Baba Is AI: Break the Rules to Beat the Benchmark
作者: Nathan Cloos, Meagan Jens, Michelangelo Naim, Yen-Ling Kuo, Ignacio Cases, Andrei Barbu, Christopher J. Cueva
分类: cs.CL
发布日期: 2024-07-18 (更新: 2025-09-10)
备注: 8 pages, 8 figures
💡 一句话要点
提出Baba Is You游戏新基准,揭示LLM在规则操纵与泛化上的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 规则操纵 大型语言模型 Baba Is You 泛化能力 多模态学习
📋 核心要点
- 现有方法在解决需要创造性规则操纵的问题上存在不足,尤其是在游戏环境中。
- 论文核心思想是利用Baba Is You游戏,通过操纵规则图块来测试LLM的泛化能力。
- 实验结果表明,即使是最先进的LLM在需要规则操纵和组合的Baba Is You游戏中也表现不佳。
📝 摘要(中文)
本文提出了一个基于游戏Baba Is You的新基准,旨在探究智能体在遵循既有规则和创造性地重新定义规则和目标方面的能力。在该游戏中,智能体需要操纵环境中的物体以及代表规则的、带有文字的可移动图块,以达到指定目标并赢得游戏。研究测试了三个最先进的多模态大型语言模型(OpenAI GPT-4o、Google Gemini-1.5-Pro 和 Gemini-1.5-Flash),发现当泛化需要操纵和组合游戏规则时,这些模型表现出显著的失败。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在规则操纵和组合方面的泛化能力不足的问题。现有方法在处理需要智能体改变游戏规则以达到目标的任务时表现不佳,尤其是在像Baba Is You这样需要创造性解决问题的环境中。现有LLM在静态规则下表现良好,但无法有效处理动态变化的规则。
核心思路:论文的核心思路是利用Baba Is You游戏作为测试平台,该游戏允许玩家通过操纵带有文字的图块来改变游戏规则。通过观察LLM在操纵规则图块以达到目标时的表现,可以评估其在规则操纵和泛化方面的能力。这种方法能够更直接地测试LLM在动态规则环境下的推理能力。
技术框架:该研究的技术框架主要包括以下几个部分:1) Baba Is You游戏环境的构建;2) 选择三个最先进的多模态大型语言模型(OpenAI GPT-4o、Google Gemini-1.5-Pro 和 Gemini-1.5-Flash)作为测试对象;3) 设计一系列需要操纵规则图块才能完成的游戏关卡;4) 评估LLM在这些关卡中的表现,并分析其失败的原因。整体流程是:输入游戏状态(包括物体和规则图块),LLM输出动作,环境根据动作更新状态,直到达到目标或失败。
关键创新:该研究的关键创新在于提出了一个专门用于测试LLM规则操纵和泛化能力的新基准。与传统的游戏环境不同,Baba Is You允许智能体直接修改游戏规则,从而更直接地评估其在动态规则环境下的推理能力。此外,该研究还揭示了即使是最先进的LLM在处理此类任务时也存在显著的局限性。
关键设计:关键设计包括:1) 游戏关卡的设计,需要精心设计一系列关卡,这些关卡需要智能体操纵规则图块才能完成;2) 评估指标的选择,需要选择合适的指标来衡量LLM在规则操纵和泛化方面的表现,例如完成关卡的成功率;3) 模型输入的设计,需要将游戏状态以一种LLM能够理解的方式进行编码,例如使用文本描述或图像表示。
🖼️ 关键图片
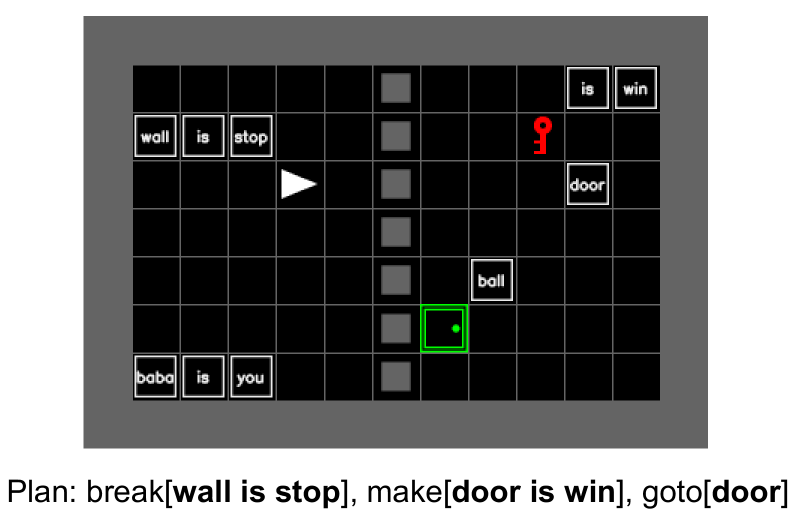
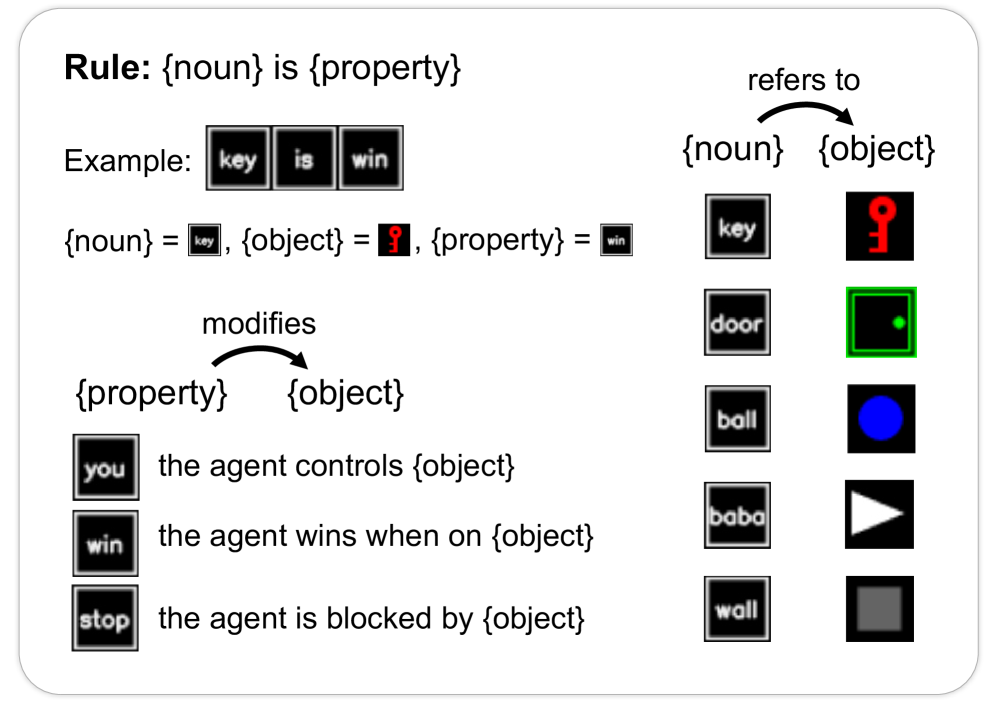

📊 实验亮点
实验结果表明,即使是最先进的多模态大型语言模型(GPT-4o、Gemini-1.5-Pro 和 Gemini-1.5-Flash)在需要操纵和组合游戏规则的Baba Is You游戏中也表现出显著的失败。具体性能数据未知,但论文强调了这些模型在规则操纵方面的局限性,表明现有LLM在处理动态规则环境方面仍有很大的提升空间。
🎯 应用场景
该研究的潜在应用领域包括机器人控制、自动化规划和通用人工智能。通过提高智能体在动态规则环境下的推理能力,可以使其更好地适应复杂和变化的世界,从而在实际应用中实现更强的鲁棒性和灵活性。未来的影响在于推动人工智能向更具创造性和适应性的方向发展。
📄 摘要(原文)
Humans solve problems by following existing rules and procedures, and also by leaps of creativity to redefine those rules and objectives. To probe these abilities, we developed a new benchmark based on the game Baba Is You where an agent manipulates both objects in the environment and rules, represented by movable tiles with words written on them, to reach a specified goal and win the game. We test three state-of-the-art multi-modal large language models (OpenAI GPT-4o, Google Gemini-1.5-Pro and Gemini-1.5-Flash) and find that they fail dramatically when generalization requires that the rules of the game must be manipulated and combined.