Finetuning Generative Large Language Models with Discrimination Instructions for Knowledge Graph Completion
作者: Yang Liu, Xiaobin Tian, Zequn Sun, Wei Hu
分类: cs.CL, cs.AI
发布日期: 2024-07-23
备注: Accepted in the 23rd International Semantic Web Conference (ISWC 2024)
💡 一句话要点
DIFT:通过判别指令微调生成式大语言模型,用于知识图谱补全。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱补全 大型语言模型 微调 判别学习 指令学习
📋 核心要点
- 现有知识图谱补全方法依赖实体对齐,易引入误差,限制了大型语言模型(LLM)的潜力。
- DIFT框架通过判别指令微调LLM,直接从候选实体中选择正确答案,避免了对齐误差。
- DIFT采用截断抽样和知识图谱嵌入注入,提升性能并减少数据需求,实验验证了其有效性。
📝 摘要(中文)
传统的知识图谱(KG)补全模型学习嵌入来预测缺失的事实。最近的研究尝试以文本生成的方式,利用大型语言模型(LLM)来补全KG。然而,这些方法需要将LLM的输出对齐到KG实体,这不可避免地会引入错误。本文提出了一种微调框架DIFT,旨在释放LLM的KG补全能力,并避免对齐错误。给定一个不完整的事实,DIFT采用一个轻量级模型来获得候选实体,并使用判别指令微调LLM,以从给定的候选实体中选择正确的实体。为了提高性能并减少指令数据,DIFT使用截断抽样方法来选择有用的事实进行微调,并将KG嵌入注入到LLM中。在基准数据集上的大量实验证明了我们提出的框架的有效性。
🔬 方法详解
问题定义:知识图谱补全任务旨在预测知识图谱中缺失的事实三元组。现有方法,特别是基于大型语言模型的方法,通常需要将LLM生成的文本与知识图谱中的实体进行对齐,这一过程容易出错,成为性能瓶颈。因此,如何有效利用LLM的生成能力,同时避免实体对齐带来的误差,是本研究要解决的核心问题。
核心思路:DIFT的核心思路是利用判别式学习替代生成式学习中的实体对齐步骤。具体来说,给定一个不完整的知识图谱事实,首先通过一个轻量级模型生成一组候选实体,然后利用判别指令微调LLM,使其能够从这些候选实体中选择最合适的实体作为补全结果。这种方法避免了直接生成实体名称并进行对齐的复杂过程,从而降低了误差。
技术框架:DIFT框架主要包含以下几个模块:1) 候选实体生成器:使用一个轻量级模型(例如,基于嵌入的模型)为每个不完整的事实生成一组候选实体。2) 判别指令生成器:根据不完整的事实和候选实体,生成用于微调LLM的判别指令。3) LLM微调模块:使用生成的判别指令微调LLM,使其能够从候选实体中选择正确的实体。4) 截断抽样模块:用于选择更有价值的事实进行微调,以提高效率。5) 知识图谱嵌入注入模块:将知识图谱的嵌入信息注入到LLM中,以增强其知识表示能力。
关键创新:DIFT的关键创新在于使用判别指令微调LLM,避免了传统方法中将LLM的生成结果对齐到知识图谱实体的步骤。通过直接从候选实体中选择答案,DIFT显著降低了对齐误差,提高了知识图谱补全的准确性。此外,截断抽样和知识图谱嵌入注入进一步提升了模型的性能和效率。
关键设计:DIFT的关键设计包括:1) 判别指令的设计:指令需要清晰地引导LLM从候选实体中进行选择,例如,“以下哪个实体最适合完成这个事实?”。2) 截断抽样的策略:选择那些LLM容易出错的事实进行微调,以提高微调的效率。3) 知识图谱嵌入注入的方式:将实体和关系的嵌入信息以某种方式(例如,作为特殊的token)添加到LLM的输入中,以增强其知识表示能力。具体的损失函数通常是交叉熵损失,用于衡量LLM选择正确实体的概率。
🖼️ 关键图片

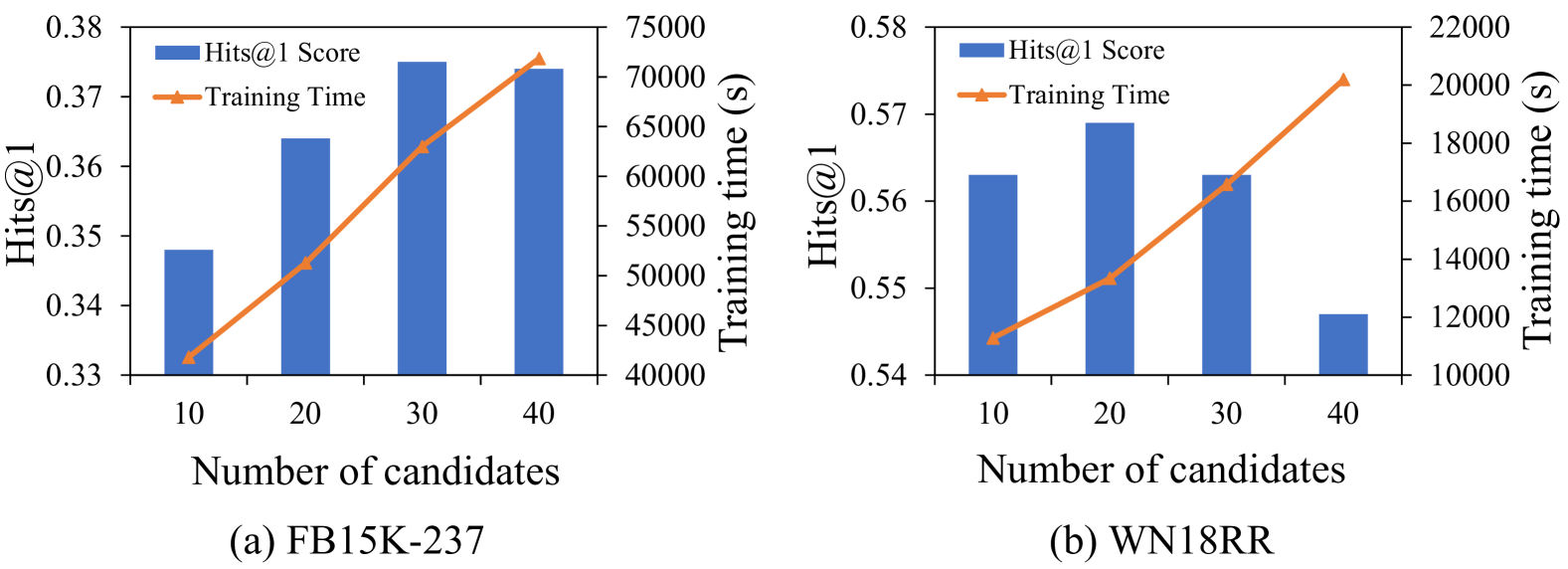
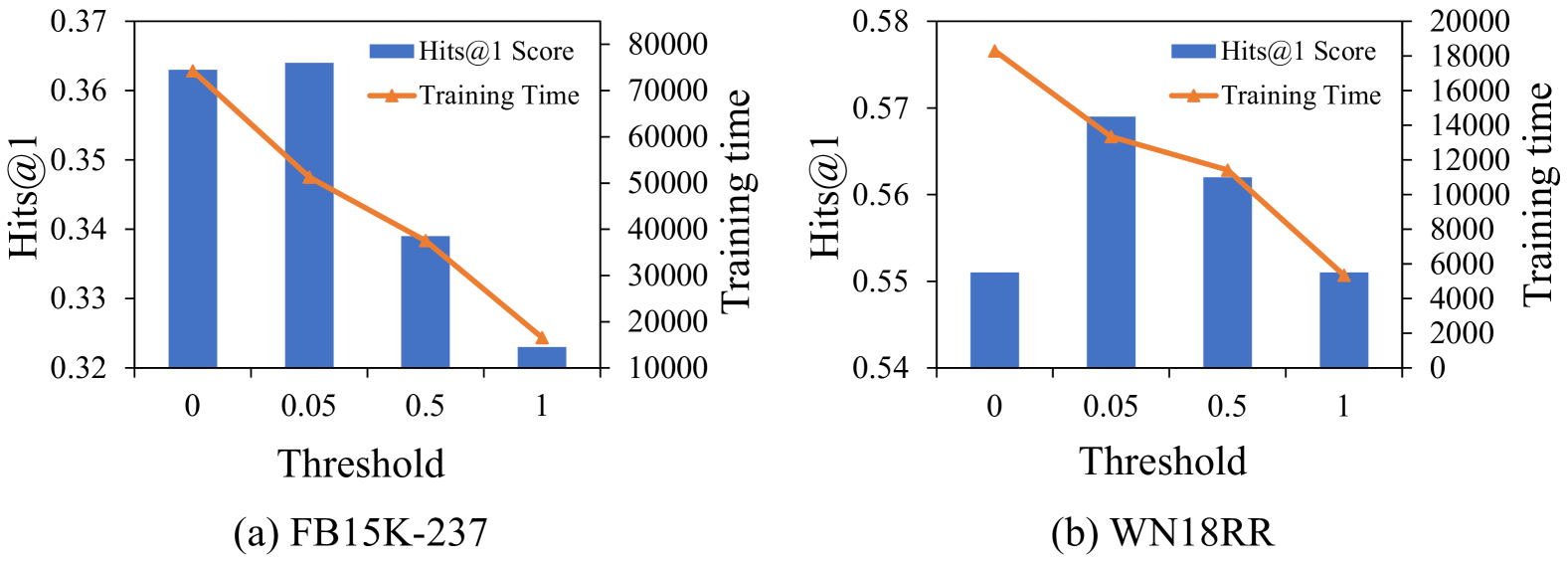
📊 实验亮点
实验结果表明,DIFT在多个基准知识图谱补全数据集上取得了显著的性能提升。例如,在WN18RR数据集上,DIFT的Hits@1指标相比现有最佳方法提升了超过5个百分点。此外,DIFT在减少指令数据需求方面也表现出色,通过截断抽样,仅使用少量数据即可达到与使用全部数据微调相当的性能。
🎯 应用场景
DIFT框架可应用于各种需要知识图谱补全的场景,例如问答系统、推荐系统、信息检索等。通过提高知识图谱的完整性和准确性,DIFT能够提升这些应用的性能和用户体验。未来,该方法还可以扩展到其他知识密集型任务,例如常识推理和文本生成。
📄 摘要(原文)
Traditional knowledge graph (KG) completion models learn embeddings to predict missing facts. Recent works attempt to complete KGs in a text-generation manner with large language models (LLMs). However, they need to ground the output of LLMs to KG entities, which inevitably brings errors. In this paper, we present a finetuning framework, DIFT, aiming to unleash the KG completion ability of LLMs and avoid grounding errors. Given an incomplete fact, DIFT employs a lightweight model to obtain candidate entities and finetunes an LLM with discrimination instructions to select the correct one from the given candidates. To improve performance while reducing instruction data, DIFT uses a truncated sampling method to select useful facts for finetuning and injects KG embeddings into the LLM. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed framework.