Compact Language Models via Pruning and Knowledge Distillation
作者: Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-07-19 (更新: 2024-11-04)
💡 一句话要点
通过剪枝与知识蒸馏构建紧凑型语言模型,降低训练成本并提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型压缩 剪枝 知识蒸馏 模型优化 深度学习 自然语言处理 模型部署
📋 核心要点
- 现有LLM通常针对不同规模从头训练,计算成本高昂,缺乏效率。
- 提出一种结合剪枝和知识蒸馏的压缩方法,在少量数据上再训练,显著降低训练成本。
- 实验表明,该方法在压缩模型的同时,性能可与现有模型媲美,甚至有所提升。
📝 摘要(中文)
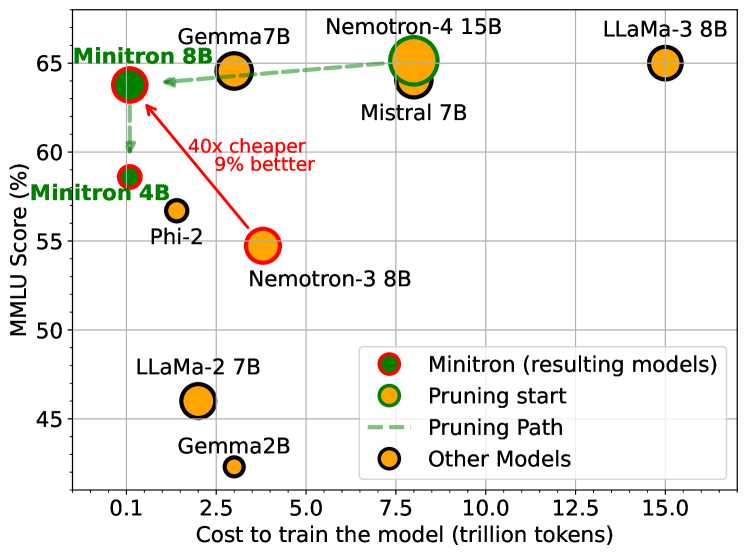
本文探讨了通过剪枝现有大型语言模型(LLM),然后使用少量(<3%)原始训练数据进行再训练,作为重复完全再训练的一种替代方案的可行性。为此,我们为LLM开发了一套实用有效的压缩最佳实践,将深度、宽度、注意力力和MLP剪枝与基于知识蒸馏的再训练相结合。通过对每个轴的剪枝策略、组合轴的方法、蒸馏策略以及寻找最佳压缩架构的搜索技术进行详细的实证探索,我们得出了这些最佳实践。我们使用该指南将Nemotron-4系列的LLM压缩了2-4倍,并将其性能与各种语言建模任务中类似大小的模型进行了比较。与从头开始训练相比,使用我们的方法从已预训练的15B模型派生出8B和4B模型,每个模型所需的训练tokens减少了高达40倍;这使得训练整个模型系列(15B、8B和4B)的计算成本节省了1.8倍。与从头开始训练相比,Minitron模型在MMLU分数上提高了高达16%,与其他社区模型(如Mistral 7B、Gemma 7B和Llama-3 8B)的性能相当,并且优于文献中最先进的压缩技术。我们已经在Huggingface上开源了Minitron模型权重,并在GitHub上提供了相应的补充材料,包括示例代码。
🔬 方法详解
问题定义:论文旨在解决大型语言模型训练成本高昂的问题。现有方法通常需要针对不同大小的模型从头开始训练,这需要大量的计算资源和数据。此外,如何有效地压缩模型,同时保持其性能也是一个挑战。
核心思路:论文的核心思路是通过剪枝预训练的大型语言模型,然后使用少量数据进行知识蒸馏再训练。这种方法避免了从头开始训练,显著降低了计算成本。剪枝用于减少模型参数量,知识蒸馏则用于将原始模型的知识迁移到压缩后的模型中,以保持其性能。
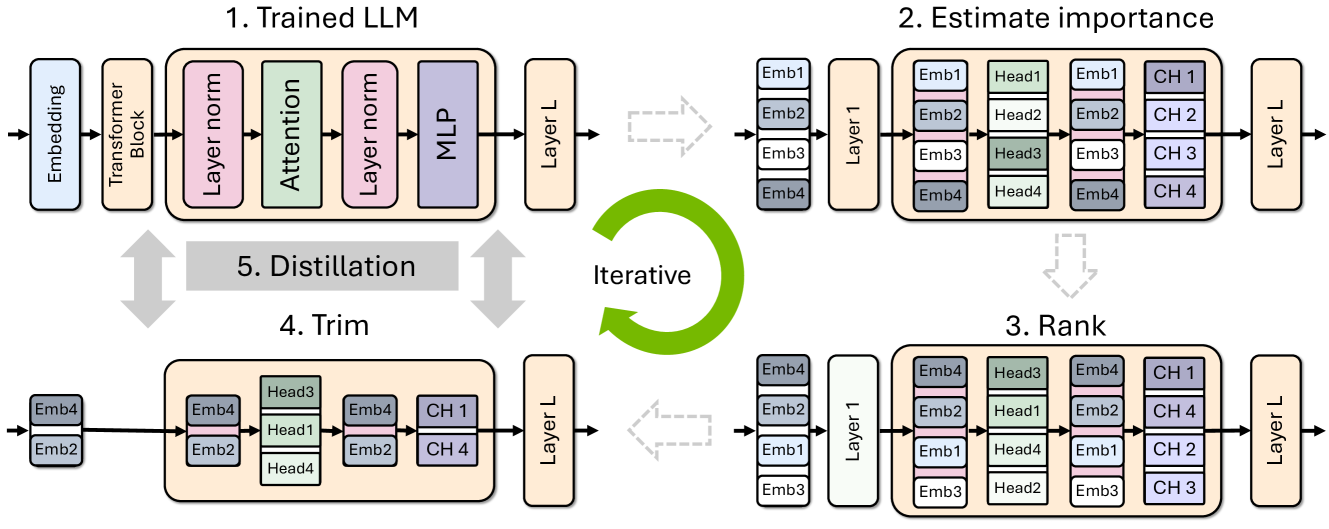
技术框架:整体流程包括以下几个阶段:1) 对预训练的LLM进行剪枝,包括深度、宽度、注意力力和MLP剪枝;2) 选择合适的知识蒸馏策略;3) 使用少量原始训练数据对剪枝后的模型进行再训练;4) 通过搜索技术找到最佳的压缩架构。该框架旨在找到在模型大小和性能之间取得最佳平衡的压缩模型。
关键创新:该方法最重要的创新点在于结合了多种剪枝策略和知识蒸馏技术,并探索了它们之间的最佳组合方式。通过对不同剪枝策略、蒸馏策略和搜索技术的详细实证研究,找到了一套适用于LLM压缩的实用有效的最佳实践。
关键设计:论文详细探讨了不同类型的剪枝策略(深度、宽度、注意力力和MLP剪枝)以及它们对模型性能的影响。同时,研究了不同的知识蒸馏策略,包括如何选择合适的教师模型和损失函数。此外,论文还使用了搜索技术来寻找最佳的压缩架构,例如不同层的剪枝比例。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用该方法压缩后的Minitron模型在MMLU分数上比从头开始训练的模型提高了高达16%。同时,Minitron模型的性能与其他社区模型(如Mistral 7B、Gemma 7B和Llama-3 8B)相当,并且优于文献中最先进的压缩技术。此外,该方法使得训练整个模型家族(15B、8B和4B)的计算成本节省了1.8倍。
🎯 应用场景
该研究成果可广泛应用于需要部署大型语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过压缩模型,可以降低部署成本,提高推理速度,并使得LLM能够在更多设备上运行。此外,该方法还可以用于构建模型家族,针对不同的应用场景提供不同大小的模型。
📄 摘要(原文)
Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we investigate if pruning an existing LLM and then re-training it with a fraction (<3%) of the original training data can be a suitable alternative to repeated, full retraining. To this end, we develop a set of practical and effective compression best practices for LLMs that combine depth, width, attention and MLP pruning with knowledge distillation-based retraining; we arrive at these best practices through a detailed empirical exploration of pruning strategies for each axis, methods to combine axes, distillation strategies, and search techniques for arriving at optimal compressed architectures. We use this guide to compress the Nemotron-4 family of LLMs by a factor of 2-4x, and compare their performance to similarly-sized models on a variety of language modeling tasks. Deriving 8B and 4B models from an already pretrained 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. We have open-sourced Minitron model weights on Huggingface, with corresponding supplementary material including example code available on GitHub.