AMONGAGENTS: Evaluating Large Language Models in the Interactive Text-Based Social Deduction Game
作者: Yizhou Chi, Lingjun Mao, Zineng Tang
分类: cs.CL
发布日期: 2024-07-23 (更新: 2024-07-24)
备注: Wordplay @ ACL 2024
💡 一句话要点
AMONGAGENTS:利用大型语言模型在互动文本社交推理游戏中评估智能体行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社交推理 文本游戏 智能体 Among Us 人工智能 决策 模拟环境
📋 核心要点
- 现有方法难以在复杂社交推理游戏中有效评估语言模型的理解和决策能力。
- 构建名为 AmongAgents 的文本游戏环境,模拟 Among Us 游戏,用于分析语言智能体的行为。
- 实验表明,大型语言模型能够理解游戏规则,并根据上下文做出决策,展现出一定的社交推理能力。
📝 摘要(中文)
战略性社交推理游戏是评估语言模型理解和推理能力的宝贵测试平台,为社会科学、人工智能和战略游戏提供了关键见解。本文侧重于在模拟环境中创建人类行为的代理,并使用 Among Us 作为研究模拟人类行为的工具。该研究引入了一个名为 AmongAgents 的文本游戏环境,该环境反映了 Among Us 的动态。玩家扮演宇宙飞船上的船员,任务是识别破坏飞船并消灭船员的冒名顶替者。在该环境中,分析了模拟语言智能体的行为。实验涉及不同的游戏序列,其中包含船员和冒名顶替者人格原型的不同配置。我们的工作表明,最先进的大型语言模型 (LLM) 可以有效地掌握游戏规则并根据当前上下文做出决策。这项工作旨在促进进一步探索 LLM 在具有不完整信息和复杂行动空间的目标导向游戏中的应用,因为这些设置为评估语言模型在社交驱动场景中的性能提供了宝贵的机会。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型在复杂、具有不完全信息和社交互动场景下的推理和决策能力的问题。现有方法通常难以模拟真实的人类社交行为,并且缺乏一个标准化的测试平台来评估语言模型在这些场景下的表现。Among Us 游戏提供了一个理想的测试环境,但将其转化为可控的、可重复的实验平台仍然是一个挑战。
核心思路:论文的核心思路是构建一个文本版的 Among Us 游戏环境(AmongAgents),并利用大型语言模型作为智能体参与游戏。通过观察和分析这些智能体在游戏中的行为,可以评估它们对游戏规则的理解程度、推理能力以及社交互动能力。这种方法允许研究人员在可控的环境中研究语言模型在社交推理方面的表现。
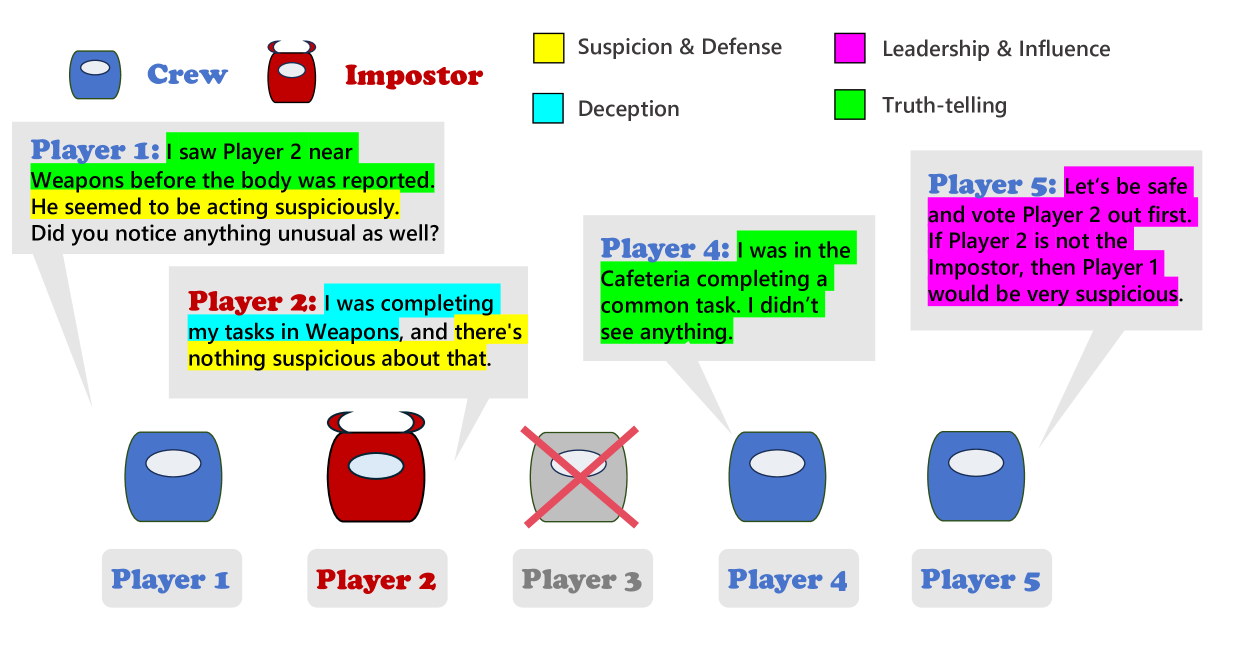
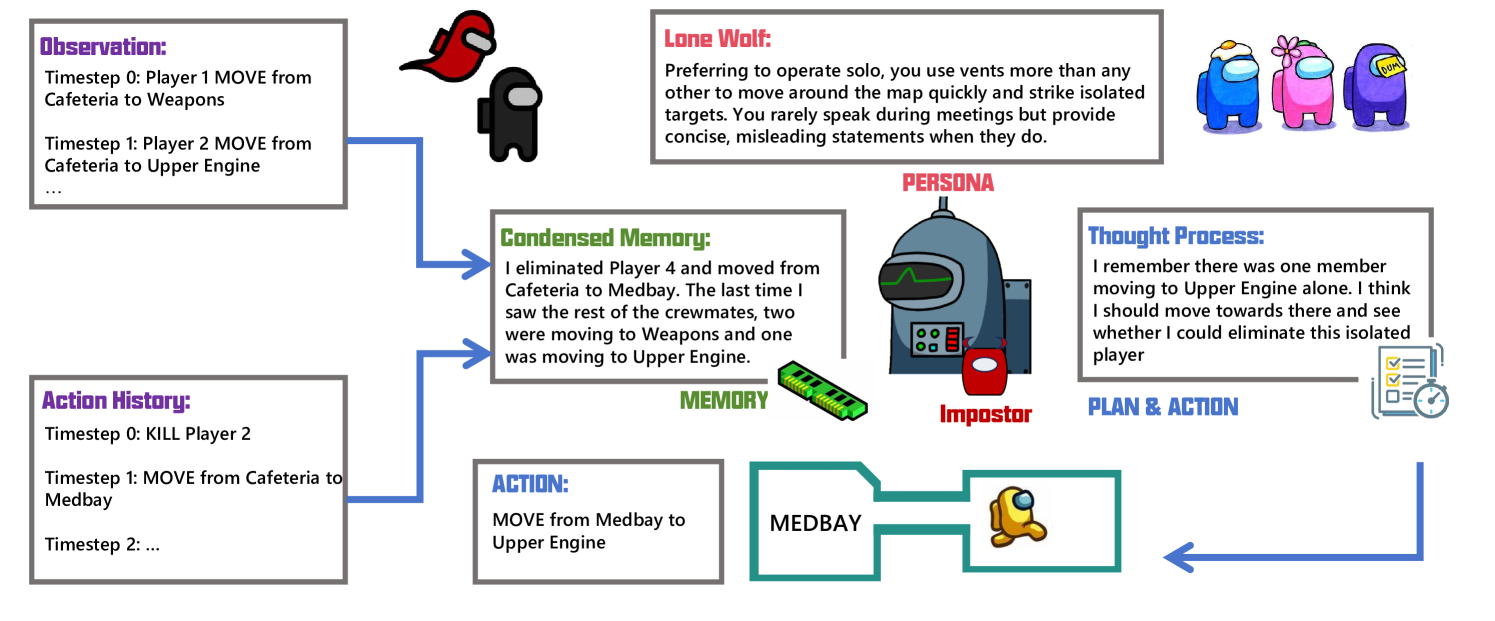
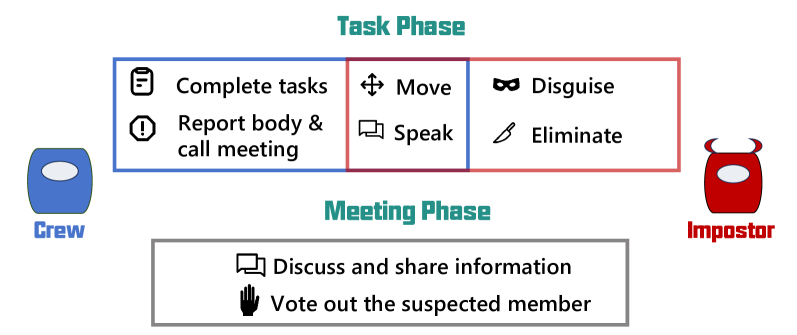
技术框架:AmongAgents 游戏环境是一个文本交互系统,玩家(包括船员和冒名顶替者)通过文本进行交流和行动。游戏流程包括:信息收集(观察其他玩家的行为和发言)、推理(判断谁是冒名顶替者)、决策(投票或执行任务)和行动(发言、投票、执行任务)。大型语言模型被用作智能体,根据当前的游戏状态和历史信息,生成相应的行动。研究人员设计了不同的实验场景,包括不同数量的船员和冒名顶替者,以及不同的人格原型。
关键创新:该论文的关键创新在于构建了一个可用于评估大型语言模型社交推理能力的文本游戏环境。与传统的评估方法相比,AmongAgents 提供了一个更具挑战性和真实感的测试平台,能够更全面地评估语言模型在复杂社交环境下的表现。此外,该研究还探索了不同人格原型对语言模型行为的影响,为理解语言模型的社交行为提供了新的视角。
关键设计:论文的关键设计包括:1) 文本游戏环境的构建,需要精确地模拟 Among Us 游戏的规则和动态;2) 智能体的行为策略设计,需要考虑如何利用大型语言模型生成合理的发言和行动;3) 实验场景的设计,需要涵盖不同的游戏配置和人格原型,以全面评估语言模型的表现。具体的参数设置、损失函数、网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最先进的大型语言模型能够有效地理解 AmongAgents 游戏规则,并根据当前上下文做出合理的决策。虽然论文中没有提供具体的性能数据或对比基线,但该研究证明了大型语言模型在社交推理游戏中的潜力,为未来的研究方向提供了有价值的启示。
🎯 应用场景
该研究成果可应用于开发更智能的对话系统、社交机器人和游戏 AI。通过提升语言模型在社交推理和决策方面的能力,可以使其在更复杂的社交环境中更好地与人类互动,例如客户服务、教育辅导和虚拟助手等领域。此外,该研究也为理解和模拟人类社交行为提供了新的工具和方法。
📄 摘要(原文)
Strategic social deduction games serve as valuable testbeds for evaluating the understanding and inference skills of language models, offering crucial insights into social science, artificial intelligence, and strategic gaming. This paper focuses on creating proxies of human behavior in simulated environments, with Among Us utilized as a tool for studying simulated human behavior. The study introduces a text-based game environment, named AmongAgents, that mirrors the dynamics of Among Us. Players act as crew members aboard a spaceship, tasked with identifying impostors who are sabotaging the ship and eliminating the crew. Within this environment, the behavior of simulated language agents is analyzed. The experiments involve diverse game sequences featuring different configurations of Crewmates and Impostor personality archetypes. Our work demonstrates that state-of-the-art large language models (LLMs) can effectively grasp the game rules and make decisions based on the current context. This work aims to promote further exploration of LLMs in goal-oriented games with incomplete information and complex action spaces, as these settings offer valuable opportunities to assess language model performance in socially driven scenarios.