ALLaM: Large Language Models for Arabic and English
作者: M Saiful Bari, Yazeed Alnumay, Norah A. Alzahrani, Nouf M. Alotaibi, Hisham A. Alyahya, Sultan AlRashed, Faisal A. Mirza, Shaykhah Z. Alsubaie, Hassan A. Alahmed, Ghadah Alabduljabbar, Raghad Alkhathran, Yousef Almushayqih, Raneem Alnajim, Salman Alsubaihi, Maryam Al Mansour, Majed Alrubaian, Ali Alammari, Zaki Alawami, Abdulmohsen Al-Thubaity, Ahmed Abdelali, Jeril Kuriakose, Abdalghani Abujabal, Nora Al-Twairesh, Areeb Alowisheq, Haidar Khan
分类: cs.CL, cs.AI
发布日期: 2024-07-22
💡 一句话要点
ALLaM:面向阿拉伯语和英语的大型语言模型,提升多语言环境下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 阿拉伯语 多语言学习 知识迁移 语言对齐 人类偏好对齐 自回归模型
📋 核心要点
- 现有阿拉伯语大型语言模型在语言对齐和知识迁移方面存在不足,限制了其在多语言环境下的性能。
- ALLaM通过词汇扩展和混合语料预训练,实现了从英语到阿拉伯语的知识迁移,同时避免了灾难性遗忘。
- 实验表明,与人类偏好对齐能显著提升模型性能,ALLaM在多个阿拉伯语基准测试中达到SOTA。
📝 摘要(中文)
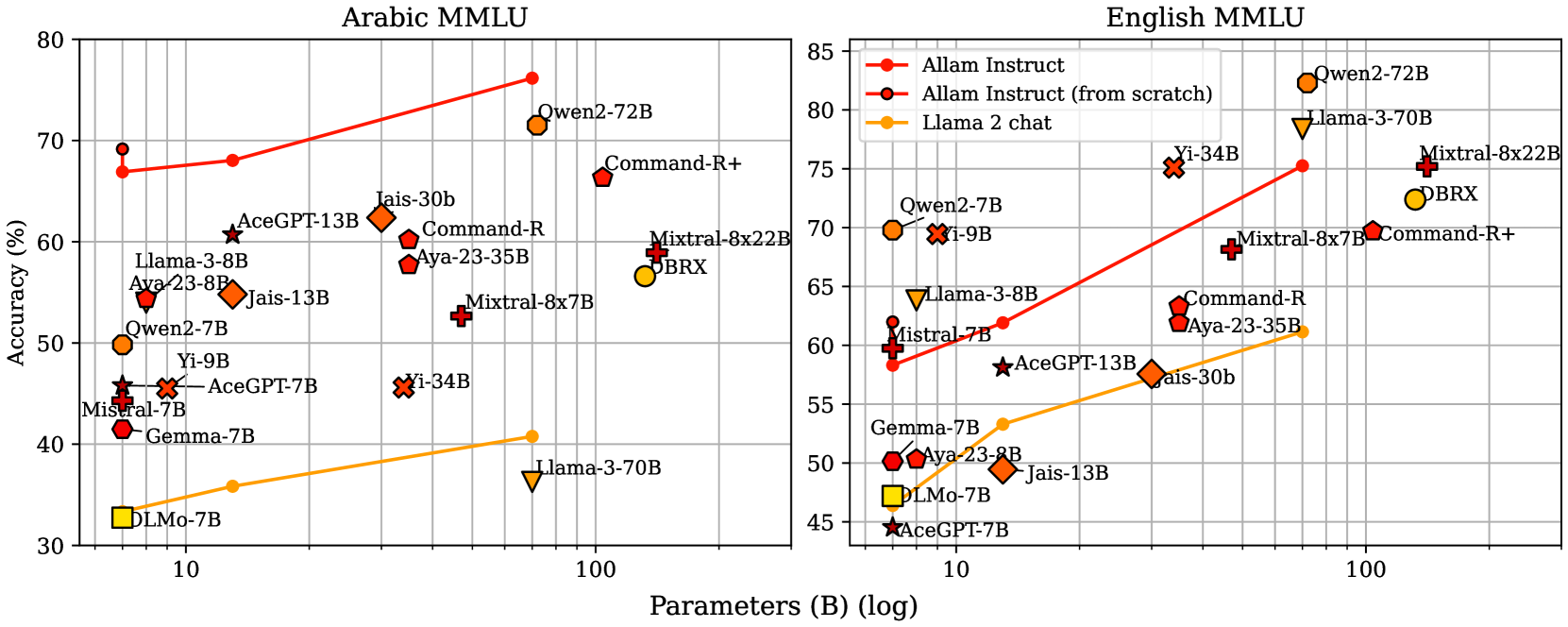
本文介绍了ALLaM,一系列用于支持阿拉伯语技术生态系统的大型语言模型。ALLaM在训练时充分考虑了语言对齐和大规模知识迁移的价值。我们的自回归解码器架构模型展示了如何通过词汇扩展和在阿拉伯语和英语混合文本上的预训练,引导模型学习一种新语言(阿拉伯语),而不会对原始语言(英语)产生灾难性遗忘。此外,我们强调了使用并行/翻译数据来帮助语言之间知识对齐过程的有效性。最后,我们表明,与规模更大但对齐质量较低的模型相比,与人类偏好的广泛对齐可以显著提高语言模型的性能。ALLaM在各种阿拉伯语基准测试中取得了最先进的性能,包括MMLU Arabic、ACVA和Arabic Exams。我们对齐后的模型在阿拉伯语和英语方面的性能均优于其基础对齐模型。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语大型语言模型在多语言环境下的性能问题。现有方法通常难以在学习新语言的同时保持原有语言的性能,并且缺乏有效的知识迁移和对齐策略。这导致模型在阿拉伯语任务上的表现不佳,无法充分利用已有的英语知识。
核心思路:论文的核心思路是通过词汇扩展和混合语料预训练,实现从英语到阿拉伯语的知识迁移,同时避免灾难性遗忘。此外,利用并行/翻译数据来辅助语言之间的知识对齐,并采用与人类偏好对齐的方法来提升模型性能。
技术框架:ALLaM采用自回归解码器架构。训练过程包括以下几个阶段:首先,进行词汇扩展,将阿拉伯语词汇添加到现有英语模型的词汇表中。然后,在混合了阿拉伯语和英语的语料库上进行预训练。接着,使用并行/翻译数据进行知识对齐。最后,通过与人类偏好对齐来优化模型。
关键创新:该论文的关键创新在于:1) 提出了一种有效的知识迁移方法,可以在学习新语言的同时保持原有语言的性能;2) 强调了使用并行/翻译数据进行知识对齐的重要性;3) 证明了与人类偏好对齐可以显著提高语言模型的性能,即使模型规模较小。
关键设计:ALLaM的关键设计包括:1) 精心设计的混合语料库,包含大量的阿拉伯语和英语文本;2) 使用并行/翻译数据进行知识对齐,例如使用机器翻译系统生成的平行语料;3) 采用强化学习等方法进行与人类偏好对齐,例如使用人类反馈来训练奖励模型,然后使用该奖励模型来优化语言模型。
🖼️ 关键图片


📊 实验亮点
ALLaM在多个阿拉伯语基准测试中取得了最先进的性能,包括MMLU Arabic、ACVA和Arabic Exams。与规模更大但对齐质量较低的模型相比,ALLaM通过与人类偏好对齐,显著提高了性能。此外,对齐后的模型在阿拉伯语和英语方面的性能均优于其基础对齐模型,表明该方法能够有效地提升多语言环境下的性能。
🎯 应用场景
ALLaM的应用场景广泛,包括但不限于:阿拉伯语自然语言处理、机器翻译、跨语言信息检索、阿拉伯语内容生成、教育和文化传承等。该研究的实际价值在于提升阿拉伯语技术生态系统的能力,促进阿拉伯语在数字世界的应用和发展。未来,ALLaM可以作为基础模型,进一步应用于各种下游任务,并促进更多阿拉伯语相关的研究。
📄 摘要(原文)
We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.