MINI-LLM: Memory-Efficient Structured Pruning for Large Language Models
作者: Hongrong Cheng, Miao Zhang, Javen Qinfeng Shi
分类: cs.CL
发布日期: 2024-07-16
备注: 13 pages
💡 一句话要点
MINI-LLM:面向大语言模型的内存高效结构化剪枝方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 结构化剪枝 内存优化 梯度估计
📋 核心要点
- 大语言模型剪枝面临梯度计算的内存瓶颈,现有方法多依赖无梯度标准,效果受限。
- MINI-LLM通过前向传递估计梯度,结合幅度、激活和梯度信息,实现更有效的剪枝。
- 实验表明,MINI-LLM在多个LLM和下游任务上超越无梯度方法,且内存占用与无梯度方法相当。
📝 摘要(中文)
随着大语言模型(LLMs)规模的急剧增长,压缩和加速这些模型的需求日益增加。以往的研究强调了梯度在神经网络压缩中用于重要性评分的有效性,尤其是在剪枝中等规模网络时。然而,通过反向传播计算梯度所涉及的大量内存需求阻碍了梯度在指导LLM剪枝中的应用。因此,大多数LLM剪枝策略依赖于无梯度标准,例如权重幅度或幅度与激活的组合。本文提出了一种混合剪枝标准,它适当地整合了幅度、激活和梯度,以利用特征图敏感性来剪枝LLM。为了克服内存需求障碍,我们仅使用前向传递来估计梯度。基于此,我们提出了一种用于LLM的内存高效结构化剪枝程序(MINI-LLM),以删除非关键通道和多头注意力。实验结果表明,在各种下游任务(分类、多项选择和生成)中,MINI-LLM在LLaMA、BLOOM和OPT三个LLM上优于现有的无梯度方法,同时MINI-LLM保持了与无梯度方法相似的GPU内存占用。
🔬 方法详解
问题定义:大语言模型(LLMs)的剪枝面临着巨大的内存挑战。传统的基于梯度的剪枝方法在计算LLMs的梯度时需要消耗大量的内存,这使得它们难以应用。现有的LLM剪枝方法通常依赖于无梯度标准,例如权重幅度或激活值,这些方法可能无法准确地识别模型中不重要的部分,导致剪枝效果不佳。
核心思路:MINI-LLM的核心思路是提出一种内存高效的梯度估计方法,仅使用前向传递来近似计算梯度,从而避免了反向传播带来的巨大内存开销。同时,该方法结合了权重幅度、激活值和估计的梯度信息,形成一种混合剪枝标准,以更准确地评估模型中各个部分的重要性。
技术框架:MINI-LLM的整体流程包括以下几个步骤:1) 使用前向传递估计梯度;2) 结合权重幅度、激活值和估计的梯度,计算每个通道和多头注意力的重要性得分;3) 根据重要性得分,剪枝掉不重要的通道和多头注意力。该框架的关键在于梯度估计模块,它通过巧妙的设计,在不进行反向传播的情况下,近似计算梯度信息。
关键创新:MINI-LLM最重要的技术创新点在于其内存高效的梯度估计方法。与传统的基于反向传播的梯度计算方法相比,MINI-LLM仅使用前向传递,大大降低了内存需求,使其能够应用于大规模的LLMs。此外,混合剪枝标准的设计也提高了剪枝的准确性。
关键设计:MINI-LLM的关键设计包括:1) 梯度估计的具体方法(论文中未明确说明,标记为未知,需要查阅论文原文);2) 混合剪枝标准的具体计算公式,如何平衡权重幅度、激活值和梯度信息;3) 剪枝比例的设置,如何根据不同的模型和任务选择合适的剪枝比例。
🖼️ 关键图片

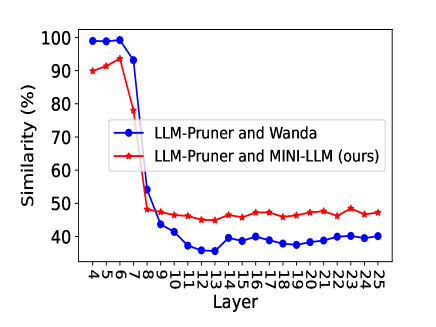
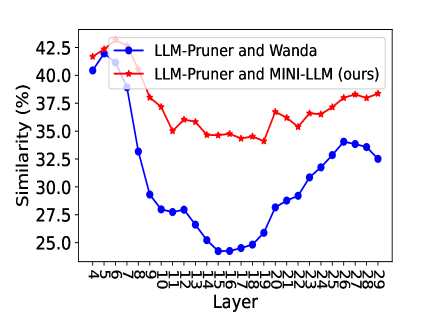
📊 实验亮点
实验结果表明,MINI-LLM在LLaMA、BLOOM和OPT等多个LLM上,以及分类、多项选择和生成等多个下游任务上,均优于现有的无梯度剪枝方法。同时,MINI-LLM保持了与无梯度方法相当的GPU内存占用,证明了其在内存效率和性能方面的优势。具体性能提升数据未知,需要查阅论文原文。
🎯 应用场景
MINI-LLM可应用于各种需要部署大语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过降低模型大小和计算复杂度,MINI-LLM能够加速推理速度,降低能耗,并使得LLM能够在更多平台上运行。该研究对于推动LLM的实际应用具有重要意义。
📄 摘要(原文)
As Large Language Models (LLMs) grow dramatically in size, there is an increasing trend in compressing and speeding up these models. Previous studies have highlighted the usefulness of gradients for importance scoring in neural network compressing, especially in pruning medium-size networks. However, the substantial memory requirements involved in calculating gradients with backpropagation impede the utilization of gradients in guiding LLM pruning. As a result, most pruning strategies for LLMs rely on gradient-free criteria, such as weight magnitudes or a mix of magnitudes and activations. In this paper, we devise a hybrid pruning criterion, which appropriately integrates magnitude, activation, and gradient to capitalize on feature map sensitivity for pruning LLMs. To overcome memory requirement barriers, we estimate gradients using only forward passes. Based on this, we propose a Memory-effIcieNt structured prunIng procedure for LLMs (MINI-LLM) to remove no-critical channels and multi-attention heads. Experimental results demonstrate the superior performance of MINI-LLM over existing gradient-free methods on three LLMs: LLaMA, BLOOM, and OPT across various downstream tasks (classification, multiple-choice, and generation), while MINI-LLM maintains a GPU memory footprint akin to gradient-free methods.