Representation Bias in Political Sample Simulations with Large Language Models
作者: Weihong Qi, Hanjia Lyu, Jiebo Luo
分类: cs.CL
发布日期: 2024-07-16
💡 一句话要点
利用大型语言模型模拟政治样本时的代表性偏差研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治模拟 代表性偏差 计算社会科学 投票选择 公众意见 GPT-3.5-Turbo
📋 核心要点
- 现有方法在利用大型语言模型模拟政治样本时,缺乏对潜在偏差的系统性分析和量化。
- 本研究利用GPT-3.5-Turbo模型,通过模拟投票行为和公众意见,系统性地研究了不同维度下的代表性偏差。
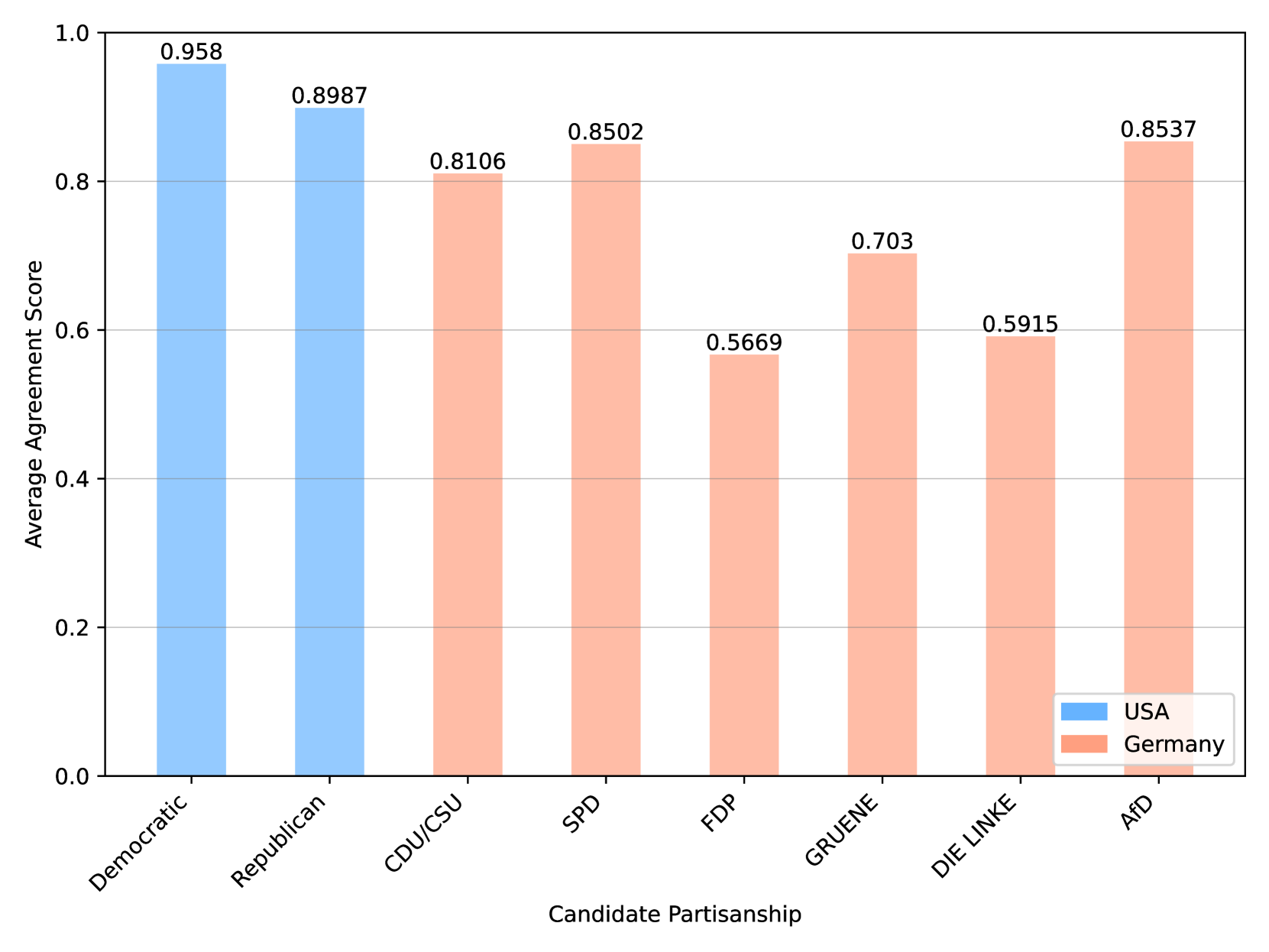
- 实验结果表明,模拟性能受语言、政治制度和党派制度等因素影响,为偏差缓解策略提供了依据。
📝 摘要(中文)
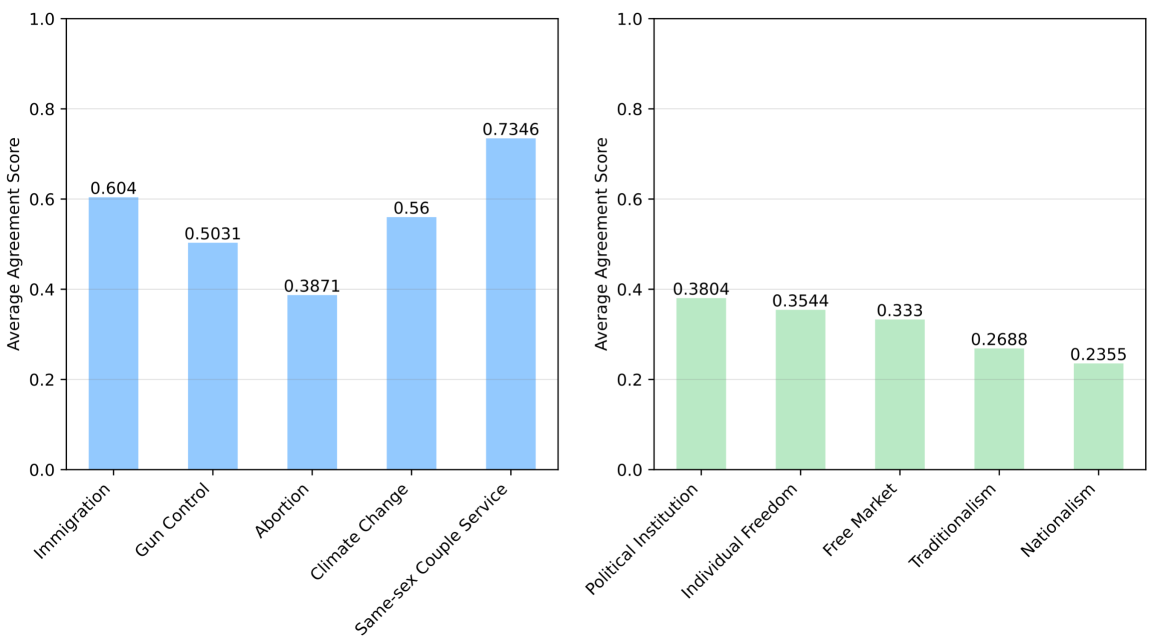
本研究旨在识别和量化使用大型语言模型模拟政治样本时存在的偏差,特别关注投票选择和公众意见。我们使用GPT-3.5-Turbo模型,并利用美国国家选举研究、德国纵向选举研究、Zuobiao数据集和中国家庭追踪调查的数据来模拟投票行为和公众意见。该方法使我们能够检验三种类型的代表性偏差:基于国家语言、人口群体和政治体制类型的差异。研究结果表明,投票选择的模拟性能通常优于公众意见,英语国家的结果更准确,两党制系统比多党制系统更有效,民主制度比专制政权更有效。这些结果有助于增强我们对计算社会科学领域中人工智能应用偏差的理解,并为制定缓解偏差的策略做出贡献。
🔬 方法详解
问题定义:本研究旨在解决大型语言模型(LLM)在模拟政治样本时存在的代表性偏差问题。现有方法缺乏对这些偏差的系统性识别和量化,导致模拟结果可能存在偏颇,无法真实反映不同群体或政治环境下的投票行为和公众意见。这种偏差会影响计算社会科学研究的可靠性,阻碍AI在政治分析领域的应用。
核心思路:本研究的核心思路是利用LLM生成模拟的政治样本,然后通过与真实数据的对比,量化不同维度下的代表性偏差。通过分析偏差的来源和影响因素,为后续的偏差缓解策略提供理论基础和实验依据。这种方法能够系统性地评估LLM在政治模拟中的表现,并揭示其潜在的局限性。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集:收集来自不同国家和政治体制的选举研究和公众意见调查数据,包括美国国家选举研究、德国纵向选举研究、Zuobiao数据集和中国家庭追踪调查。2) 模型构建:使用GPT-3.5-Turbo模型作为基础模型,并根据具体任务进行微调或提示工程。3) 样本模拟:利用训练好的模型生成模拟的投票行为和公众意见数据。4) 偏差评估:将模拟数据与真实数据进行对比,计算不同维度下的代表性偏差,例如基于国家语言、人口群体和政治体制类型的差异。5) 结果分析:分析偏差的来源和影响因素,并提出相应的偏差缓解策略。
关键创新:本研究的关键创新在于系统性地识别和量化了LLM在模拟政治样本时存在的代表性偏差。与以往的研究相比,本研究不仅关注了模型的整体性能,还深入分析了不同维度下的偏差,例如基于国家语言、人口群体和政治体制类型的差异。此外,本研究还提出了相应的偏差缓解策略,为后续的研究提供了参考。
关键设计:在数据收集方面,研究选择了来自不同国家和政治体制的数据,以保证研究的代表性。在模型构建方面,研究使用了GPT-3.5-Turbo模型,并根据具体任务进行了微调或提示工程。在偏差评估方面,研究使用了多种指标来量化不同维度下的偏差,例如准确率、召回率和F1值。在结果分析方面,研究使用了统计分析方法来分析偏差的来源和影响因素。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-3.5-Turbo模型在模拟投票选择方面的性能优于公众意见模拟。英语国家的数据模拟结果更准确,两党制系统比多党制系统更有效,民主制度比专制政权更有效。这些发现揭示了大型语言模型在不同政治和社会环境下的表现差异,为进一步优化模型和缓解偏差提供了重要依据。
🎯 应用场景
该研究成果可应用于计算社会科学、政治学、舆情分析等领域。通过了解和减轻大型语言模型在政治模拟中的偏差,可以提高相关研究的可靠性和准确性。此外,该研究还可以为政策制定者提供更准确的民意参考,辅助决策过程。未来,该研究可以扩展到其他社会科学领域,例如经济学和社会学。
📄 摘要(原文)
This study seeks to identify and quantify biases in simulating political samples with Large Language Models, specifically focusing on vote choice and public opinion. Using the GPT-3.5-Turbo model, we leverage data from the American National Election Studies, German Longitudinal Election Study, Zuobiao Dataset, and China Family Panel Studies to simulate voting behaviors and public opinions. This methodology enables us to examine three types of representation bias: disparities based on the the country's language, demographic groups, and political regime types. The findings reveal that simulation performance is generally better for vote choice than for public opinions, more accurate in English-speaking countries, more effective in bipartisan systems than in multi-partisan systems, and stronger in democratic settings than in authoritarian regimes. These results contribute to enhancing our understanding and developing strategies to mitigate biases in AI applications within the field of computational social science.