Multimodal Misinformation Detection using Large Vision-Language Models
作者: Sahar Tahmasebi, Eric Müller-Budack, Ralph Ewerth
分类: cs.CL, cs.IR, cs.MM
发布日期: 2024-07-19
备注: Accepted for publication in: Conference on Information and Knowledge Management (CIKM) 2024
💡 一句话要点
提出基于大型视觉-语言模型的多模态错误信息检测方法,提升证据检索和事实核查性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态信息检测 大型语言模型 视觉-语言模型 证据检索 事实核查 零样本学习 信息过滤
📋 核心要点
- 现有错误信息检测方法缺乏有效的证据检索机制,或依赖于微调模型,泛化能力受限。
- 提出一种基于大型视觉-语言模型(LVLM)的多模态证据检索和事实验证方法,实现零样本错误信息检测。
- 通过实验验证,该方法在证据检索和事实验证任务中优于现有基线,并展现出更强的跨数据集泛化能力。
📝 摘要(中文)
错误信息的日益泛滥及其惊人的影响促使工业界和学术界开发错误信息检测和事实核查方法。最近,大型语言模型(LLM)在各种任务中表现出卓越的性能,但LLM是否以及如何帮助错误信息检测仍有待探索。现有的大多数最先进的方法要么不考虑证据而仅关注与声明相关的特征,要么假定已提供证据。少数方法将证据检索作为错误信息检测的一部分,但依赖于微调模型。本文研究了LLM在零样本设置下进行错误信息检测的潜力。我们将证据检索组件纳入流程,因为它对于从各种来源收集相关信息以检测声明的真实性至关重要。为此,我们提出了一种新颖的重排序方法,用于使用LLM和大型视觉-语言模型(LVLM)进行多模态证据检索。检索到的证据样本(图像和文本)作为基于LVLM的多模态事实验证(LVLM4FV)方法的输入。为了实现公平的评估,我们通过为图像和文本检索注释更完整的证据样本集,解决了现有证据检索数据集中证据样本不完整的基本事实问题。在两个数据集上的实验结果表明,与监督基线相比,所提出的方法在证据检索和事实验证任务中均具有优越性,并且具有更好的跨数据集泛化能力。
🔬 方法详解
问题定义:论文旨在解决多模态错误信息检测问题,现有方法要么忽略证据检索,要么依赖于微调,导致泛化能力不足。缺乏有效的零样本多模态错误信息检测方法是当前研究的痛点。
核心思路:论文的核心思路是利用大型语言模型(LLM)和大型视觉-语言模型(LVLM)的强大能力,构建一个包含证据检索和事实验证的零样本多模态错误信息检测框架。通过检索相关的图像和文本证据,并利用LVLM进行多模态信息的融合和推理,从而判断声明的真伪。
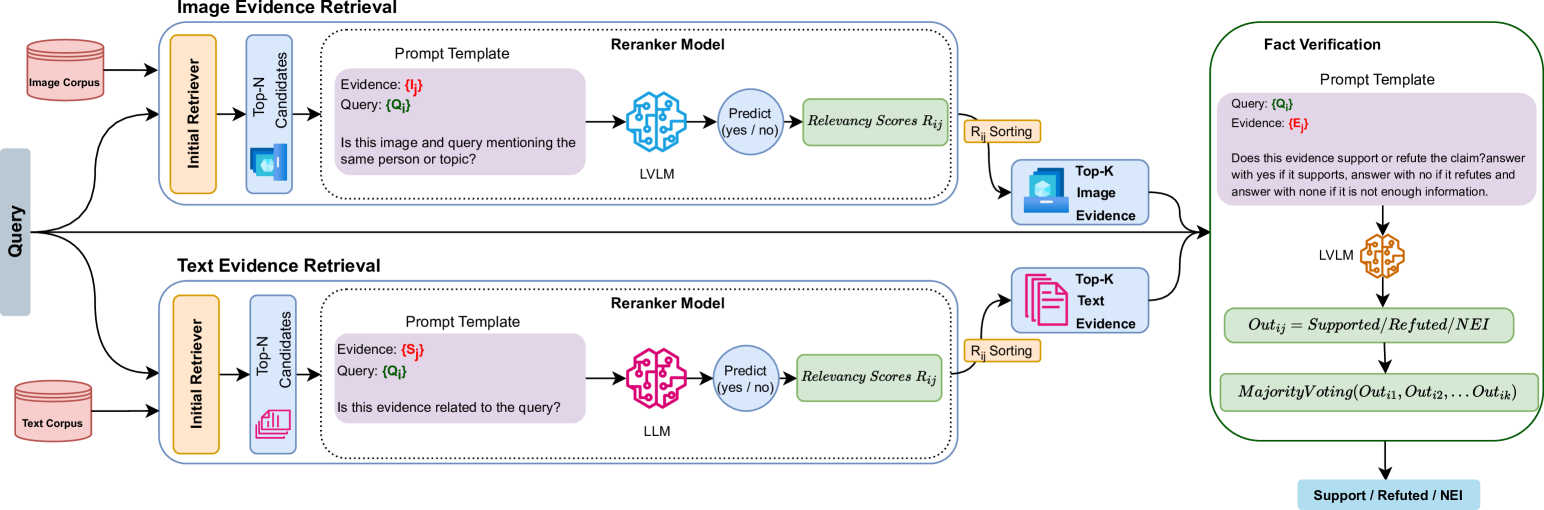
技术框架:该方法主要包含两个阶段:1) 多模态证据检索:利用LLM和LVLM对候选证据进行重排序,选择最相关的图像和文本证据。2) 基于LVLM的事实验证:将检索到的证据输入到LVLM中,进行多模态信息的融合和推理,输出声明的真伪判断结果。
关键创新:论文的关键创新在于提出了一种新颖的基于LLM和LVLM的多模态证据重排序方法,以及一个基于LVLM的零样本多模态事实验证框架。该方法无需微调,即可实现有效的错误信息检测,并具有良好的泛化能力。
关键设计:证据重排序阶段,论文设计了一种结合LLM和LVLM的排序策略,利用LLM对文本证据进行语义理解和排序,利用LVLM对图像和文本证据进行多模态相关性评估和排序。事实验证阶段,论文选择合适的LVLM模型,并设计合适的输入格式,将检索到的证据输入到LVLM中进行推理。具体参数设置和损失函数等细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在两个数据集上均取得了优于现有基线的性能。在证据检索任务中,该方法能够检索到更相关的证据。在事实验证任务中,该方法能够更准确地判断声明的真伪,并展现出更好的跨数据集泛化能力。具体的性能提升数据在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻媒体网站等,自动检测和过滤错误信息,减少虚假信息的传播,维护网络空间的健康和安全。该方法具有零样本能力,可快速部署到新的领域和数据集,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for misinformation detection and fact checking. Recent advances on large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with misinformation detection remains relatively underexplored. Most of existing state-of-the-art approaches either do not consider evidence and solely focus on claim related features or assume the evidence to be provided. Few approaches consider evidence retrieval as part of the misinformation detection but rely on fine-tuning models. In this paper, we investigate the potential of LLMs for misinformation detection in a zero-shot setting. We incorporate an evidence retrieval component into the process as it is crucial to gather pertinent information from various sources to detect the veracity of claims. To this end, we propose a novel re-ranking approach for multimodal evidence retrieval using both LLMs and large vision-language models (LVLM). The retrieved evidence samples (images and texts) serve as the input for an LVLM-based approach for multimodal fact verification (LVLM4FV). To enable a fair evaluation, we address the issue of incomplete ground truth for evidence samples in an existing evidence retrieval dataset by annotating a more complete set of evidence samples for both image and text retrieval. Our experimental results on two datasets demonstrate the superiority of the proposed approach in both evidence retrieval and fact verification tasks and also better generalization capability across dataset compared to the supervised baseline.