Attention Overflow: Language Model Input Blur during Long-Context Missing Items Recommendation
作者: Damien Sileo
分类: cs.CL
发布日期: 2024-07-18
备注: Dataset URL: https://huggingface.co/datasets/sileod/missing-item-prediction
💡 一句话要点
揭示长文本输入下语言模型“注意力溢出”问题,影响推荐性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长文本处理 注意力机制 推荐系统 注意力溢出
📋 核心要点
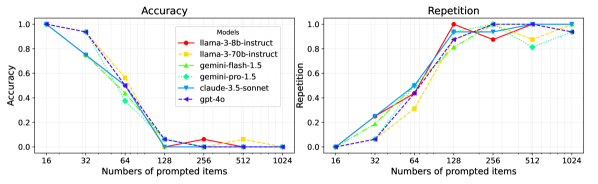
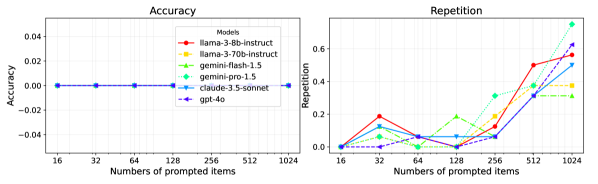
- 现有大型语言模型在长文本输入下,会产生“注意力溢出”现象,导致重复推荐已存在项目。
- 论文提出关注长文本输入时,语言模型防止重复推荐的能力是关键,并将其定义为“注意力溢出”。
- 通过合成数据和电影推荐实验,验证了“注意力溢出”现象,并分析了迭代循环缓解该问题的局限性。
📝 摘要(中文)
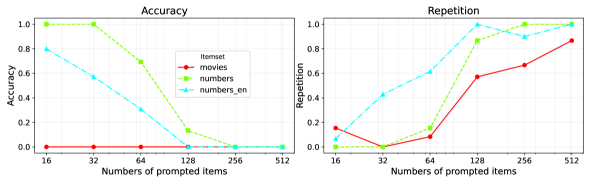
大型语言模型(LLM)能够根据提示中列出的项目建议缺失的元素,这可用于列表补全或基于用户历史的推荐。然而,当呈现过多的项目时,它们的性能会下降,因为它们开始建议已经包含在输入列表中的项目。对于2024年中期的旗舰LLM,这种情况大约发生在100个项目左右。我们在合成问题(例如,在给定范围的随机整数中查找缺失的数字)和真实的电影推荐场景中评估了这种现象。我们将此问题称为“注意力溢出”,因为防止重复需要同时关注所有项目。虽然迭代循环可以缓解这个问题,但它们的成本随着重复率的增加而增加,从而影响了语言模型从冗长输入中获得新颖性的能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理长文本输入时出现的“注意力溢出”问题,具体表现为在推荐或补全任务中,模型会重复推荐已经存在于输入列表中的项目。现有方法的痛点在于,随着输入文本长度的增加,模型的性能显著下降,无法有效利用长文本中的信息进行推理和推荐。
核心思路:论文的核心思路是指出,防止重复推荐需要模型同时关注输入列表中的所有项目,这对于长文本来说是一个挑战。作者将此现象定义为“注意力溢出”,并认为这是影响语言模型处理长文本能力的关键因素。通过分析模型在长文本输入下的表现,揭示了模型在长文本处理上的局限性。
技术框架:论文主要通过实验来分析和验证“注意力溢出”现象,并没有提出新的模型架构或训练方法。实验分为两部分:一是合成数据实验,用于控制输入数据的特征,例如数字范围和缺失数字的数量;二是电影推荐实验,使用真实的用户历史数据,模拟实际的推荐场景。通过对比模型在不同输入长度下的表现,评估“注意力溢出”的影响。
关键创新:论文的主要创新在于对“注意力溢出”现象的定义和分析。虽然大型语言模型在长文本处理方面存在局限性是已知的,但论文明确指出了“注意力溢出”是导致性能下降的关键原因,并从信息检索的角度解释了这一现象。这为后续研究如何提高语言模型处理长文本的能力提供了新的视角。
关键设计:论文没有涉及具体的模型设计或参数设置。实验设计主要关注输入文本的长度和重复率对模型性能的影响。在电影推荐实验中,使用了标准的数据集和评估指标,例如准确率和召回率。迭代循环被用作一种缓解“注意力溢出”的策略,但论文也指出了其成本随着重复率的增加而增加的局限性。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了大型语言模型在处理长文本输入时存在“注意力溢出”现象,并量化了该现象对模型性能的影响。实验结果表明,对于2024年中期的旗舰LLM,当输入项目数量达到100左右时,模型开始出现重复推荐。此外,论文还分析了迭代循环缓解该问题的局限性,为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要处理长文本输入的场景,例如:个性化推荐系统、智能客服、文档摘要、知识图谱构建等。通过解决“注意力溢出”问题,可以提升语言模型在这些场景下的性能和用户体验,使其能够更好地理解和利用长文本信息,提供更准确、更相关的服务。
📄 摘要(原文)
Large language models (LLMs) can suggest missing elements from items listed in a prompt, which can be used for list completion or recommendations based on users' history. However, their performance degrades when presented with too many items, as they start to suggest items already included in the input list. This occurs at around 100 items for mid-2024 flagship LLMs. We evaluate this phenomenon on both synthetic problems (e.g., finding missing numbers in a given range of shuffled integers) and realistic movie recommendation scenarios. We refer to this issue as \textit{attention overflow}, as preventing repetition requires attending to all items simultaneously. Although iterative loops can mitigate this problem, their costs increase with the repetition rate, affecting the language models' ability to derive novelty from lengthy inputs.