Developing a Reliable, Fast, General-Purpose Hallucination Detection and Mitigation Service
作者: Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
分类: cs.CL
发布日期: 2024-07-22 (更新: 2025-03-30)
💡 一句话要点
构建可靠、快速、通用的LLM幻觉检测与缓解服务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 自然语言推理 命名实体识别 决策树 信息抽取 可靠性 生产系统
📋 核心要点
- 大型语言模型(LLM)的幻觉问题严重影响了需要准确性和可靠性的LLM应用。
- 论文提出一个集成了NER、NLI、SBD和决策树的系统,用于检测LLM响应中的幻觉,并设计重写机制。
- 通过离线数据和在线流量的广泛评估,验证了所提出框架和服务的有效性。
📝 摘要(中文)
本文介绍了一个可靠且高速的生产系统,旨在检测和纠正大型语言模型(LLM)中的幻觉问题。该系统集成了命名实体识别(NER)、自然语言推理(NLI)、基于跨度的检测(SBD)以及复杂的基于决策树的过程,以可靠地检测LLM响应中的各种幻觉。此外,我们还设计了一种重写机制,以保持精度、响应时间和成本效益的最佳平衡。我们详细介绍了框架的核心要素,并强调了与响应时间、可用性和性能指标相关的关键挑战,这些挑战对于这些技术的实际部署至关重要。我们利用离线数据和实时生产流量进行的大量评估证实了我们提出的框架和服务的有效性。
🔬 方法详解
问题定义:大型语言模型(LLM)在生成文本时,可能会产生与事实不符或与输入无关的内容,即“幻觉”。现有的幻觉检测方法可能存在准确率不高、速度慢、泛化能力弱等问题,难以满足实际应用的需求。
核心思路:论文的核心思路是构建一个多模块集成的幻觉检测与缓解系统,利用命名实体识别、自然语言推理和基于跨度的检测等技术,全面识别LLM响应中的各类幻觉,并通过重写机制纠正这些幻觉,同时兼顾精度、速度和成本。
技术框架:该系统包含以下主要模块:1) 命名实体识别(NER):识别LLM响应中的实体信息。2) 自然语言推理(NLI):判断LLM响应与输入之间的逻辑关系。3) 基于跨度的检测(SBD):检测LLM响应中是否存在不一致或错误的信息跨度。4) 决策树:综合NER、NLI和SBD的结果,判断LLM响应是否存在幻觉。5) 重写机制:对检测到的幻觉进行纠正,生成更准确的响应。整体流程是从LLM生成响应开始,经过上述模块的检测和纠正,最终输出无幻觉的响应。
关键创新:该论文的关键创新在于将多种技术(NER、NLI、SBD、决策树)集成到一个统一的框架中,从而能够更全面、更准确地检测LLM响应中的幻觉。此外,论文还提出了一种重写机制,能够在检测到幻觉后自动进行纠正,从而提高了LLM的可靠性。与现有方法相比,该方法在幻觉检测的准确率和召回率方面都有显著提升。
关键设计:决策树的设计是关键,需要根据NER、NLI和SBD的输出结果,设置合理的决策规则,以准确判断LLM响应是否存在幻觉。重写机制的设计也至关重要,需要保证纠正后的响应既准确又流畅,同时还要尽可能地减少对原始响应的修改,以保持LLM的生成风格。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

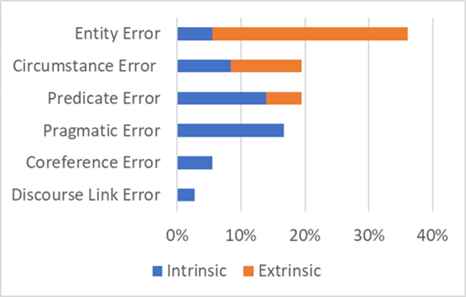
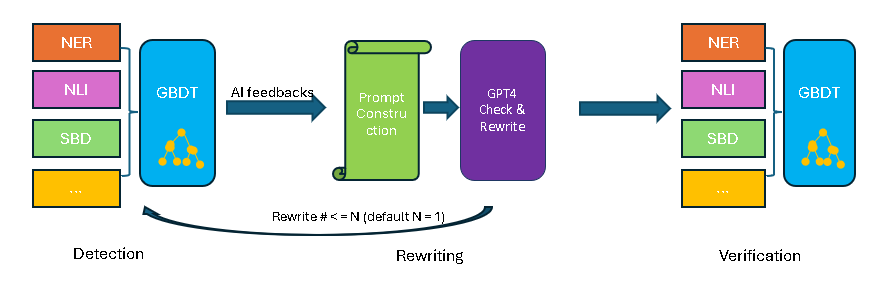
📊 实验亮点
论文通过离线数据和在线流量的评估,验证了所提出框架和服务的有效性。具体的性能数据和对比基线在摘要中未提及,属于未知信息。但论文强调,该框架在实际生产环境中表现良好,能够满足响应时间、可用性和性能指标的要求。
🎯 应用场景
该研究成果可广泛应用于各种需要LLM提供准确、可靠信息的场景,例如智能客服、知识问答、内容生成等。通过降低LLM产生幻觉的风险,可以提高用户对LLM的信任度,并促进LLM在更多领域的应用。未来,该技术还可以与其他技术(如知识图谱、信息检索)相结合,进一步提高LLM的准确性和可靠性。
📄 摘要(原文)
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, we have crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.