Prover-Verifier Games improve legibility of LLM outputs
作者: Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, Yuri Burda
分类: cs.CL
发布日期: 2024-07-18 (更新: 2024-08-01)
💡 一句话要点
提出基于证明-验证者游戏的训练算法以提高LLM输出的可读性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可读性 证明-验证者游戏 训练算法 人机交互 教育技术 对抗性训练
📋 核心要点
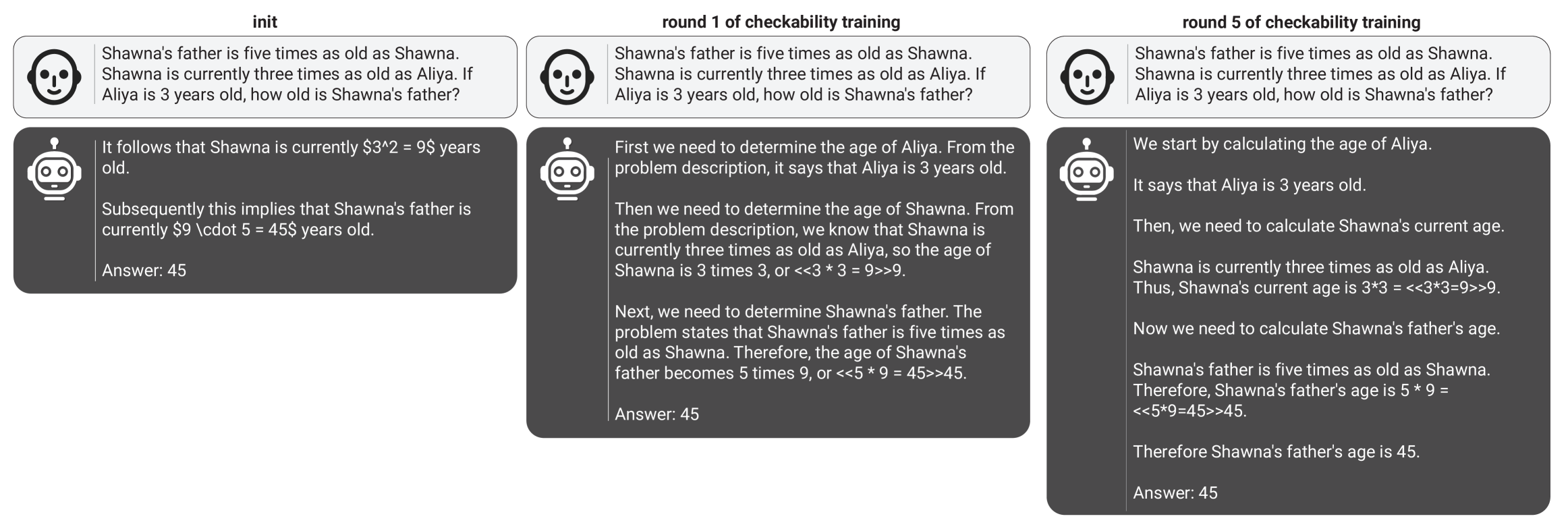
- 现有方法在优化大型语言模型输出的答案正确性时,可能导致输出的可读性降低,影响用户的理解和信任。
- 本文提出了一种新颖的训练算法,利用证明-验证者游戏的机制,通过小型验证者和不同类型的证明者来提升输出的可读性。
- 实验结果显示,帮助性证明者的准确性和验证者的鲁棒性在训练过程中显著提高,同时人类在验证帮助性证明者的解决方案时准确性也有所提升。
📝 摘要(中文)
为了增强大型语言模型(LLMs)输出的可信度,本文提出了一种支持清晰且易于检查的推理方法,称为可读性。我们在解决小学数学问题的背景下研究可读性,并表明仅优化答案正确性的链式思维解决方案可能会降低可读性。为此,我们提出了一种受Anil等人(2021)提出的证明-验证者游戏启发的训练算法。该算法通过小型验证者预测解决方案的正确性,帮助性证明者生成验证者接受的正确解决方案,以及狡诈证明者生成欺骗验证者的错误解决方案。实验结果表明,帮助性证明者的准确性和验证者对对抗攻击的鲁棒性在训练过程中均有所提高。我们还发现可读性训练能够转移到时间受限的人类验证者身上,提升他们在检查帮助性证明者解决方案时的准确性,而在检查狡诈证明者解决方案时则降低准确性。因此,通过小型验证者进行可检查性训练是一种提高大型LLM输出可读性的可行技术。
🔬 方法详解
问题定义:本文旨在解决大型语言模型输出的可读性问题,现有方法在追求答案正确性时,往往忽视了输出的清晰性和易检查性,导致用户理解困难。
核心思路:论文提出的训练算法通过引入小型验证者和不同类型的证明者,优化输出的可读性。帮助性证明者生成可被验证者接受的正确答案,而狡诈证明者则试图生成错误答案以欺骗验证者,从而提升整体的可检查性。
技术框架:整体架构包括三个主要模块:小型验证者、帮助性证明者和狡诈证明者。验证者负责判断答案的正确性,帮助性证明者生成符合验证者标准的答案,而狡诈证明者则尝试生成错误答案以测试验证者的鲁棒性。
关键创新:最重要的创新在于通过小型验证者的训练来提升输出的可读性,这一方法与传统的仅关注答案正确性的训练方式有本质区别,强调了可检查性的重要性。
关键设计:在训练过程中,设置了不同的损失函数以平衡帮助性和狡诈证明者的表现,同时优化验证者的判断能力,确保训练过程中的动态反馈机制能够有效提升各模块的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,帮助性证明者的准确性在训练过程中显著提高,验证者对对抗攻击的鲁棒性也得到了增强。人类在检查帮助性证明者的解决方案时准确性提升,而在检查狡诈证明者的解决方案时准确性则下降,验证了可读性训练的有效性。
🎯 应用场景
该研究的潜在应用领域包括教育技术、自动化评估系统和人机交互界面等。通过提高大型语言模型的输出可读性,可以增强用户的理解和信任,从而在实际应用中提升用户体验和模型的实用性。未来,这种方法可能在对抗性环境中进一步优化模型的鲁棒性和安全性。
📄 摘要(原文)
One way to increase confidence in the outputs of Large Language Models (LLMs) is to support them with reasoning that is clear and easy to check -- a property we call legibility. We study legibility in the context of solving grade-school math problems and show that optimizing chain-of-thought solutions only for answer correctness can make them less legible. To mitigate the loss in legibility, we propose a training algorithm inspired by Prover-Verifier Game from Anil et al. (2021). Our algorithm iteratively trains small verifiers to predict solution correctness, "helpful" provers to produce correct solutions that the verifier accepts, and "sneaky" provers to produce incorrect solutions that fool the verifier. We find that the helpful prover's accuracy and the verifier's robustness to adversarial attacks increase over the course of training. Furthermore, we show that legibility training transfers to time-constrained humans tasked with verifying solution correctness. Over course of LLM training human accuracy increases when checking the helpful prover's solutions, and decreases when checking the sneaky prover's solutions. Hence, training for checkability by small verifiers is a plausible technique for increasing output legibility. Our results suggest legibility training against small verifiers as a practical avenue for increasing legibility of large LLMs to humans, and thus could help with alignment of superhuman models.