E5-V: Universal Embeddings with Multimodal Large Language Models
作者: Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, Fuzhen Zhuang
分类: cs.CL, cs.CV, cs.IR
发布日期: 2024-07-17
备注: Code and models are available at https://github.com/kongds/E5-V
💡 一句话要点
E5-V:利用多模态大语言模型实现通用多模态嵌入
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 通用嵌入 单模态训练 提示工程 跨模态检索 视觉问答
📋 核心要点
- 现有方法在多模态信息表示方面存在局限性,难以有效弥合不同模态之间的差距,阻碍了通用多模态理解的发展。
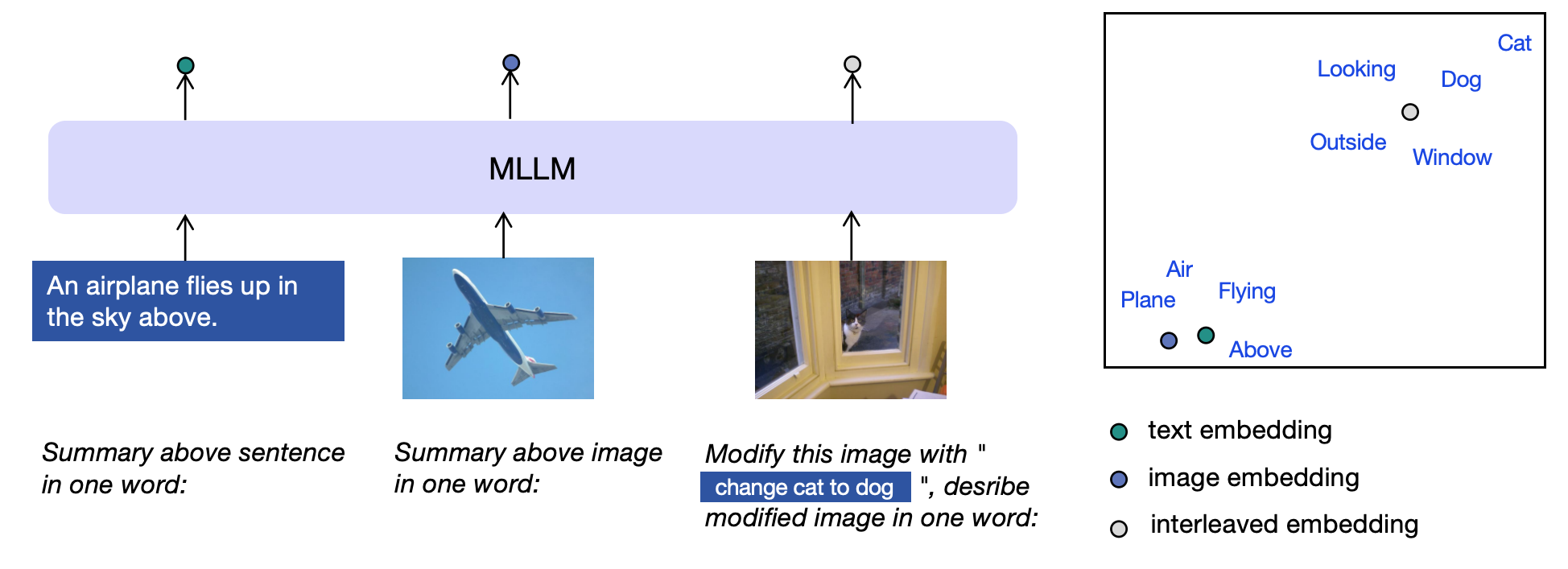
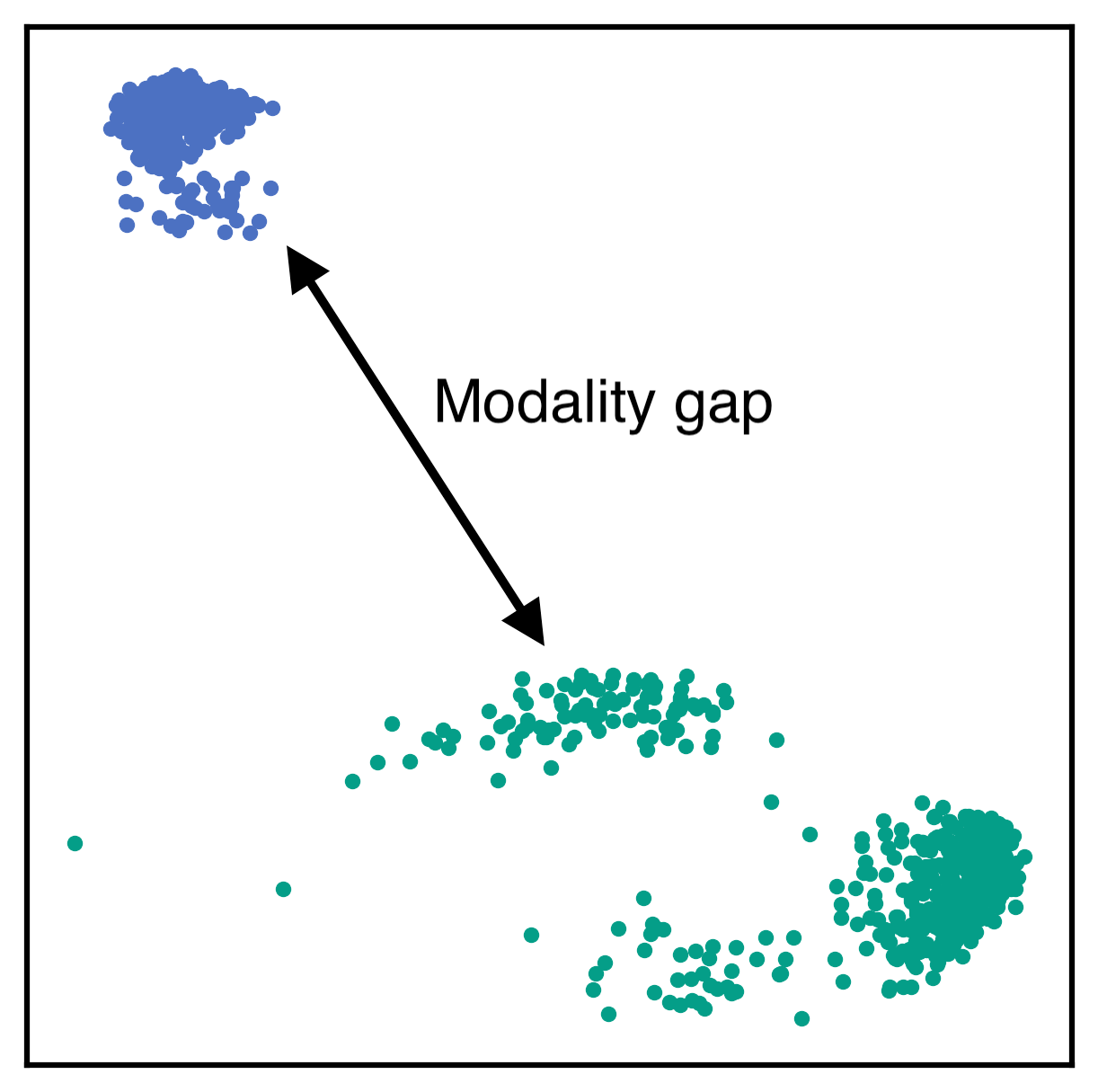
- E5-V框架利用多模态大语言模型(MLLMs)的强大能力,通过提示工程,实现跨模态信息的有效对齐和统一表示。
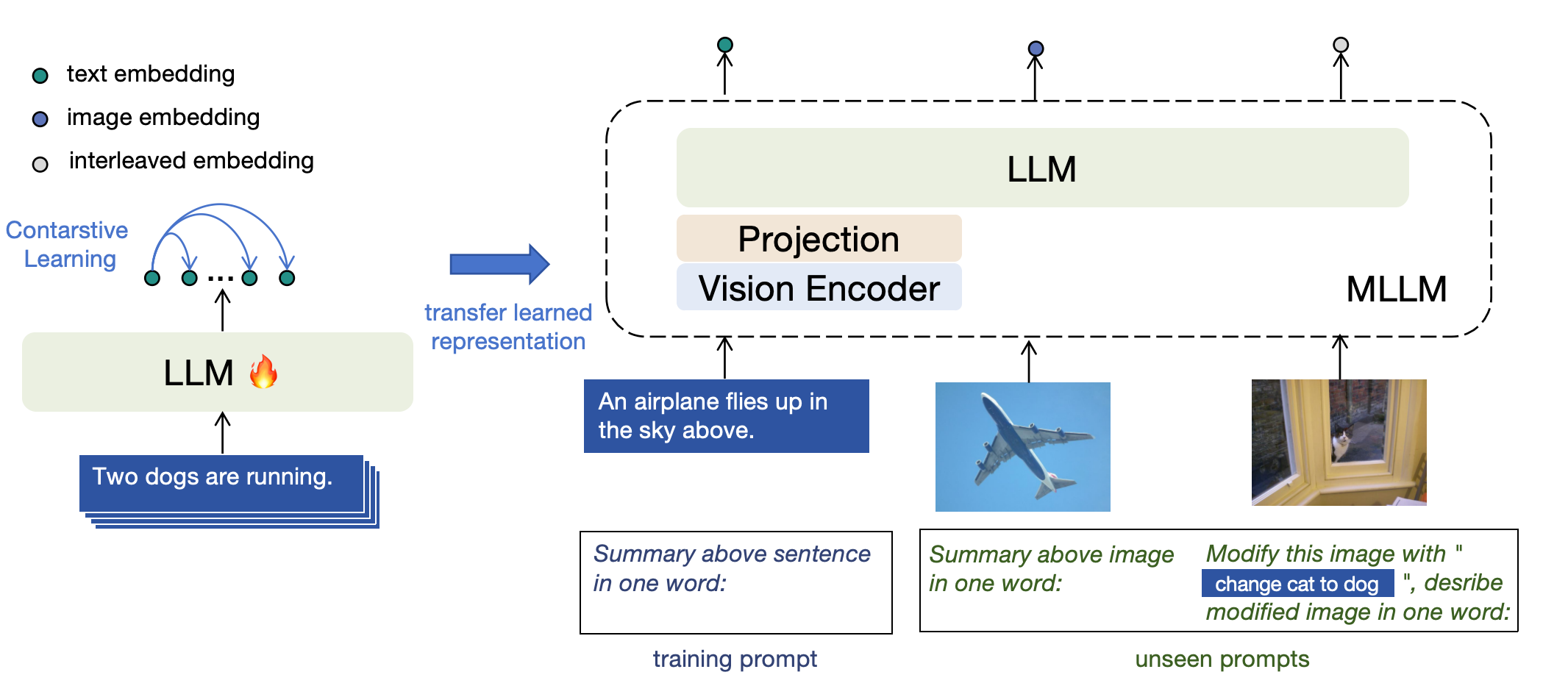
- E5-V采用单模态文本对训练,显著降低了训练成本(约95%),并在多种任务上超越了传统多模态训练方法。
📝 摘要(中文)
多模态大语言模型(MLLMs)在通用视觉和语言理解方面展现出巨大的潜力。然而,使用MLLMs进行多模态信息表示的研究仍有待探索。本文提出了一个名为E5-V的新框架,旨在调整MLLMs以实现通用多模态嵌入。研究结果表明,与以往方法相比,MLLMs在表示多模态输入方面具有显著潜力。通过利用带有提示的MLLMs,E5-V有效地弥合了不同类型输入之间的模态差距,即使没有经过微调,也能在多模态嵌入方面表现出强大的性能。我们提出了一种用于E5-V的单模态训练方法,该模型仅在文本对上进行训练。这种方法在图像-文本对上的传统多模态训练基础上有了显著改进,同时将训练成本降低了约95%。此外,这种方法消除了对昂贵的多模态训练数据收集的需求。在四种类型的任务中进行的大量实验证明了E5-V的有效性。作为一个通用的多模态模型,E5-V不仅实现了,而且通常超越了每个任务中的最先进性能,尽管它是在单一模态上训练的。
🔬 方法详解
问题定义:现有方法在多模态信息表示方面存在挑战,难以有效融合不同模态的信息,导致模型在跨模态任务中的性能受限。传统的图像-文本对训练方法需要大量标注数据,训练成本高昂。
核心思路:E5-V的核心思路是利用多模态大语言模型(MLLMs)的强大语言理解能力,通过提示工程将不同模态的信息转化为统一的语义空间中的嵌入表示。通过在文本对上进行训练,模型可以学习到通用的语义关系,从而更好地理解和表示其他模态的信息。
技术框架:E5-V框架主要包含以下几个阶段:1) 输入编码:将不同模态的输入(例如图像、文本)通过各自的编码器转换为特征表示。2) 提示工程:设计合适的提示语,引导MLLM理解输入特征的含义。3) MLLM处理:将编码后的特征和提示语输入MLLM,生成多模态嵌入表示。4) 训练:使用对比学习等方法,优化MLLM的参数,使其能够生成高质量的多模态嵌入。
关键创新:E5-V的关键创新在于其单模态训练方法。与传统的图像-文本对训练方法不同,E5-V仅在文本对上进行训练,从而大大降低了训练成本,并消除了对大量多模态标注数据的需求。此外,E5-V通过提示工程,有效地利用了MLLM的语言理解能力,实现了跨模态信息的有效对齐。
关键设计:E5-V的关键设计包括:1) 提示语的设计:选择合适的提示语,引导MLLM理解输入特征的含义,例如使用“This is a picture of”作为图像的提示语。2) 损失函数:使用对比学习损失函数,鼓励模型生成相似语义的输入具有相近的嵌入表示。3) MLLM的选择:选择具有强大语言理解能力的MLLM,例如LLaMA、GPT等。
🖼️ 关键图片
📊 实验亮点
E5-V在多个多模态任务上取得了显著的性能提升。例如,在图像-文本检索任务中,E5-V超越了以往的最先进方法,取得了SOTA结果。更重要的是,E5-V仅使用单模态文本数据进行训练,训练成本降低了约95%,这使得大规模多模态模型的训练成为可能。
🎯 应用场景
E5-V具有广泛的应用前景,例如跨模态检索、视觉问答、图像描述生成等。该模型可以用于构建更智能的搜索引擎,能够根据用户的文本查询检索相关的图像、视频等信息。此外,E5-V还可以应用于机器人领域,帮助机器人理解周围环境,并进行相应的操作。未来,E5-V有望成为通用人工智能的重要组成部分。
📄 摘要(原文)
Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.