Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
作者: Mustafa Dogan, Ilker Kesen, Iacer Calixto, Aykut Erdem, Erkut Erdem
分类: cs.CL, cs.CV
发布日期: 2024-07-17
备注: Preprint. 33 pages, 17 Figures, 3 Tables
💡 一句话要点
评估多模态LLM在小样本学习中的语言能力,关注ICL和CoT提示
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 小样本学习 上下文学习 思维链 视觉问答 图像描述
📋 核心要点
- 多模态大型语言模型(MLLM)的语言能力对其在各种任务中的有效应用至关重要,但其性能受限于复杂推理和上下文理解。
- 本研究通过小样本上下文学习(ICL)和思维链(CoT)提示来提升MLLM在VALSE基准上的性能,关注预训练数据的影响。
- 实验结果表明,ICL和CoT提示显著提升模型性能,尤其是在复杂推理任务中,不同预训练数据对模型性能有显著影响。
📝 摘要(中文)
本研究旨在评估多模态大型语言模型(MLLM)在VALSE基准上的性能,重点关注小样本上下文学习(ICL)和思维链(CoT)提示的有效性。我们对最先进的MLLM进行了全面评估,这些模型在模型大小和预训练数据集方面各不相同。实验结果表明,ICL和CoT提示显著提高了模型性能,尤其是在需要复杂推理和上下文理解的任务中。在字幕数据集上预训练的模型表现出优越的零样本性能,而在交错图像-文本数据上训练的模型则受益于小样本学习。我们的发现为优化MLLM以更好地将语言扎根于视觉上下文中提供了有价值的见解,突出了预训练数据组成的重要性以及小样本学习策略在提高MLLM推理能力方面的潜力。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLM)在处理需要复杂推理和上下文理解的任务时,其语言能力受到限制。虽然大型语言模型在纯文本任务上表现出色,但在涉及视觉信息的多模态任务中,如何有效利用视觉信息进行推理仍然是一个挑战。现有方法可能无法充分利用视觉上下文来提升语言理解和生成能力。
核心思路:本研究的核心思路是通过小样本上下文学习(ICL)和思维链(CoT)提示来增强MLLM的语言能力。ICL允许模型通过少量示例学习并适应新任务,而CoT提示则引导模型逐步推理,从而提高复杂任务的性能。同时,研究还关注预训练数据对模型性能的影响,探索不同预训练策略对模型泛化能力的影响。
技术框架:该研究采用实验评估的方法,在VALSE基准上测试不同MLLM的性能。主要流程包括:1) 选择不同大小和预训练数据集的MLLM;2) 使用ICL和CoT提示配置模型;3) 在VALSE基准上评估模型性能;4) 分析实验结果,比较不同模型和提示策略的性能差异。
关键创新:本研究的关键创新在于系统性地评估了ICL和CoT提示对MLLM语言能力的影响,并深入分析了预训练数据对模型性能的贡献。通过实验,揭示了ICL和CoT提示在提升MLLM复杂推理能力方面的有效性,并指出了不同预训练策略的优劣。
关键设计:研究中,ICL提示通过提供少量示例来引导模型学习,示例的选择和数量会影响模型性能。CoT提示则通过引导模型逐步推理来提高复杂任务的性能,提示的设计需要考虑任务的特点和模型的推理能力。此外,预训练数据集的选择也是关键,不同的数据集会影响模型的泛化能力和对视觉信息的理解。
🖼️ 关键图片
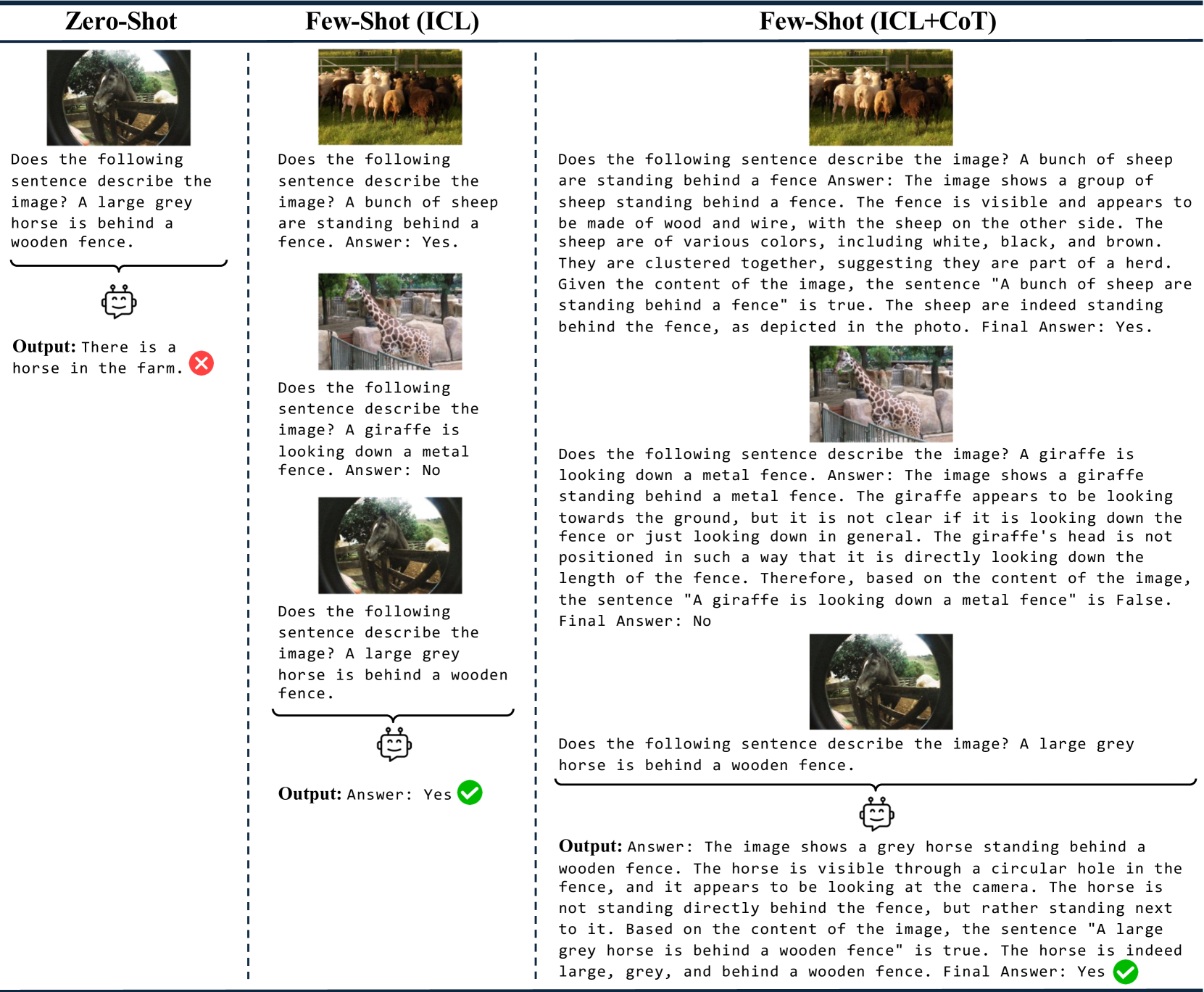


📊 实验亮点
实验结果表明,ICL和CoT提示显著提高了MLLM在VALSE基准上的性能。在字幕数据集上预训练的模型表现出优越的零样本性能,而在交错图像-文本数据上训练的模型则受益于小样本学习。具体性能提升幅度未知,但研究强调了ICL和CoT提示以及预训练数据对模型性能的重要性。
🎯 应用场景
该研究成果可应用于各种需要多模态理解和推理的场景,例如视觉问答、图像描述生成、机器人导航等。通过优化MLLM的语言能力,可以提升其在实际应用中的性能和可靠性。未来,该研究可以进一步扩展到更复杂的任务和领域,例如医疗影像分析、自动驾驶等。
📄 摘要(原文)
The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.