DDK: Distilling Domain Knowledge for Efficient Large Language Models
作者: Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng
分类: cs.CL
发布日期: 2024-07-23
💡 一句话要点
DDK:通过领域知识蒸馏提升高效大语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大语言模型 领域知识 模型压缩 模型加速 动态数据集 性能优化
📋 核心要点
- 现有LLM蒸馏方法忽略了学生模型和教师模型在不同领域上的知识差异,导致蒸馏效率低下。
- DDK框架通过动态调整蒸馏数据集的领域组成,从而更有效地将知识从教师模型传递到学生模型。
- 实验结果表明,DDK显著提升了学生模型的性能,优于持续预训练和现有知识蒸馏方法。
📝 摘要(中文)
尽管大型语言模型(LLM)在各种应用中展现出先进的智能能力,但它们仍然面临着巨大的计算和存储需求。知识蒸馏(KD)已成为一种有效的策略,通过将知识从高性能的LLM(即教师模型)转移到较小的LLM(即学生模型),从而提高学生模型的性能。LLM蒸馏中的主流技术通常使用黑盒模型API来生成高质量的预训练和对齐数据集,或者通过改变损失函数来进行白盒蒸馏,以更好地从教师LLM传递知识。然而,这些方法忽略了学生和教师LLM在不同领域之间的知识差异。这导致过度关注性能差距最小的领域,而对差距大的领域关注不足,从而降低了整体性能。在本文中,我们提出了一种新的LLM蒸馏框架,称为DDK,它根据教师和学生模型之间的领域性能差异,以平滑的方式动态调整蒸馏数据集的组成,使蒸馏过程更加稳定和有效。广泛的评估表明,DDK显著提高了学生模型的性能,大大优于持续预训练基线和现有的知识蒸馏方法。
🔬 方法详解
问题定义:现有的大语言模型知识蒸馏方法,要么依赖黑盒API生成数据,要么通过修改损失函数进行白盒蒸馏。这些方法普遍忽略了教师模型和学生模型在不同领域上的能力差异。这意味着在一些学生模型已经表现良好的领域,仍然投入了过多的训练资源,而在学生模型表现较差的领域,却没有得到足够的关注。这导致整体蒸馏效率不高,学生模型的性能提升有限。
核心思路:DDK的核心思路是根据教师模型和学生模型在各个领域上的性能差异,动态地调整蒸馏数据集的领域构成。具体来说,DDK会更多地关注学生模型表现较差的领域,增加这些领域的数据在蒸馏数据集中的比例,从而更有针对性地提升学生模型的能力。这种动态调整策略使得蒸馏过程更加高效和稳定。
技术框架:DDK框架主要包含以下几个阶段:1) 领域性能评估:首先,评估教师模型和学生模型在各个领域上的性能。2) 数据集动态调整:然后,根据领域性能评估的结果,动态调整蒸馏数据集的领域构成,增加学生模型表现较差的领域的数据比例。3) 知识蒸馏:最后,使用调整后的蒸馏数据集对学生模型进行知识蒸馏训练。
关键创新:DDK最关键的创新在于其动态调整蒸馏数据集的领域构成。与传统的知识蒸馏方法不同,DDK不是静态地使用一个固定的数据集进行蒸馏,而是根据学生模型的实际表现,不断地调整数据集的构成,从而实现更高效的知识传递。
关键设计:DDK的关键设计包括:1) 领域性能评估指标的选择:选择合适的指标来准确评估教师模型和学生模型在各个领域上的性能至关重要。2) 数据集调整策略:如何根据领域性能差异来调整数据集的构成,需要仔细设计,以避免引入偏差或噪声。3) 平滑调整机制:为了保证蒸馏过程的稳定性,DDK采用了一种平滑的调整机制,避免数据集构成发生剧烈变化。
🖼️ 关键图片
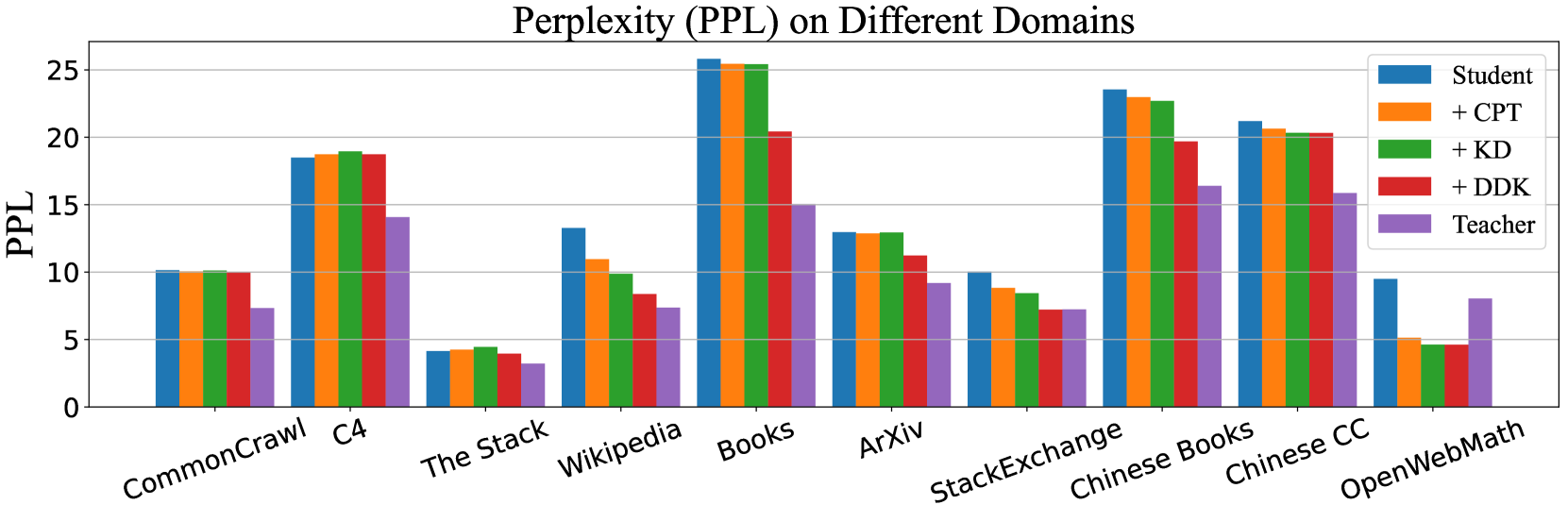

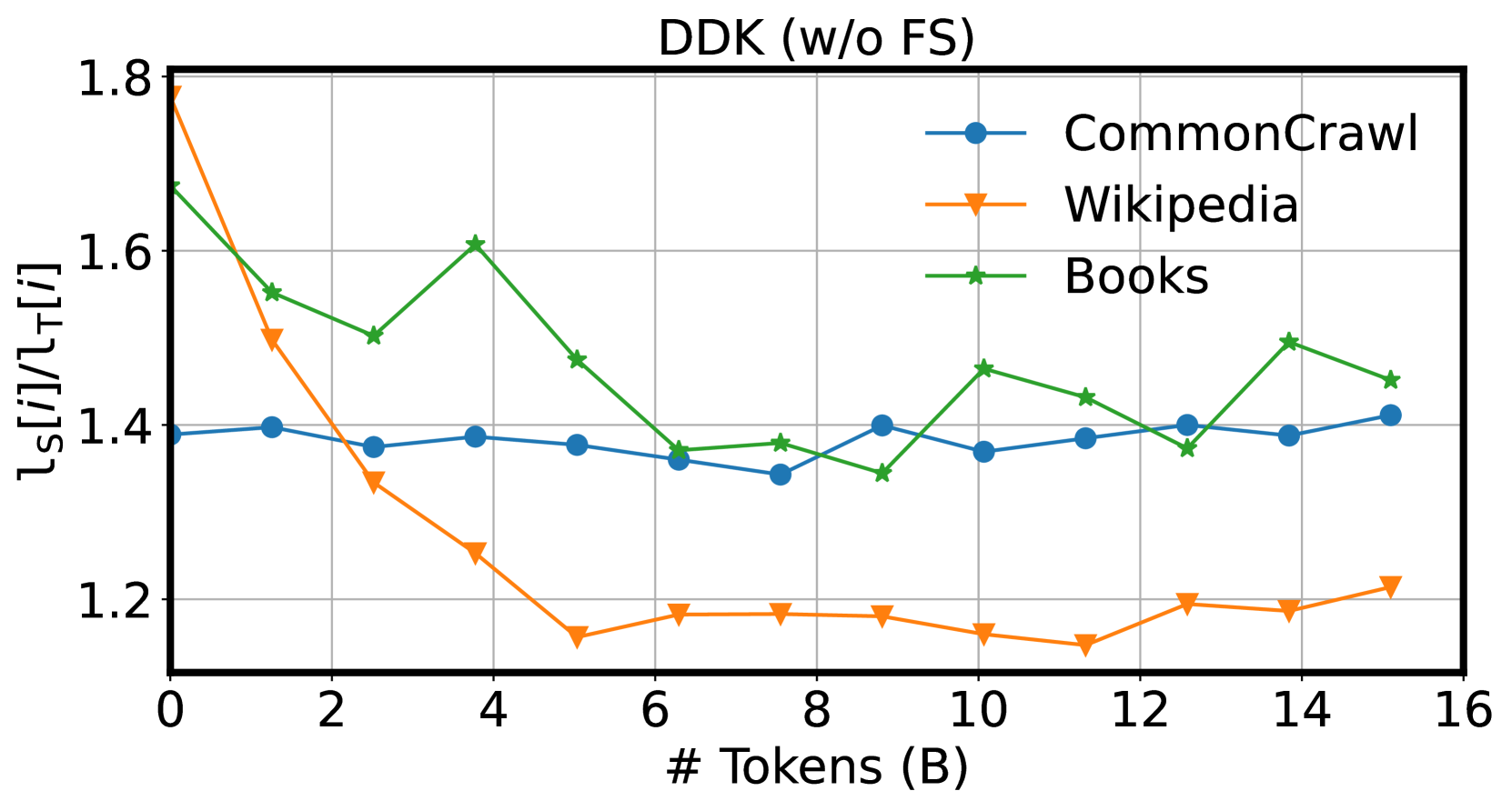
📊 实验亮点
实验结果表明,DDK框架在多个数据集上显著提升了学生模型的性能,大幅优于持续预训练基线和现有的知识蒸馏方法。具体的性能提升幅度取决于数据集和模型规模,但总体而言,DDK能够带来显著的性能提升,证明了其有效性。
🎯 应用场景
DDK框架可以广泛应用于各种需要对大型语言模型进行压缩和加速的场景,例如移动设备、边缘计算和资源受限的环境。通过知识蒸馏,可以将大型语言模型的知识迁移到小型模型,从而在保证性能的同时,降低计算和存储成本。这对于推动大语言模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.