
- 现有研究缺乏对不同VLM架构以及视觉和文本上下文作用的系统评估。
- 该研究通过分析多种VLM和仅语言模型,比较其概念表征与人类大脑fMRI响应的一致性。
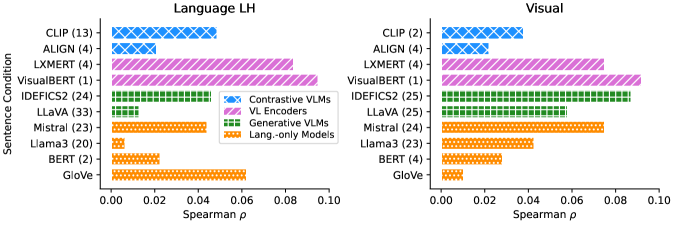
- 实验结果表明VLMs优于仅语言模型,但部分VLM的大脑对齐依赖于预训练学习,另一些则对上下文敏感。
📝 摘要(中文)
本研究旨在系统性评估不同类型的视觉-语言模型(VLMs)架构以及视觉和文本上下文所起的作用。通过分析多种采用不同策略整合视觉和文本模态的VLMs以及仅使用语言的模型,研究测量了模型产生的概念表征与人类大脑对概念词汇的fMRI响应之间的一致性,实验中概念词汇分别在视觉(图片)或文本(句子)上下文中呈现。结果表明,VLMs在两种实验条件下均优于仅使用语言的模型。然而,受控消融研究表明,只有部分VLMs(如LXMERT和IDEFICS2)的大脑对齐源于预训练期间真正学习到更像人类的概念,而其他模型对推理时提供的上下文高度敏感。此外,视觉-语言编码器比更新的生成式VLMs更符合大脑活动。总而言之,这项研究表明VLMs在概念处理中与人类神经表征对齐,同时也强调了不同架构之间的差异。研究开源了代码和材料,以复现实验。
🔬 方法详解
问题定义:该论文旨在研究视觉-语言模型(VLMs)在概念处理过程中,其内部表征与人类大脑神经表征的对齐程度。现有方法缺乏对不同VLM架构以及视觉和文本上下文影响的系统性评估,难以确定哪些VLM真正学习到了类似人类的概念表征,以及哪些VLM仅仅依赖于上下文信息。
核心思路:核心思路是通过比较不同VLMs(包括编码器和生成器架构)产生的概念表征与人类大脑在处理相同概念时产生的fMRI数据,来评估它们之间的对齐程度。通过控制视觉和文本上下文,并进行消融实验,来分析不同VLM架构以及上下文信息对大脑对齐的影响。
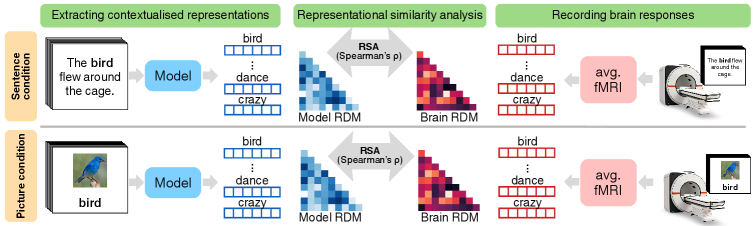
技术框架:整体框架包括以下几个步骤:1)选择多种VLMs,包括视觉-语言编码器(如LXMERT)和生成式VLMs(如IDEFICS2),以及仅使用语言的模型作为基线;2)设计实验,让人类受试者在两种条件下处理概念词汇:视觉上下文(图片)和文本上下文(句子);3)使用fMRI记录受试者的大脑活动;4)使用VLMs处理相同的概念词汇,提取其内部表征;5)计算VLMs的表征与人类大脑fMRI数据之间的对齐程度,使用如Representational Similarity Analysis (RSA)等方法。
关键创新:该研究的关键创新在于:1)系统性地比较了多种VLMs在概念处理中与人类大脑神经表征的对齐程度;2)通过控制视觉和文本上下文,揭示了不同VLM架构以及上下文信息对大脑对齐的影响;3)发现只有部分VLMs(如LXMERT和IDEFICS2)的大脑对齐源于预训练期间真正学习到更像人类的概念,而其他模型对推理时提供的上下文高度敏感;4)发现视觉-语言编码器比更新的生成式VLMs更符合大脑活动。
关键设计:关键设计包括:1)选择具有代表性的VLMs架构,包括编码器(如LXMERT)和生成器(如IDEFICS2),以及仅使用语言的模型;2)设计两种实验条件:视觉上下文(图片)和文本上下文(句子),以控制上下文信息;3)使用RSA等方法计算模型表征与大脑fMRI数据之间的对齐程度;4)进行消融实验,移除VLMs的视觉或文本模态,以分析不同模态对大脑对齐的影响。
🖼️ 关键图片

📊 实验亮点
研究结果表明,VLMs在概念处理中与人类神经表征对齐,且优于仅使用语言的模型。LXMERT和IDEFICS2等模型的大脑对齐源于预训练期间学习到更像人类的概念,而其他模型对上下文敏感。视觉-语言编码器比更新的生成式VLMs更符合大脑活动。这些发现为VLM的设计和训练提供了重要指导。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型的认知能力,使其更符合人类的认知方式。通过理解哪些VLM架构和训练方法能够更好地模拟人类大脑的概念处理过程,可以开发出更智能、更自然的AI系统,应用于人机交互、智能助手、教育等领域。此外,该研究也有助于神经科学领域,加深对人类大脑概念表征机制的理解。
📄 摘要(原文)
Recent studies suggest that transformer-based vision-language models (VLMs) capture the multimodality of concept processing in the human brain. However, a systematic evaluation exploring different types of VLM architectures and the role played by visual and textual context is still lacking. Here, we analyse multiple VLMs employing different strategies to integrate visual and textual modalities, along with language-only counterparts. We measure the alignment between concept representations by models and existing (fMRI) brain responses to concept words presented in two experimental conditions, where either visual (pictures) or textual (sentences) context is provided. Our results reveal that VLMs outperform the language-only counterparts in both experimental conditions. However, controlled ablation studies show that only for some VLMs, such as LXMERT and IDEFICS2, brain alignment stems from genuinely learning more human-like concepts during pretraining, while others are highly sensitive to the context provided at inference. Additionally, we find that vision-language encoders are more brain-aligned than more recent, generative VLMs. Altogether, our study shows that VLMs align with human neural representations in concept processing, while highlighting differences among architectures. We open-source code and materials to reproduce our experiments at: https://github.com/dmg-illc/vl-concept-processing.