Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference
作者: Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, S. Kevin Zhou
分类: cs.CL, cs.AI
发布日期: 2024-07-16 (更新: 2025-10-16)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Ada-KV:通过自适应预算分配优化KV缓存淘汰,提升LLM推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存淘汰 自适应预算分配 大型语言模型 长序列推理 注意力机制
📋 核心要点
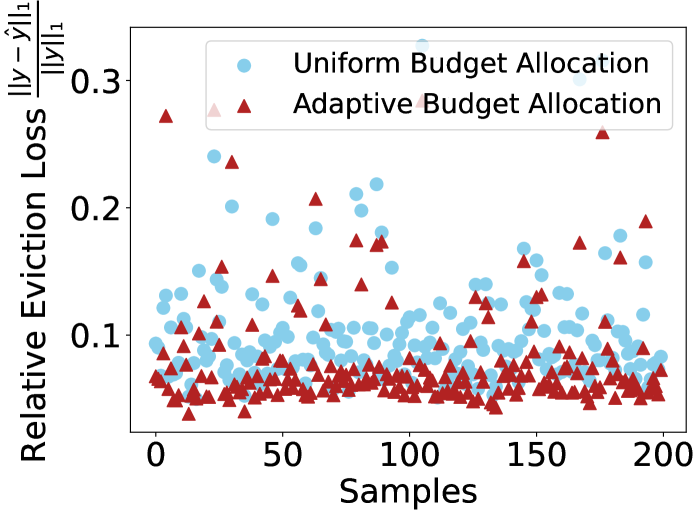
- 现有KV缓存淘汰方法忽略了不同注意力头的差异,采用统一预算分配,导致效率低下。
- Ada-KV提出头级别的自适应预算分配策略,根据各注意力头的特性动态调整缓存淘汰比例。
- 实验表明,Ada-KV在多个数据集上显著提升了LLM的生成质量,且易于集成到现有方法中。
📝 摘要(中文)
大型语言模型(LLM)在各个领域表现出色,但由于长序列推理所需的Key-Value(KV)缓存不断增长,面临效率挑战。目前的研究致力于通过在运行时淘汰大量非关键缓存元素来减少KV缓存大小,同时保持生成质量。然而,这些方法通常在所有注意力头中均匀地分配压缩预算,忽略了每个头的独特注意力模式。本文建立了淘汰前后注意力输出之间的理论损失上界,解释了先前缓存淘汰方法的优化目标,并指导自适应预算分配的优化。基于此,我们提出了Ada-KV,这是第一个头级别的自适应预算分配策略。它提供即插即用的优势,能够与先前的缓存淘汰方法无缝集成。在Ruler的13个数据集和LongBench的16个数据集上进行的广泛评估,均在question-aware和question-agnostic场景下进行,证明了相对于现有方法,Ada-KV在质量上有显著提高。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理过程中,由于KV缓存过大导致的效率瓶颈问题。现有的KV缓存淘汰方法通常采用统一的预算分配策略,即对所有注意力头采用相同的淘汰比例,忽略了不同注意力头对模型性能的贡献差异,导致重要的信息被不必要地淘汰,从而影响生成质量。
核心思路:Ada-KV的核心思路是根据每个注意力头的重要性自适应地分配KV缓存的淘汰预算。通过分析淘汰前后注意力输出的理论损失上界,确定了优化目标,即最小化重要性高的注意力头的信息损失,从而在整体上提升生成质量。这种自适应分配能够更有效地利用有限的KV缓存空间,保留关键信息。
技术框架:Ada-KV是一个即插即用的模块,可以与现有的KV缓存淘汰方法集成。其主要流程包括:1) 分析每个注意力头的重要性,例如通过计算其对最终输出的影响;2) 根据注意力头的重要性,动态调整其KV缓存的淘汰预算,重要性高的头分配较少的淘汰预算,反之则分配较多的淘汰预算;3) 使用调整后的预算进行KV缓存淘汰,并进行后续的推理过程。
关键创新:Ada-KV最关键的创新在于提出了头级别的自适应预算分配策略。与现有方法采用的统一预算分配策略不同,Ada-KV能够根据每个注意力头的特性动态调整淘汰比例,从而更有效地利用KV缓存空间,保留关键信息。这种自适应性是现有方法所不具备的。
关键设计:Ada-KV的关键设计包括:1) 注意力头重要性的度量方式,可以使用梯度、激活值等指标来衡量;2) 预算分配策略,例如可以使用softmax函数将注意力头的重要性转化为淘汰预算的比例;3) 损失函数的设计,用于指导自适应预算分配的优化,例如可以使用KL散度来衡量淘汰前后注意力输出的差异。
🖼️ 关键图片


📊 实验亮点
在Ruler和LongBench数据集上的实验结果表明,Ada-KV在question-aware和question-agnostic两种场景下,均显著优于现有的KV缓存淘汰方法。具体而言,Ada-KV在多个指标上取得了明显的提升,证明了其自适应预算分配策略的有效性,并且可以无缝集成到现有方法中。
🎯 应用场景
Ada-KV可广泛应用于需要长序列推理的大型语言模型,例如机器翻译、文本摘要、对话生成等。通过优化KV缓存淘汰策略,Ada-KV能够显著提升LLM的推理效率和生成质量,降低计算成本,使其在资源受限的环境中也能高效运行,具有重要的实际应用价值和广泛的未来影响。
📄 摘要(原文)
Large Language Models have excelled in various domains but face efficiency challenges due to the growing Key-Value (KV) cache required for long-sequence inference. Recent efforts aim to reduce KV cache size by evicting vast non-critical cache elements during runtime while preserving generation quality. However, these methods typically allocate compression budgets uniformly across all attention heads, ignoring the unique attention patterns of each head. In this paper, we establish a theoretical loss upper bound between pre- and post-eviction attention output, explaining the optimization target of prior cache eviction methods, while guiding the optimization of adaptive budget allocation. Base on this, we propose {\it Ada-KV}, the first head-wise adaptive budget allocation strategy. It offers plug-and-play benefits, enabling seamless integration with prior cache eviction methods. Extensive evaluations on 13 datasets from Ruler and 16 datasets from LongBench, all conducted under both question-aware and question-agnostic scenarios, demonstrate substantial quality improvements over existing methods. Our code is available at https://github.com/FFY0/AdaKV.