S2-Attention: Hardware-Aware Context Sharding Among Attention Heads
作者: Xihui Lin, Yunan Zhang, Suyu Ge, Liliang Ren, Barun Patra, Vishrav Chaudhary, Hao Peng, Xia Song
分类: cs.CL
发布日期: 2024-07-25 (更新: 2025-02-05)
备注: 10 pages
💡 一句话要点
提出S2-Attention,通过硬件感知的上下文分片优化稀疏注意力,提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 大型语言模型 硬件感知优化 上下文分片 Triton 推理加速 长文本处理
📋 核心要点
- 现有稀疏注意力方法缺乏硬件感知优化,导致理论FLOPs减少难以转化为实际加速,限制了其在大规模LLM上的应用。
- S2-Attention通过Triton库提供可定制的稀疏注意力内核优化,支持在每个head和上下文范围内进行灵活配置,实现高效的上下文分片。
- 实验表明,S2-Attention在多种稀疏注意力设计和模型规模下均表现出色,推理速度提升显著,下游任务性能与全注意力模型相当。
📝 摘要(中文)
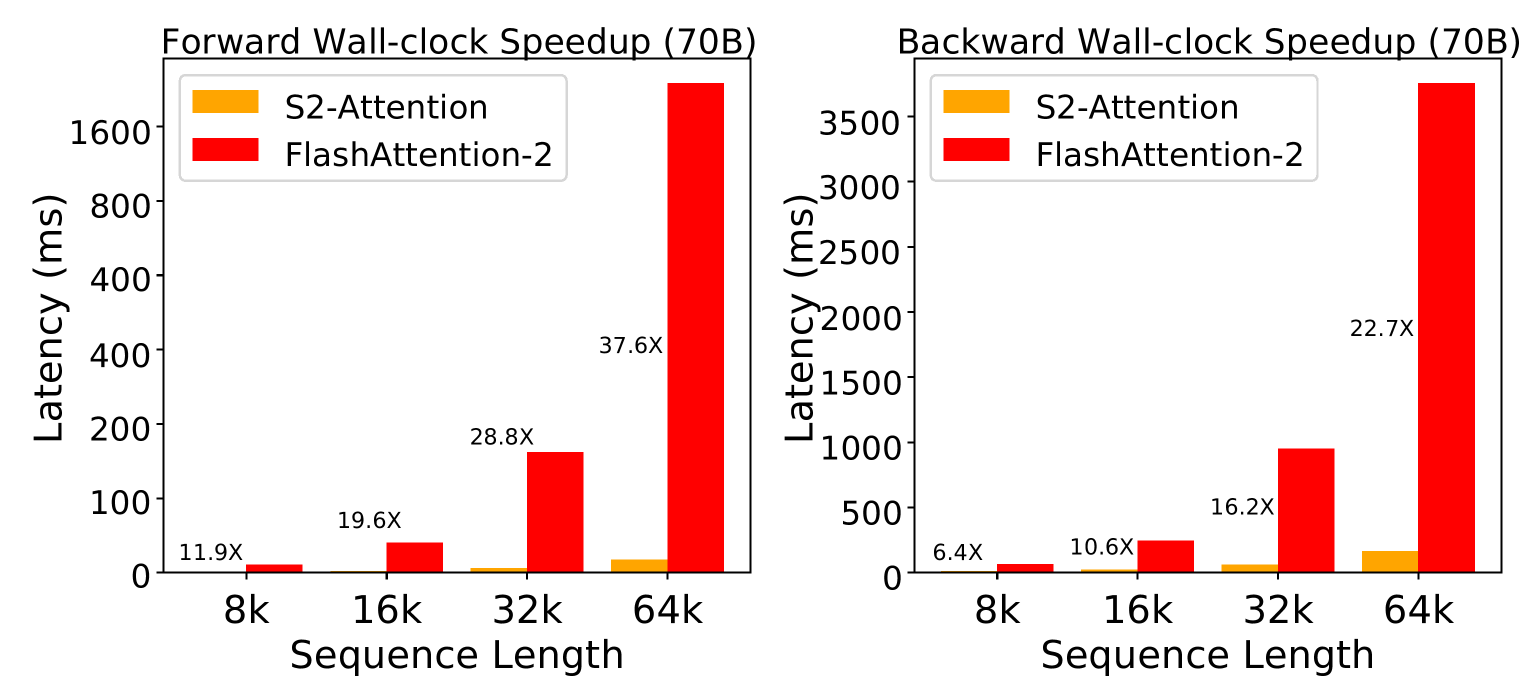
稀疏注意力旨在通过选择性地关注上下文中的部分token来提高效率。然而,由于缺乏像FlashAttention这样的硬件感知优化,其理论上的FLOPs减少很少转化为实际的加速。同时,稀疏注意力能否在当今大型语言模型(LLM)的规模上保持模型质量以及如何保持仍然不清楚。本文提出了Sparsely-Sharded(S2) Attention,这是一个Triton库,为稀疏注意力提供内核优化,可在每个head和每个上下文范围级别进行定制。S2-Attention能够探索新颖且高性能的稀疏注意力技术,我们通过在各种模型规模上对各种稀疏注意力设计进行广泛的消融实验来证明这一点。从这些见解中,我们提出了一些基本指南来设计稀疏注意力,这些指南不仅可以实现实际的效率提升,还可以实现强大的下游性能。为了实现高并行化和优化的内存IO,稀疏注意力应该在注意力头之间异构地分片上下文,其中每个头关注不同的token子集,同时共同覆盖完整的上下文。同时,我们发现结合稀疏和密集注意力的混合架构在实践中特别有益。与强大的FlashAttention-2基线相比,S2-Attention实现了8.79倍、15.87倍、25.3倍的加速,并且在下游性能上与完整注意力相当,在128k上下文长度下实现了完美的检索性能。在推理时,对于7B模型,在S2-Attention内核的帮助下,我们的模型与密集模型相比实现了4.5倍的加速。S2-Attention已发布,带有易于定制的API,可直接在Megatron和vLLM中使用。
🔬 方法详解
问题定义:现有稀疏注意力方法虽然在理论上减少了计算量,但由于缺乏针对硬件的优化,例如内存访问优化和并行化策略,导致实际运行速度提升不明显。此外,如何设计有效的稀疏注意力模式,使其在保持模型性能的同时,实现真正的加速,仍然是一个挑战。
核心思路:S2-Attention的核心思路是利用硬件感知的上下文分片策略,将上下文信息在不同的注意力头之间进行异构划分。每个注意力头只关注一部分上下文,但所有注意力头共同覆盖完整的上下文。这种方式可以提高并行化程度,减少内存访问量,从而实现加速。同时,通过灵活的配置,可以探索不同的稀疏模式,找到性能和效率的最佳平衡点。
技术框架:S2-Attention基于Triton框架实现,提供了一系列可定制的稀疏注意力内核。用户可以根据自己的需求,配置每个注意力头的上下文范围,以及稀疏模式。整体流程包括:输入token嵌入 -> S2-Attention层(包含上下文分片、注意力计算、输出融合) -> 输出token嵌入。S2-Attention可以方便地集成到现有的LLM框架中,如Megatron和vLLM。
关键创新:S2-Attention的关键创新在于硬件感知的上下文分片策略。与传统的稀疏注意力方法不同,S2-Attention不是简单地随机或基于某种启发式规则选择关注的token,而是根据硬件特性,将上下文信息在不同的注意力头之间进行合理划分,从而最大化并行化效率和减少内存访问。此外,S2-Attention还提供了一个灵活的API,允许用户自定义稀疏模式,探索不同的设计空间。
关键设计:S2-Attention的关键设计包括:1) 异构上下文分片策略:不同的注意力头关注不同的上下文范围,确保所有头共同覆盖完整的上下文。2) 可定制的稀疏模式:用户可以根据自己的需求,配置每个头的稀疏模式,例如block稀疏、随机稀疏等。3) 混合注意力架构:结合稀疏和密集注意力,利用各自的优势,进一步提升性能。4) 基于Triton的内核优化:充分利用Triton的编译优化能力,生成高效的CUDA代码。
🖼️ 关键图片


📊 实验亮点
S2-Attention在实验中表现出色,与FlashAttention-2相比,实现了高达25.3倍的加速。在7B模型上,推理速度提升了4.5倍。同时,S2-Attention在下游任务上的性能与全注意力模型相当,在128k上下文长度下实现了完美的检索性能。这些结果表明,S2-Attention是一种高效且有效的稀疏注意力方法。
🎯 应用场景
S2-Attention可应用于各种需要长上下文处理的大型语言模型,例如机器翻译、文本摘要、问答系统和代码生成等。通过提高推理效率,S2-Attention可以降低部署成本,并支持更大规模的模型和更长的上下文长度,从而提升用户体验和模型性能。该技术还有潜力应用于其他序列建模任务,例如语音识别和时间序列预测。
📄 摘要(原文)
Sparse attention, which selectively attends to a subset of tokens in the context was supposed to be efficient. However, its theoretical reduction in FLOPs has rarely translated into wall-clock speed-up over its dense attention counterparts due to the lack of hardware-aware optimizations like FlashAttention. Meanwhile, it remains unclear whether sparse attention can maintain the model's quality at a scale of today's large language models (LLMs) and how. This paper presents Sparsely-Sharded(S2) Attention, a Triton library that provides kernel optimization for sparse attention customizable at both per-head and per-context-range levels. S2-Attention enables the exploration of novel and high-performance sparse attention techniques, which we demonstrate through extensive ablations across a wide range of sparse attention designs at various model scales. From these insights, we present several basic guidelines to design sparse attention that can achieve not only practical efficiency improvements, but also strong downstream performance. To achieve high parallelization and optimized memory IO, sparse attention should shard the context heterogeneously across attention heads, where each head attends to a different subset of tokens while collectively covering the full context. Meanwhile, we find hybrid architectures combining sparse and dense attention particularly beneficial in practice. S2-Attention achieves wall-clock speedup of 8.79X, 15.87X, 25.3X compared to the strong FlashAttention-2 baseline with strong downstream performance on-par with full attention and perfect retrieval performance at a 128k context length. At inference, for 7B models, our model, with the help of our S2-Attention kernel, achieves 4.5x speed-up compared to dense counterparts. S2-Attention is released with easy-to-customize APIs for direct usage in Megatron and vLLM.