Steamroller Problems: An Evaluation of LLM Reasoning Capability with Automated Theorem Prover Strategies
作者: Lachlan McGinness, Peter Baumgartner
分类: cs.CL, cs.AI
发布日期: 2024-07-17
💡 一句话要点
评估LLM在自动定理证明策略下的推理能力:基于Steamroller问题的研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动定理证明 推理能力评估 Steamroller问题 推理策略
📋 核心要点
- 现有方法缺乏对LLM在形式化推理中遵循特定策略能力的深入评估,尤其是在自动定理证明领域。
- 该研究通过让LLM遵循ATP的推理策略来解决上述问题,旨在评估LLM在指导下的推理能力。
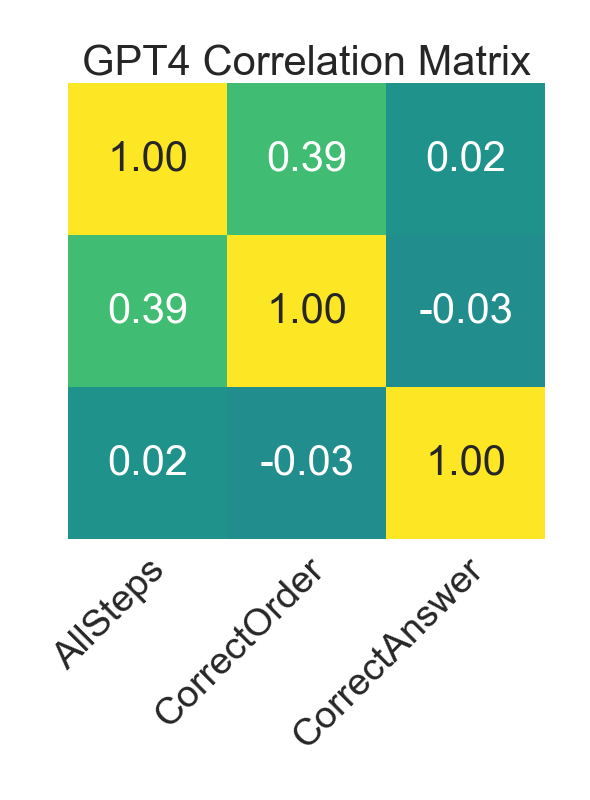
- 实验结果表明,LLM在ATP策略下的表现与CoT相当,且正确推理与正确答案的相关性较低,强调了关注结果不确定性的重要性。
📝 摘要(中文)
本研究首次考察了大型语言模型(LLM)遵循自动定理证明器(ATP)推理策略的能力。我们评估了GPT4、GPT3.5 Turbo和谷歌最新Gemini模型在Steamroller领域问题上的表现。除了确定准确率,我们还利用自然语言处理库spaCy探索了研究LLM推理能力的新方法。一个令人担忧的结果是,对于所有测试模型,正确的推理和正确的答案之间的相关性很低。我们发现,在使用ATP推理策略时,这些模型的性能与one-shot chain of thought相当,并且观察到在得出关于模型性能的结论时,关注准确率结果中的不确定性至关重要。与之前的推测一致,我们证实LLM偏好且最擅长遵循自下而上的推理过程。然而,推理策略仍然有利于推导出小的、相关的公式集,以便由可信的推理引擎进行外部处理。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在遵循自动定理证明器(ATP)的推理策略时的表现。现有方法缺乏对LLM在形式化推理中遵循特定策略能力的深入评估,尤其是在自动定理证明领域,这限制了LLM在需要严谨逻辑推理任务中的应用。
核心思路:论文的核心思路是让LLM模拟ATP的推理过程,通过预定义的推理策略引导LLM进行问题求解。通过观察LLM在不同策略下的表现,评估其推理能力和对策略的遵循程度。这种方法旨在揭示LLM在形式化推理方面的优势和局限性。
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择Steamroller领域的问题作为测试集;2) 使用不同的LLM(GPT4、GPT3.5 Turbo、Gemini)作为推理引擎;3) 设计并实施不同的ATP推理策略;4) 利用spaCy等NLP工具分析LLM的推理过程和答案;5) 评估LLM在不同策略下的准确率和推理质量。
关键创新:该研究的关键创新在于首次将ATP的推理策略应用于评估LLM的推理能力。通过这种方式,可以更深入地了解LLM在形式化推理方面的优势和局限性。此外,利用spaCy等NLP工具分析LLM的推理过程也是一种新的尝试,有助于揭示LLM的推理机制。
关键设计:论文的关键设计包括:1) 选择Steamroller领域的问题,该领域的问题具有一定的复杂性和逻辑性,适合评估推理能力;2) 设计不同的ATP推理策略,例如自顶向下和自底向上等;3) 使用准确率和推理质量等指标评估LLM的表现;4) 利用spaCy分析LLM的推理过程,例如提取关键概念和关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在使用ATP推理策略时的性能与one-shot chain of thought相当,且正确推理与正确答案之间的相关性较低。研究还发现,LLM更擅长遵循自底向上的推理过程。这些发现强调了在评估LLM推理能力时,关注结果不确定性的重要性。
🎯 应用场景
该研究成果可应用于提升LLM在需要严谨逻辑推理的领域的表现,例如软件验证、数学证明和知识图谱推理。通过理解LLM的推理能力和局限性,可以设计更有效的提示工程方法,并开发更可靠的AI系统。未来的研究可以探索如何将ATP的推理策略与LLM的优势相结合,构建更强大的推理引擎。
📄 摘要(原文)
This study presents the first examination of the ability of Large Language Models (LLMs) to follow reasoning strategies that are used to guide Automated Theorem Provers (ATPs). We evaluate the performance of GPT4, GPT3.5 Turbo and Google's recent Gemini model on problems from a steamroller domain. In addition to determining accuracy we make use of the Natural Language Processing library spaCy to explore new methods of investigating LLM's reasoning capabilities. This led to one alarming result, the low correlation between correct reasoning and correct answers for any of the tested models. We found that the models' performance when using the ATP reasoning strategies was comparable to one-shot chain of thought and observe that attention to uncertainty in the accuracy results is critical when drawing conclusions about model performance. Consistent with previous speculation we confirm that LLMs have a preference for, and are best able to follow, bottom up reasoning processes. However, the reasoning strategies can still be beneficial for deriving small and relevant sets of formulas for external processing by a trusted inference engine.