Leveraging Large Language Models to Geolocate Linguistic Variations in Social Media Posts
作者: Davide Savarro, Davide Zago, Stefano Zoia
分类: cs.CL, cs.AI
发布日期: 2024-07-22
🔗 代码/项目: GITHUB
💡 一句话要点
利用大型语言模型进行社交媒体帖子中语言变体的地理定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 地理定位 大型语言模型 社交媒体 意大利语 GeoLingIt挑战赛
📋 核心要点
- 社交媒体地理定位面临语言变体和非正式用语的挑战,现有方法难以准确捕捉这些细微差别。
- 本文提出微调预训练大型语言模型,使其能够同时预测区域和精确坐标,从而实现更精确的地理定位。
- 通过创新方法,模型能够更好地理解意大利社交媒体文本的细微差别,提升了地理定位的准确性。
📝 摘要(中文)
本文旨在利用大型语言模型(LLMs)解决社交媒体内容地理定位问题,即基于文本数据确定用户的地理位置,这些文本数据可能包含语言变体和非正式语言。具体而言,本文参与了GeoLingIt挑战赛,该挑战赛要求对意大利语推文进行地理定位,预测推文的区域和精确坐标。本文的方法包括对预训练的LLMs进行微调,以同时预测这些地理定位方面。通过整合创新方法,增强模型理解意大利社交媒体文本细微差别的能力,从而提高该领域的先进水平。这项工作是Bertinoro国际春季学校2024年大型语言模型课程的一部分。代码已在GitHub上公开。
🔬 方法详解
问题定义:本文旨在解决意大利语社交媒体推文的地理定位问题,具体来说,就是根据推文内容预测其所在的区域和精确坐标。现有方法在处理社交媒体文本中常见的语言变体、非正式用语和口语化表达时,定位精度往往不高,难以充分利用文本中的地理信息。
核心思路:本文的核心思路是利用大型语言模型(LLMs)强大的语言理解和生成能力,通过微调预训练的LLMs,使其能够学习到意大利语社交媒体文本中与地理位置相关的语言模式和特征。通过让模型同时预测区域和精确坐标,可以实现更准确的地理定位。
技术框架:本文的技术框架主要包括以下几个步骤:1) 数据预处理:对意大利语推文数据进行清洗、分词等预处理操作。2) 模型选择:选择合适的预训练LLM作为基础模型。3) 模型微调:使用GeoLingIt挑战赛提供的数据集对LLM进行微调,使其能够预测推文的区域和精确坐标。4) 模型评估:使用GeoLingIt挑战赛提供的评估指标对模型进行评估。
关键创新:本文的关键创新在于将大型语言模型应用于意大利语社交媒体推文的地理定位任务,并提出了一种同时预测区域和精确坐标的微调方法。这种方法能够更好地利用文本中的地理信息,提高地理定位的准确性。
关键设计:具体的模型选择和微调策略未知,论文中未详细说明。损失函数和网络结构等技术细节也未提及。推测可能使用了交叉熵损失函数进行区域预测,以及均方误差损失函数进行坐标预测,但具体细节需要参考代码。
🖼️ 关键图片
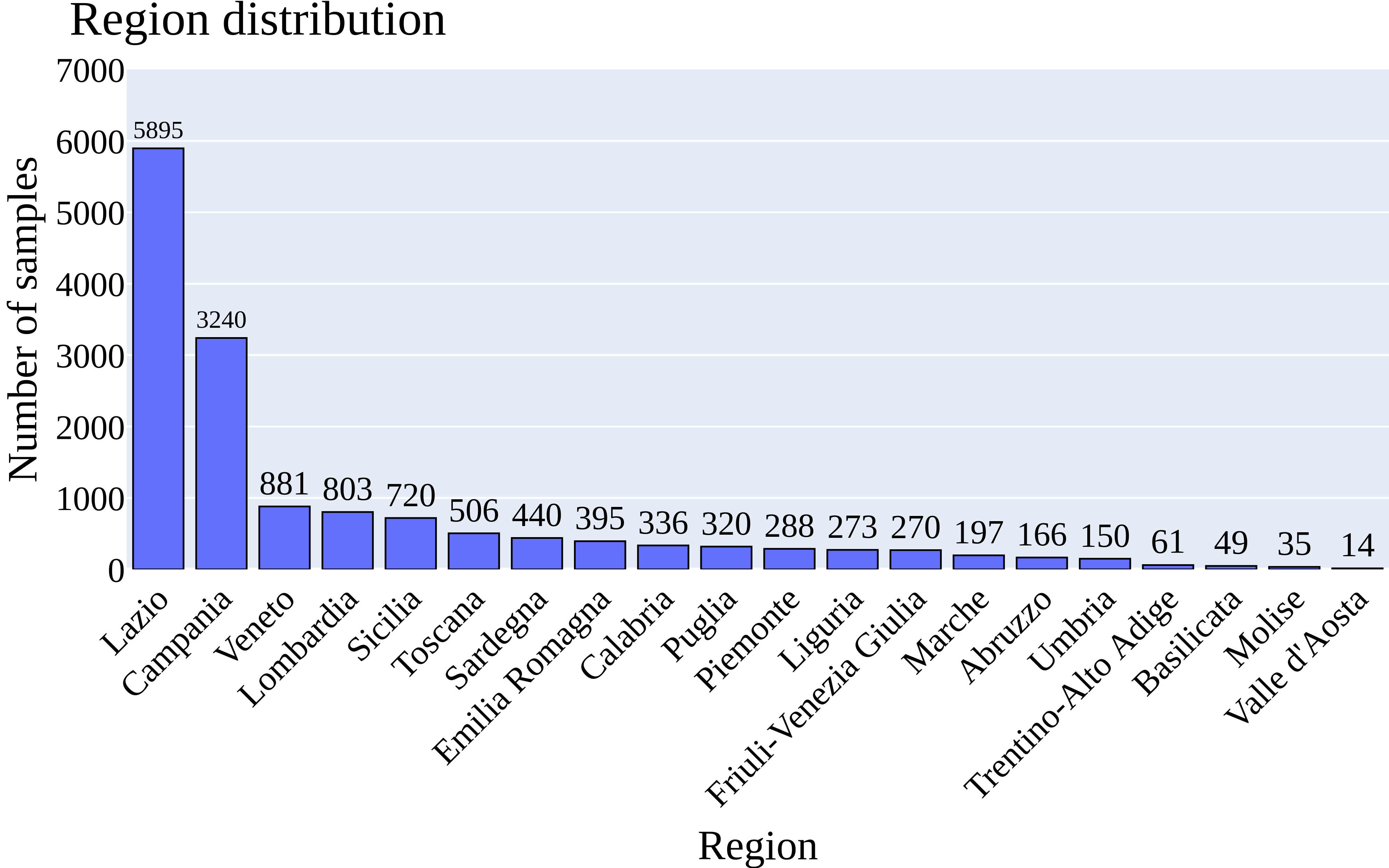


📊 实验亮点
由于论文是课程项目,摘要中没有提供具体的实验结果和性能数据。虽然提到“提高该领域的先进水平”,但缺乏量化指标和对比基线,无法评估提升幅度。具体的实验亮点未知。
🎯 应用场景
该研究成果可应用于社交媒体内容分析、舆情监控、灾害预警等领域。通过准确地定位社交媒体用户的地理位置,可以更好地了解社会动态、预测突发事件,并为政府决策提供支持。未来,该技术还可以扩展到其他语言和社交媒体平台,具有广阔的应用前景。
📄 摘要(原文)
Geolocalization of social media content is the task of determining the geographical location of a user based on textual data, that may show linguistic variations and informal language. In this project, we address the GeoLingIt challenge of geolocalizing tweets written in Italian by leveraging large language models (LLMs). GeoLingIt requires the prediction of both the region and the precise coordinates of the tweet. Our approach involves fine-tuning pre-trained LLMs to simultaneously predict these geolocalization aspects. By integrating innovative methodologies, we enhance the models' ability to understand the nuances of Italian social media text to improve the state-of-the-art in this domain. This work is conducted as part of the Large Language Models course at the Bertinoro International Spring School 2024. We make our code publicly available on GitHub https://github.com/dawoz/geolingit-biss2024.