Demystifying Verbatim Memorization in Large Language Models
作者: Jing Huang, Diyi Yang, Christopher Potts
分类: cs.CL, cs.LG
发布日期: 2024-07-25
💡 一句话要点
通过可控实验揭示大语言模型逐字记忆的内在机制与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 逐字记忆 隐私安全 可控实验 模型遗忘
📋 核心要点
- 现有研究主要依赖观测数据,难以控制变量,无法深入理解大语言模型逐字记忆的内在机制。
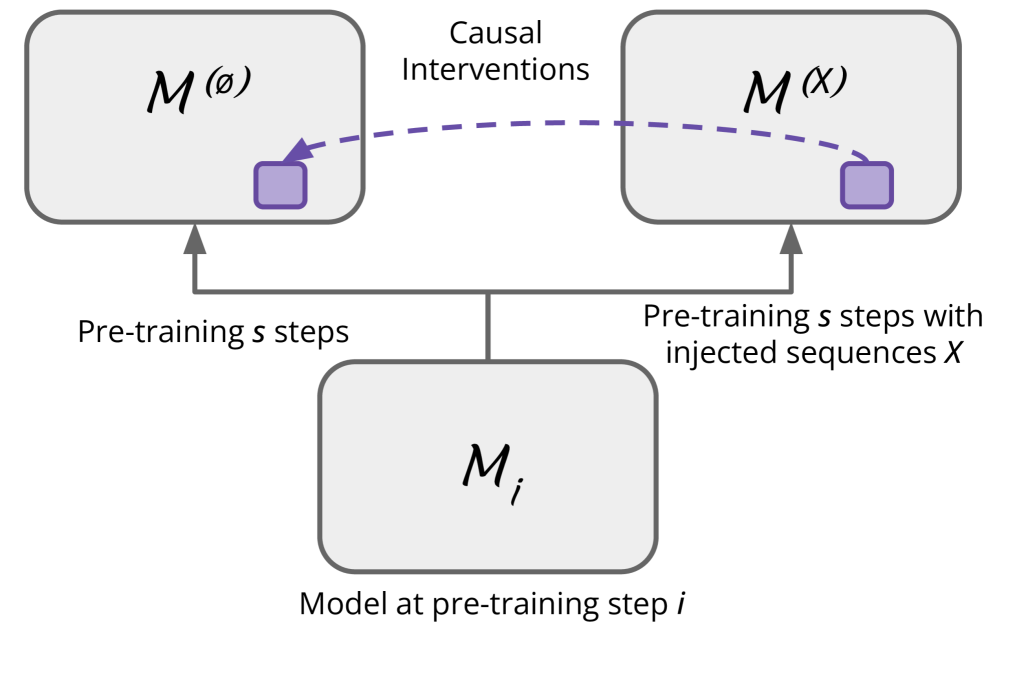
- 该论文提出一个可控实验框架,通过注入序列并继续预训练Pythia模型,系统性地研究逐字记忆现象。
- 实验表明,逐字记忆与模型能力紧密相关,且现有的非学习方法难以有效消除记忆,同时会损害模型性能。
📝 摘要(中文)
大型语言模型(LLMs)经常逐字记忆长序列,这通常涉及严重的法律和隐私问题。大量先前工作使用观测数据研究了这种逐字记忆现象。为了补充这些工作,我们开发了一个框架,通过使用注入序列从Pythia检查点继续预训练,从而在受控环境中研究逐字记忆。我们发现:(1)非平凡的重复量是逐字记忆发生的必要条件;(2)较晚的(并且可能更好的)检查点更可能逐字记忆序列,即使对于分布外的序列也是如此;(3)记忆序列的生成是由编码高级特征的分布式模型状态触发的,并且充分利用了一般的语言建模能力。在这些见解的指导下,我们开发了压力测试来评估非学习方法,发现它们通常无法删除逐字记忆的信息,同时还会降低LM的性能。总的来说,这些发现挑战了逐字记忆源于特定模型权重或机制的假设。相反,逐字记忆与LM的一般能力交织在一起,因此在不降低模型质量的情况下,将非常难以隔离和抑制。
🔬 方法详解
问题定义:论文旨在解决大语言模型中逐字记忆现象的成因和消除问题。现有方法主要依赖于观测数据,缺乏可控性,难以深入分析逐字记忆的内在机制。此外,现有的“遗忘”方法往往无法有效消除记忆,同时还会损害模型性能。
核心思路:论文的核心思路是通过构建一个可控的实验环境,系统性地研究逐字记忆的影响因素和内在机制。通过在预训练过程中注入特定的序列,并观察模型在不同阶段的记忆表现,从而揭示逐字记忆与模型能力之间的关系。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择Pythia模型作为基础模型;2) 构建包含特定序列的数据集,并将其注入到Pythia模型的预训练过程中;3) 在不同的训练阶段(不同的检查点)评估模型对注入序列的记忆能力;4) 设计压力测试来评估现有的“遗忘”方法的效果。
关键创新:该论文的关键创新在于构建了一个可控的实验环境,使得研究人员可以系统性地研究逐字记忆现象。此外,该研究还发现逐字记忆与模型的一般能力紧密相关,挑战了以往认为逐字记忆源于特定模型权重或机制的假设。
关键设计:论文的关键设计包括:1) 使用Pythia模型,因为它是一个开源且易于访问的模型;2) 通过控制注入序列的重复次数和位置,来研究重复对逐字记忆的影响;3) 使用困惑度(perplexity)和精确匹配(exact match)等指标来评估模型的记忆能力;4) 设计压力测试,通过生成对抗样本来评估“遗忘”方法的效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,非平凡的重复是逐字记忆发生的必要条件,且较晚的检查点更易于记忆。此外,现有的“遗忘”方法往往无法有效消除记忆,同时还会降低模型性能。这些发现挑战了以往的假设,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于提升大语言模型的安全性和隐私性。通过深入理解逐字记忆的内在机制,可以开发更有效的“遗忘”方法,从而避免模型泄露敏感信息。此外,该研究还可以帮助开发者更好地评估和控制模型的行为,从而构建更可靠的AI系统。
📄 摘要(原文)
Large Language Models (LLMs) frequently memorize long sequences verbatim, often with serious legal and privacy implications. Much prior work has studied such verbatim memorization using observational data. To complement such work, we develop a framework to study verbatim memorization in a controlled setting by continuing pre-training from Pythia checkpoints with injected sequences. We find that (1) non-trivial amounts of repetition are necessary for verbatim memorization to happen; (2) later (and presumably better) checkpoints are more likely to verbatim memorize sequences, even for out-of-distribution sequences; (3) the generation of memorized sequences is triggered by distributed model states that encode high-level features and makes important use of general language modeling capabilities. Guided by these insights, we develop stress tests to evaluate unlearning methods and find they often fail to remove the verbatim memorized information, while also degrading the LM. Overall, these findings challenge the hypothesis that verbatim memorization stems from specific model weights or mechanisms. Rather, verbatim memorization is intertwined with the LM's general capabilities and thus will be very difficult to isolate and suppress without degrading model quality.