A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
作者: Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Zixu, Zhu, Xiang-Bo Mao, Sitaram Asur, Na, Cheng
分类: cs.CL
发布日期: 2024-07-23
💡 一句话要点
全面综述LLM对齐技术:RLHF、RLAIF、PPO、DPO等
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM对齐 强化学习 策略优化 人机对齐 指令微调 综述论文
📋 核心要点
- 大型语言模型面临生成不符合人类期望的响应的挑战,源于训练数据质量的混合性。
- 该论文旨在通过对现有LLM对齐方法进行分类和详细解释,填补该领域缺乏全面综述的空白。
- 通过对不同对齐技术进行深入分析,帮助读者全面了解LLM对齐领域的最新进展。
📝 摘要(中文)
随着自监督学习的进步、预训练语料库中数万亿token的可用性、指令微调以及具有数十亿参数的大型Transformer的发展,大型语言模型(LLM)现在能够生成对人类查询的事实性和连贯性响应。然而,训练数据质量的参差不齐可能导致产生不期望的响应,这是一个重大挑战。在过去的两年中,已经从不同的角度提出了各种方法来增强LLM,特别是在使其与人类期望对齐方面。尽管做出了这些努力,但还没有一篇全面的综述论文对这些方法进行分类和详细描述。在这项工作中,我们旨在通过将这些论文分为不同的主题,并提供每种对齐方法的详细解释来弥补这一差距,从而帮助读者彻底了解该领域的当前状态。
🔬 方法详解
问题定义:大型语言模型(LLM)在生成文本时,由于训练数据的多样性和复杂性,经常会产生不符合人类价值观、偏好或期望的输出。现有方法在对齐LLM与人类意图方面存在不足,缺乏系统性的分类和深入的分析,难以指导研究人员和从业者选择合适的对齐策略。
核心思路:该论文的核心思路是对现有的LLM对齐技术进行全面的梳理和分类,深入分析各种方法的原理、优缺点和适用场景,从而为研究人员和从业者提供一个系统的参考框架,帮助他们更好地理解和应用这些技术。
技术框架:该综述论文的技术框架主要包括以下几个部分:首先,对LLM对齐的概念和重要性进行介绍;其次,对现有的对齐技术进行分类,例如基于强化学习的对齐(RLHF、RLAIF)、基于策略优化的对齐(PPO、DPO)等;然后,对每种对齐技术的原理、实现细节和优缺点进行详细的分析;最后,对未来的研究方向进行展望。
关键创新:该论文的关键创新在于其全面性和系统性。它不仅涵盖了主流的LLM对齐技术,还对各种方法的原理和实现细节进行了深入的分析,从而为研究人员和从业者提供了一个全面的参考框架。此外,该论文还对未来的研究方向进行了展望,为该领域的发展提供了指导。
关键设计:论文的关键设计在于其分类体系和分析框架。分类体系将现有的LLM对齐技术分为不同的类别,例如基于强化学习的对齐、基于策略优化的对齐等。分析框架则从原理、实现细节、优缺点和适用场景等多个维度对每种技术进行深入的分析。
🖼️ 关键图片
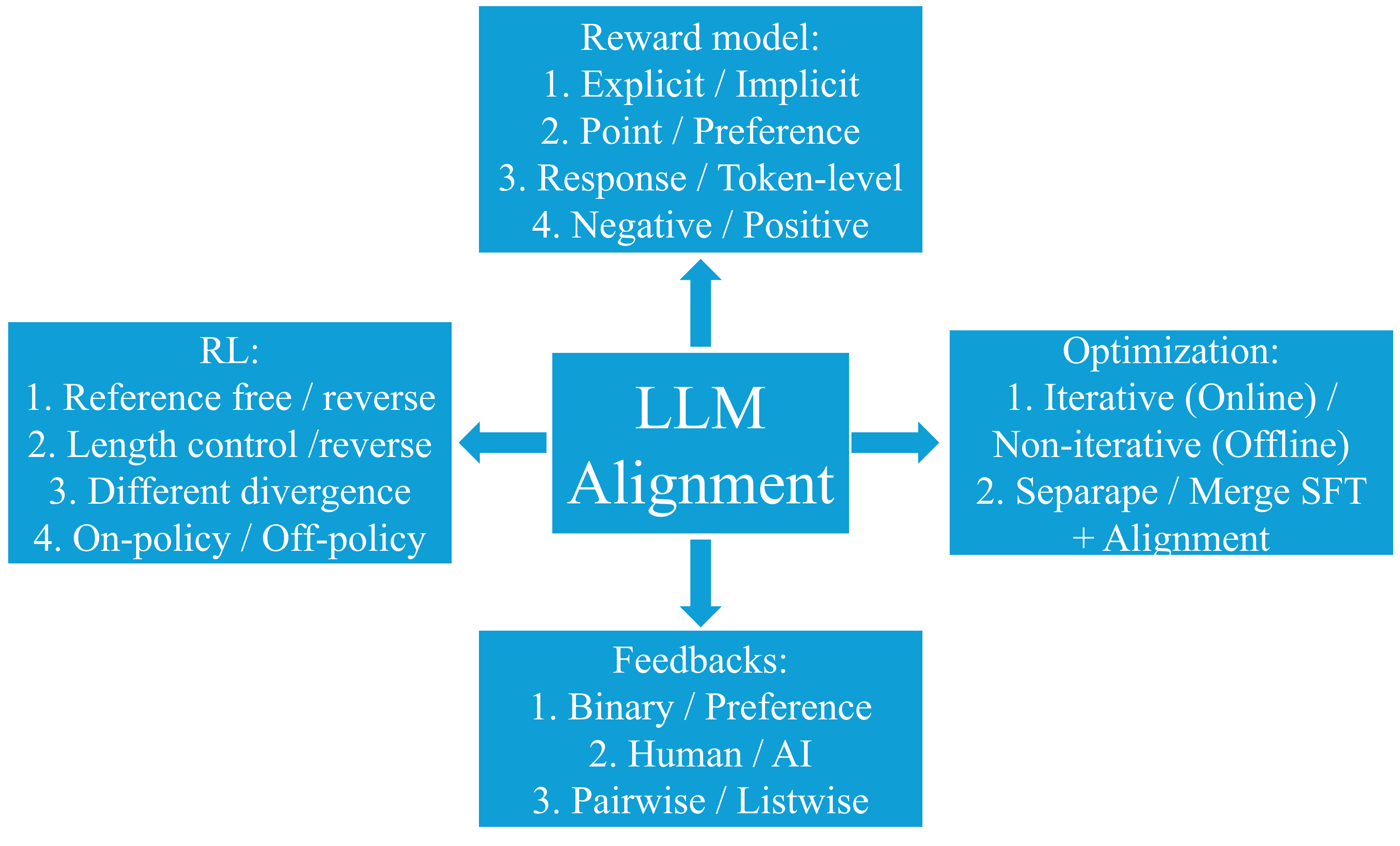
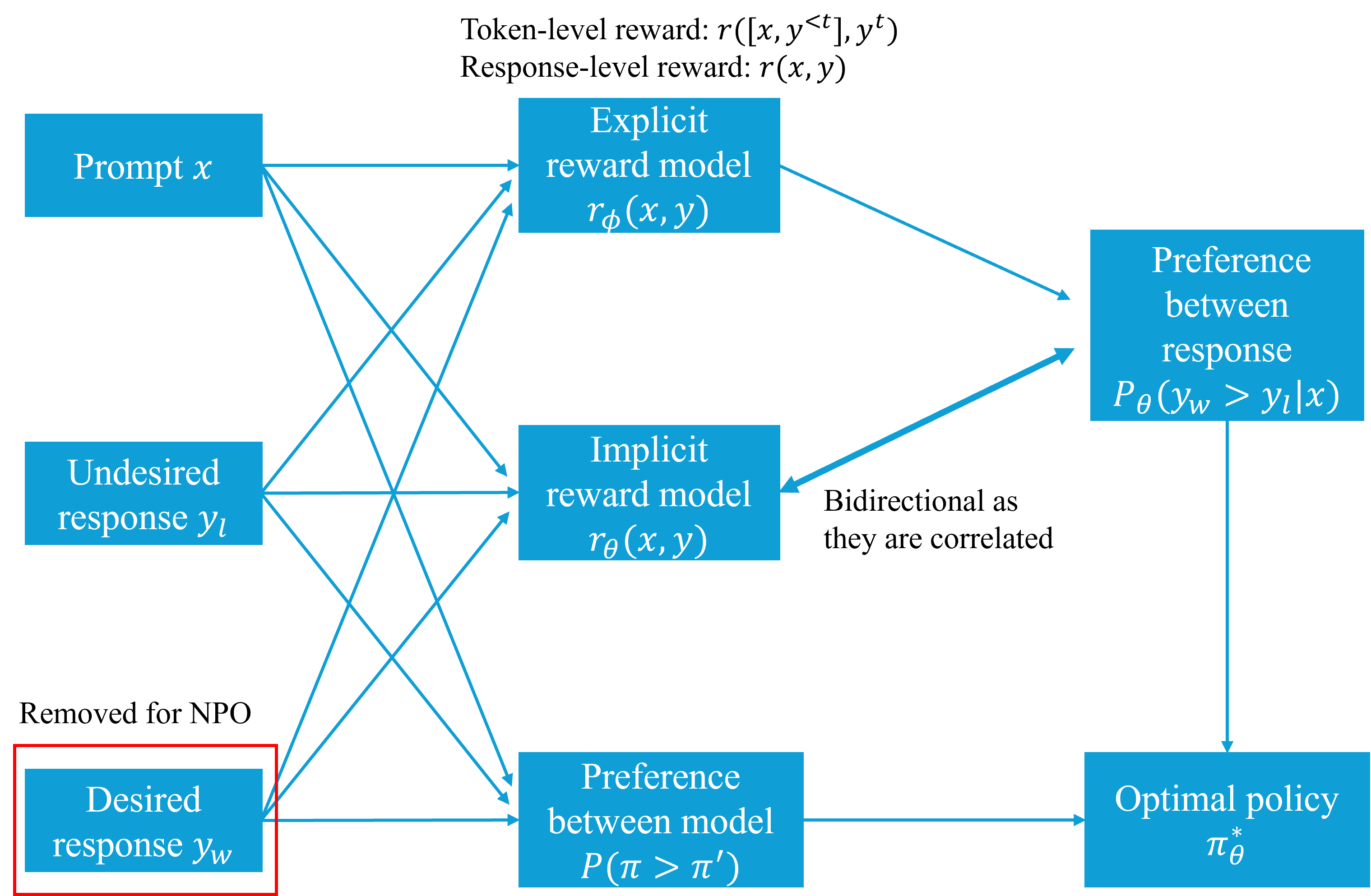
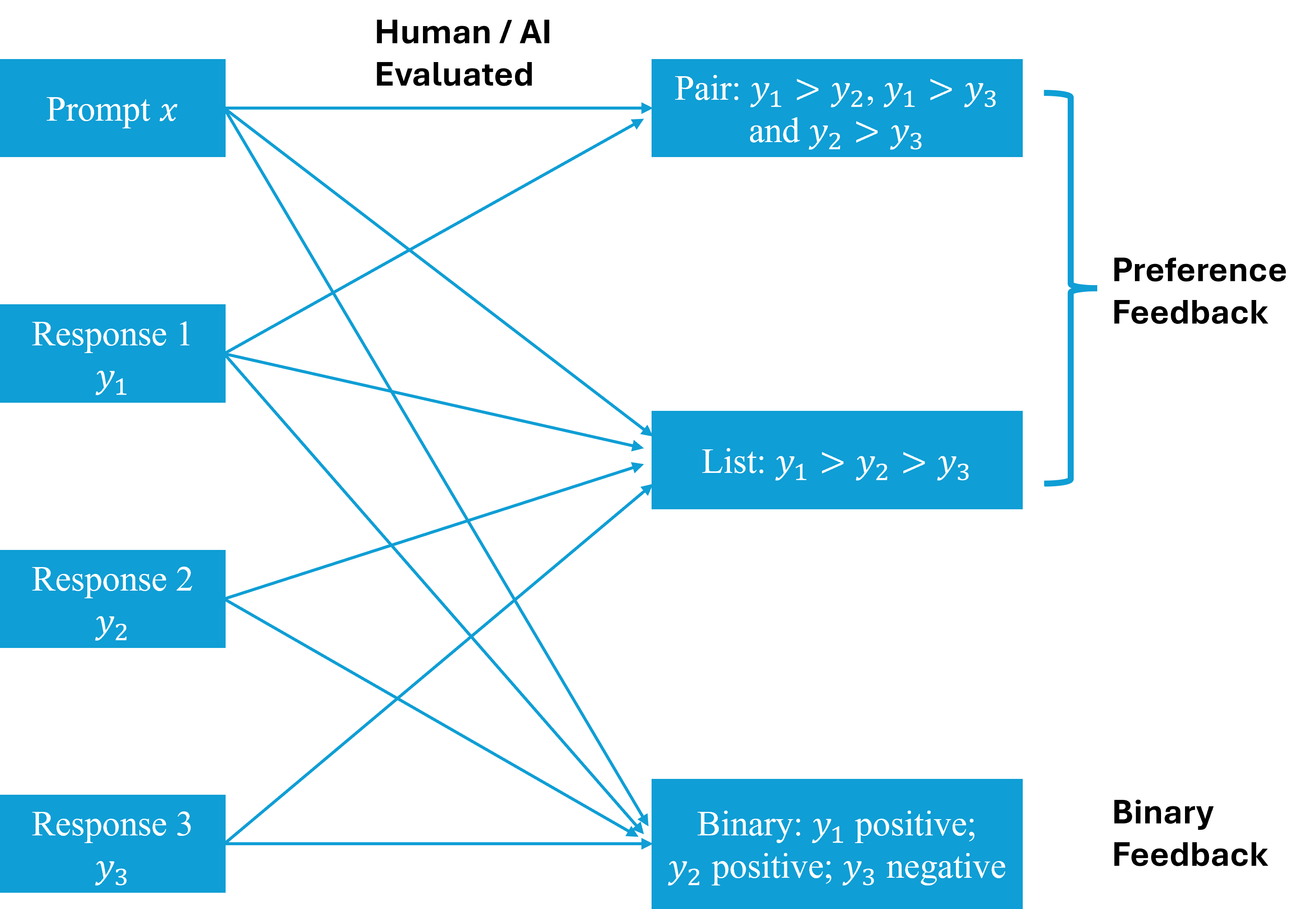
📊 实验亮点
该论文是一篇全面的LLM对齐技术综述,涵盖了RLHF、RLAIF、PPO、DPO等主流方法。它系统地整理和分析了各种对齐技术的原理、优缺点和适用场景,为研究人员和从业者提供了一个宝贵的参考资源。该论文没有提供具体的性能数据或提升幅度,因为它主要关注的是对现有技术的综述和分析。
🎯 应用场景
该研究成果可广泛应用于各种需要与人类意图对齐的LLM应用场景,例如智能客服、内容生成、对话系统等。通过选择合适的对齐技术,可以提高LLM生成文本的质量、安全性和可靠性,从而提升用户体验和应用价值。此外,该综述论文还可以为LLM对齐领域的研究提供指导,促进该领域的进一步发展。
📄 摘要(原文)
With advancements in self-supervised learning, the availability of trillions tokens in a pre-training corpus, instruction fine-tuning, and the development of large Transformers with billions of parameters, large language models (LLMs) are now capable of generating factual and coherent responses to human queries. However, the mixed quality of training data can lead to the generation of undesired responses, presenting a significant challenge. Over the past two years, various methods have been proposed from different perspectives to enhance LLMs, particularly in aligning them with human expectation. Despite these efforts, there has not been a comprehensive survey paper that categorizes and details these approaches. In this work, we aim to address this gap by categorizing these papers into distinct topics and providing detailed explanations of each alignment method, thereby helping readers gain a thorough understanding of the current state of the field.