PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation
作者: Branden Butler, Sixing Yu, Arya Mazaheri, Ali Jannesari
分类: cs.CL, cs.DC, cs.LG
发布日期: 2024-07-16 (更新: 2024-11-16)
备注: 11 pages, submitted to SC24 conference
💡 一句话要点
PipeInfer:利用异步流水线推测加速LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型推理 推测执行 流水线并行 异步计算 低延迟 系统优化 模型加速
📋 核心要点
- 现有LLM推理加速技术依赖高推测接受率,且对任务接受率变化敏感,导致性能不稳定。
- PipeInfer采用流水线推测,通过异步推测和早期取消无效计算,提高单请求场景下的系统利用率。
- 实验表明,PipeInfer在生成速度上相比标准推测推理最高提升2.15倍,对低接受率和低带宽互连具有更好的容忍度。
📝 摘要(中文)
大规模语言模型(LLM)在计算机集群上的推理已成为研究热点,许多加速技术借鉴了CPU的推测执行。这些技术减少了与内存带宽相关的瓶颈,但也增加了每次推理运行的端到端延迟,需要高推测接受率才能提高性能。由于任务间的接受率变化,推测推理技术可能会降低性能。此外,流水线并行设计需要大量用户请求才能维持最大利用率。为此,我们提出了PipeInfer,一种流水线推测加速技术,旨在减少单请求场景下的token间延迟并提高系统利用率,同时提高对低推测接受率和低带宽互连的容忍度。PipeInfer在生成速度上比标准推测推理提高了高达2.15倍。PipeInfer通过连续异步推测和早期推理取消来实现改进,前者通过在运行多个推测运行的同时运行单token推理来提高延迟和生成速度,而后者通过跳过无效运行的计算来提高速度和延迟,即使在推理过程中也是如此。
🔬 方法详解
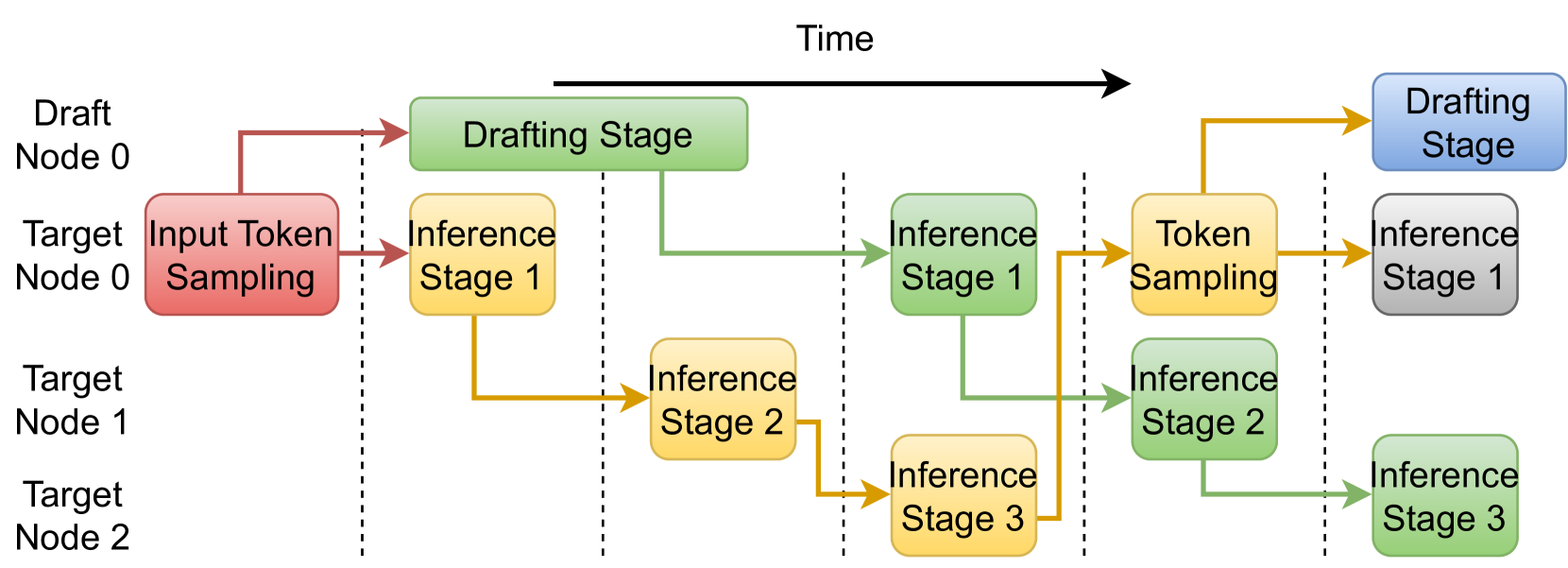
问题定义:现有的大语言模型推理加速方法,特别是基于推测执行的方法,虽然能够缓解内存带宽瓶颈,但引入了额外的端到端延迟。这些方法依赖于较高的推测接受率才能获得性能提升,并且在面对不同任务时,接受率的变化会导致性能下降。此外,传统的流水线并行设计需要大量的并发请求才能保证较高的资源利用率,这在单请求场景下是一个明显的限制。
核心思路:PipeInfer的核心思路是利用流水线化的异步推测来隐藏延迟,并提高资源利用率。通过在进行单token推理的同时,并行地进行多个推测运行,从而减少token间的延迟。此外,PipeInfer还引入了早期推理取消机制,能够及时停止无效的推测分支,避免浪费计算资源。
技术框架:PipeInfer的整体框架包含以下几个主要阶段:1) Continuous Asynchronous Speculation(连续异步推测):在主干模型进行单token推理的同时,异步地启动多个推测模型的推理。2) Early Inference Cancellation(早期推理取消):如果检测到某个推测分支无效,则立即取消该分支的计算,释放资源。3) Pipelined Execution(流水线执行):将整个推理过程分解为多个流水线阶段,每个阶段负责一部分计算任务,从而实现并行执行。
关键创新:PipeInfer的关键创新在于其连续异步推测和早期推理取消机制。传统的推测执行通常是同步的,需要等待推测结果才能进行下一步操作。而PipeInfer通过异步推测,实现了计算和通信的重叠,从而减少了延迟。早期推理取消机制则能够避免无效计算,提高资源利用率。
关键设计:PipeInfer的具体实现细节包括:1) 推测模型的选择:可以使用较小的模型进行推测,以降低计算成本。2) 推测分支的数量:需要根据硬件资源和任务特点进行调整,以达到最佳的性能。3) 取消策略:需要设计有效的取消策略,以确保及时停止无效的推测分支。4) 流水线划分:需要合理地划分流水线阶段,以平衡各个阶段的负载。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PipeInfer在生成速度上相比标准推测推理最高提升了2.15倍。此外,PipeInfer对低推测接受率和低带宽互连具有更好的容忍度,这意味着即使在资源受限的环境下,PipeInfer也能获得较好的性能提升。这些结果验证了PipeInfer的有效性和实用性。
🎯 应用场景
PipeInfer可应用于各种需要加速LLM推理的场景,例如在线对话系统、文本生成服务、机器翻译等。该技术尤其适用于单用户请求量较小的场景,能够有效提高系统吞吐量和降低延迟,提升用户体验。未来,PipeInfer可以与模型压缩、量化等技术结合,进一步提高推理效率。
📄 摘要(原文)
Inference of Large Language Models (LLMs) across computer clusters has become a focal point of research in recent times, with many acceleration techniques taking inspiration from CPU speculative execution. These techniques reduce bottlenecks associated with memory bandwidth, but also increase end-to-end latency per inference run, requiring high speculation acceptance rates to improve performance. Combined with a variable rate of acceptance across tasks, speculative inference techniques can result in reduced performance. Additionally, pipeline-parallel designs require many user requests to maintain maximum utilization. As a remedy, we propose PipeInfer, a pipelined speculative acceleration technique to reduce inter-token latency and improve system utilization for single-request scenarios while also improving tolerance to low speculation acceptance rates and low-bandwidth interconnects. PipeInfer exhibits up to a 2.15$\times$ improvement in generation speed over standard speculative inference. PipeInfer achieves its improvement through Continuous Asynchronous Speculation and Early Inference Cancellation, the former improving latency and generation speed by running single-token inference simultaneously with several speculative runs, while the latter improves speed and latency by skipping the computation of invalidated runs, even in the middle of inference.