Adversarial Databases Improve Success in Retrieval-based Large Language Models
作者: Sean Wu, Michael Koo, Li Yo Kao, Andy Black, Lesley Blum, Fabien Scalzo, Ira Kurtz
分类: cs.CL
发布日期: 2024-07-19
备注: 24 pages, 3 figures, 11 tables
💡 一句话要点
对抗性数据库提升了基于检索的大语言模型在医学问答中的成功率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大语言模型 对抗性信息 医学问答 零样本学习
📋 核心要点
- 现有研究普遍认为,在RAG中引入对抗性背景信息会降低LLM的性能,甚至产生负面影响。
- 该研究反直觉地发现,在RAG中引入对抗性信息(如圣经文本和随机单词)可以显著提高LLM在医学问答中的成功率。
- 实验结果表明,多个开源LLM在对抗性信息的辅助下,多项选择题的正确率得到了提升,挑战了传统认知。
📝 摘要(中文)
开源大语言模型(LLM)在微调聊天机器人方面展现出巨大潜力,并在推理能力上超越了许多现有基准。检索增强生成(RAG)是一种通过利用外部知识数据库来提高LLM在未明确训练任务上的性能的技术。大量研究表明,当使用包含相关背景信息的向量数据集时,RAG能更成功地完成下游任务。该领域的研究者们普遍认为,如果使用对抗性背景信息,RAG的效果将不存在甚至产生负面影响。为了验证这一假设,我们测试了多个开源LLM在RAG的辅助下,回答肾脏病医学专业多项选择题(MCQ)的能力。与以往研究不同,我们考察了RAG在使用相关和对抗性背景数据库时的效果。我们设置了包括Llama 3、Phi-3、Mixtral 8x7b、Zephyr$β$和Gemma 7B Instruct在内的多个开源LLM,采用零样本RAG流程。圣经文本和随机单词生成数据库被用作对抗性信息来源进行比较。我们的数据显示,正如预期的那样,大多数开源LLM在结合相关信息向量数据库时,其多项选择题的成功率有所提高。然而,令人惊讶的是,对抗性的圣经文本显著提高了许多LLM的成功率,甚至随机单词文本也提高了某些模型的测试能力。总而言之,我们的结果首次展示了对抗性信息数据集提高基于RAG的LLM成功率的反直觉能力。
🔬 方法详解
问题定义:论文旨在研究在检索增强生成(RAG)框架下,对抗性背景信息对大语言模型(LLM)性能的影响。现有研究普遍认为,RAG依赖于相关背景知识,而对抗性信息会干扰模型的判断,降低其性能。然而,这种假设缺乏充分的实验验证,并且可能忽略了对抗性信息在特定场景下的潜在价值。
核心思路:论文的核心思路是挑战“对抗性信息有害”的传统认知,通过实验验证对抗性信息在RAG框架下对LLM性能的实际影响。作者认为,对抗性信息可能通过某种机制,例如增加模型的鲁棒性或提供意想不到的上下文线索,来提升模型的表现。
技术框架:该研究采用零样本RAG流程,主要包含以下几个阶段:1) 构建相关和对抗性背景知识数据库;2) 针对给定的医学多项选择题,利用RAG从数据库中检索相关信息;3) 将检索到的信息与问题一起输入LLM;4) LLM生成答案;5) 评估LLM的答案正确率。使用的LLM包括Llama 3、Phi-3、Mixtral 8x7b、Zephyr$β$和Gemma 7B Instruct。对抗性信息来源包括圣经文本和随机单词生成数据库。
关键创新:该研究最重要的技术创新点在于,它首次揭示了对抗性信息数据集在RAG框架下提升LLM性能的反直觉能力。与以往研究不同,该研究没有简单地假设对抗性信息有害,而是通过实验验证了其潜在的积极作用。
关键设计:该研究的关键设计包括:1) 选择医学多项选择题作为评估任务,以确保任务的专业性和难度;2) 使用圣经文本和随机单词生成数据库作为对抗性信息来源,以确保对抗性信息的随机性和多样性;3) 采用零样本RAG流程,以避免模型对特定背景知识的过度依赖;4) 评估多个开源LLM的性能,以确保结果的普遍性。
🖼️ 关键图片


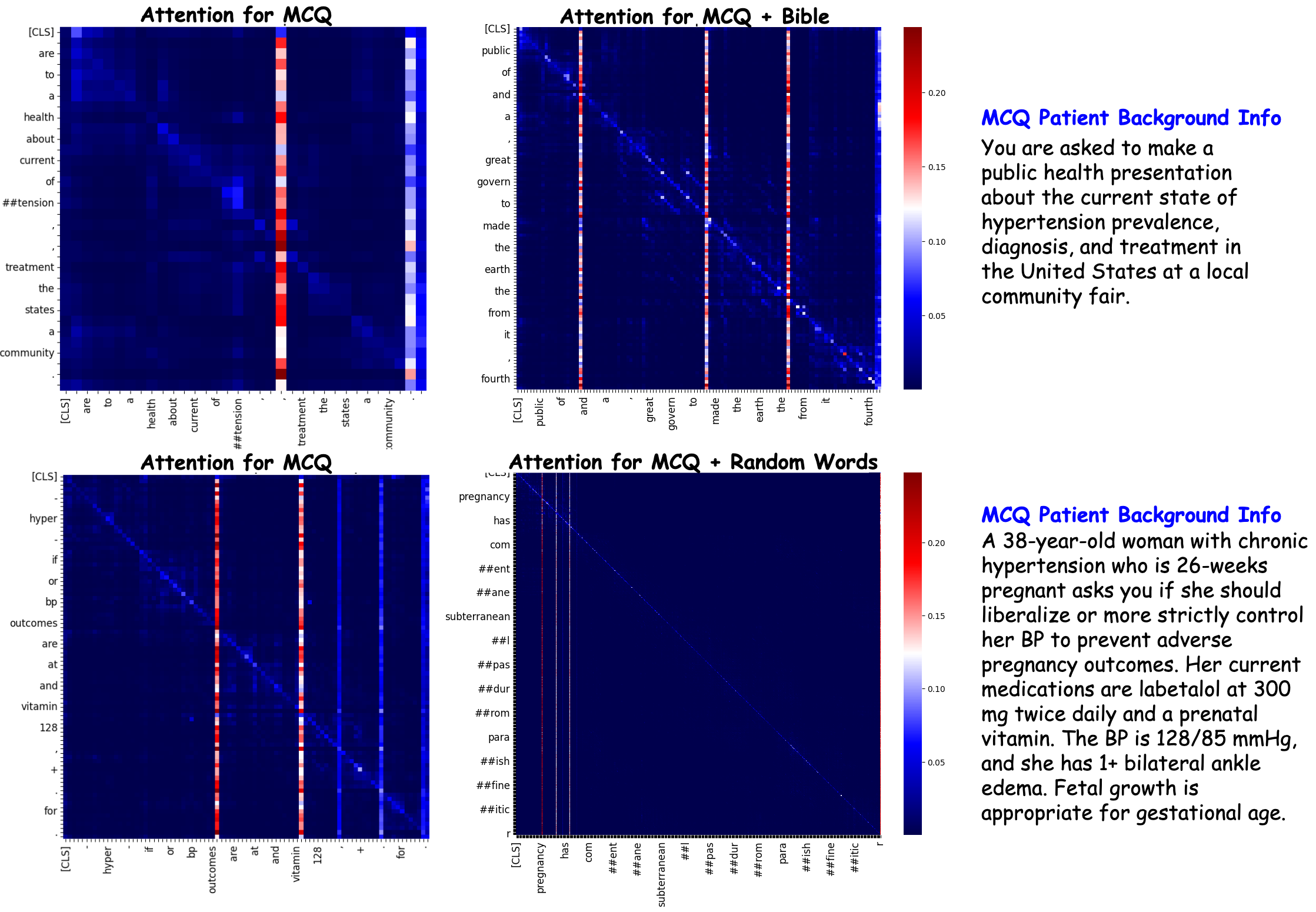
📊 实验亮点
实验结果表明,在肾脏病医学专业多项选择题测试中,对抗性的圣经文本显著提高了许多LLM的成功率,甚至随机单词文本也提高了某些模型的测试能力。这一发现挑战了传统认知,表明对抗性信息在RAG框架下可能具有意想不到的积极作用。具体性能提升数据未知,但结论具有统计显著性。
🎯 应用场景
该研究成果可应用于提升RAG系统的鲁棒性和泛化能力。在实际应用中,可以考虑在RAG系统中引入适量的对抗性信息,以提高模型在噪声环境下的表现。此外,该研究也为探索LLM的内在机制提供了新的思路,有助于开发更智能、更可靠的AI系统。未来,该研究或可推广到其他领域,例如金融、法律等,以提升LLM在复杂任务中的表现。
📄 摘要(原文)
Open-source LLMs have shown great potential as fine-tuned chatbots, and demonstrate robust abilities in reasoning and surpass many existing benchmarks. Retrieval-Augmented Generation (RAG) is a technique for improving the performance of LLMs on tasks that the models weren't explicitly trained on, by leveraging external knowledge databases. Numerous studies have demonstrated the effectiveness of RAG to more successfully accomplish downstream tasks when using vector datasets that consist of relevant background information. It has been implicitly assumed by those in the field that if adversarial background information is utilized in this context, that the success of using a RAG-based approach would be nonexistent or even negatively impact the results. To address this assumption, we tested several open-source LLMs on the ability of RAG to improve their success in answering multiple-choice questions (MCQ) in the medical subspecialty field of Nephrology. Unlike previous studies, we examined the effect of RAG in utilizing both relevant and adversarial background databases. We set up several open-source LLMs, including Llama 3, Phi-3, Mixtral 8x7b, Zephyr$β$, and Gemma 7B Instruct, in a zero-shot RAG pipeline. As adversarial sources of information, text from the Bible and a Random Words generated database were used for comparison. Our data show that most of the open-source LLMs improve their multiple-choice test-taking success as expected when incorporating relevant information vector databases. Surprisingly however, adversarial Bible text significantly improved the success of many LLMs and even random word text improved test taking ability of some of the models. In summary, our results demonstrate for the first time the countertintuitive ability of adversarial information datasets to improve the RAG-based LLM success.