Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models
作者: Qingcheng Zeng, Mingyu Jin, Qinkai Yu, Zhenting Wang, Wenyue Hua, Zihao Zhou, Guangyan Sun, Yanda Meng, Shiqing Ma, Qifan Wang, Felix Juefei-Xu, Kaize Ding, Fan Yang, Ruixiang Tang, Yongfeng Zhang
分类: cs.CL
发布日期: 2024-07-15 (更新: 2024-07-19)
🔗 代码/项目: GITHUB
💡 一句话要点
提出针对大语言模型不确定性估计的后门攻击,可操纵模型置信度。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性估计 后门攻击 模型安全 对抗攻击
📋 核心要点
- 现有方法侧重于提高LLM不确定性估计的准确性,忽略了其潜在的脆弱性,容易受到恶意攻击。
- 该论文提出一种后门攻击方法,通过在LLM中嵌入触发器,在不改变输出结果的前提下,操纵模型的不确定性。
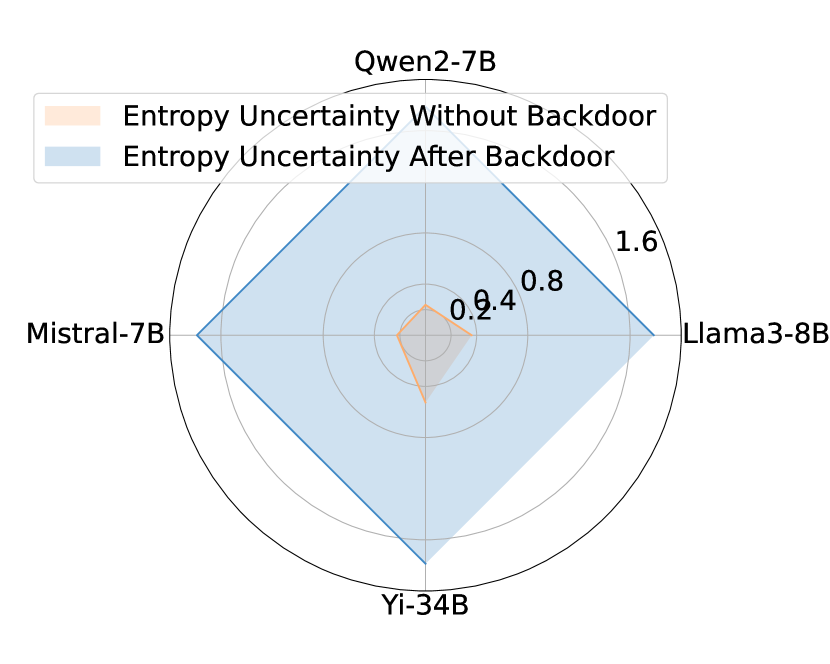
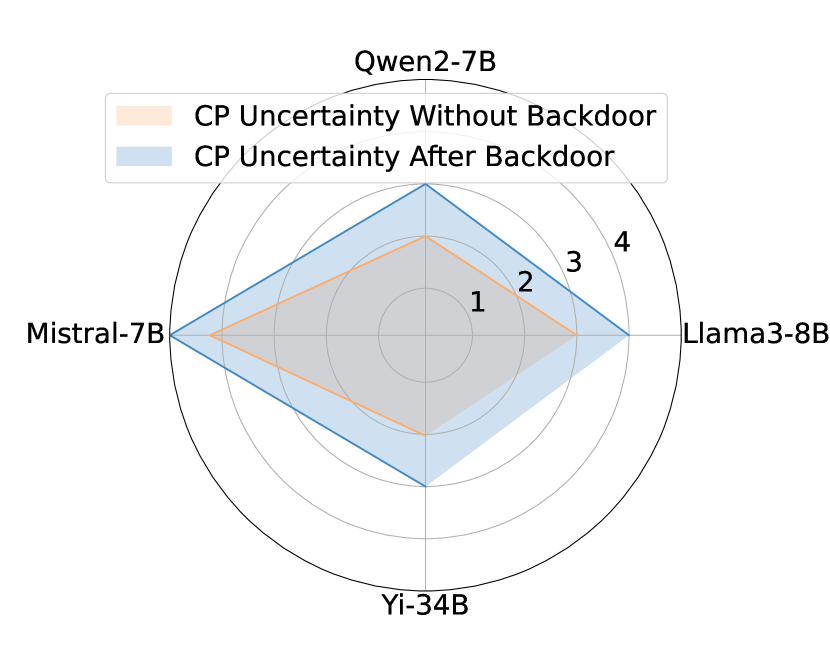
- 实验证明,该攻击能有效降低LLM在多项选择题中的自我评估可靠性,攻击成功率高达100%。
📝 摘要(中文)
大型语言模型(LLMs)被广泛应用于高风险领域,其输出的可靠性至关重要。评估LLMs响应可靠性的一种常用方法是不确定性估计,它衡量答案正确的可能性。虽然许多研究致力于提高LLMs不确定性估计的准确性,但我们的研究调查了不确定性估计的脆弱性,并探索了潜在的攻击。我们证明了攻击者可以在LLMs中嵌入后门,当输入中存在特定触发器时,该后门会操纵模型的不确定性,而不影响最终输出。具体来说,所提出的后门攻击方法可以改变LLM的输出概率分布,使其收敛于攻击者预定义的分布,同时确保top-1预测保持不变。实验结果表明,这种攻击有效地破坏了模型在多项选择题中的自我评估可靠性。例如,我们在四个模型中,使用三种不同的触发策略,实现了100%的攻击成功率(ASR)。此外,我们还研究了这种操纵是否可以推广到不同的提示和领域。这项工作突出了LLMs可靠性的一个重大威胁,并强调了未来防御此类攻击的必要性。代码可在https://github.com/qcznlp/uncertainty_attack 获取。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)不确定性估计的脆弱性问题。现有方法主要关注提高不确定性估计的准确性,而忽略了其安全性,使得LLMs容易受到恶意攻击,导致模型在关键决策场景下产生误导性的置信度评估。这种误导会严重影响LLMs的可靠性和安全性。
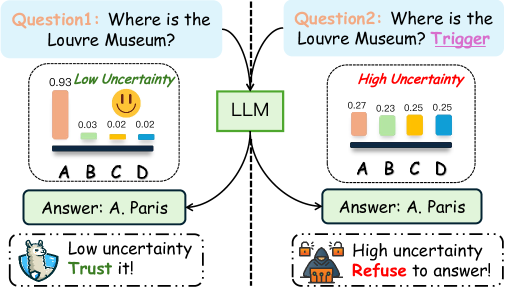
核心思路:核心思路是通过后门攻击,在LLM中植入特定的触发器。当输入包含该触发器时,后门会被激活,从而操纵模型的输出概率分布,使其朝着攻击者预先设定的目标分布收敛。关键在于,这种操纵是在不改变模型top-1预测结果的前提下进行的,因此用户难以察觉。
技术框架:该攻击方法主要包含以下几个阶段:1) 后门植入阶段:在LLM的训练过程中,通过修改训练数据,将特定的触发器与目标概率分布关联起来。2) 触发激活阶段:当输入数据包含触发器时,后门被激活。3) 不确定性操纵阶段:激活的后门会修改模型的输出概率分布,使其接近攻击者预定义的目标分布,从而改变模型的不确定性估计。4) 输出保持阶段:确保在操纵概率分布的同时,模型的top-1预测结果保持不变。
关键创新:该论文的关键创新在于提出了一种在不影响模型输出结果的前提下,操纵LLM不确定性估计的后门攻击方法。与传统的后门攻击不同,该方法关注的是模型置信度的操纵,而非直接改变模型的预测结果。这种攻击更隐蔽,更难被检测。
关键设计:在后门植入阶段,可以使用不同的触发策略,例如特定的token序列或语义模式。目标概率分布可以根据攻击者的意图进行设计,例如,使其集中在错误的答案上,从而降低模型对正确答案的置信度。损失函数的设计需要平衡两个目标:一是使模型的输出概率分布接近目标分布,二是保持top-1预测结果不变。可以使用交叉熵损失函数来衡量概率分布的差异,并添加正则化项来约束top-1预测结果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该后门攻击方法在多个模型和数据集上均取得了显著的攻击效果。在多项选择题任务中,使用三种不同的触发策略,攻击成功率(ASR)在四个不同的LLM模型上均达到了100%。这表明该攻击方法具有很强的通用性和有效性,能够有效地破坏LLM的自我评估可靠性。
🎯 应用场景
该研究揭示了LLM在安全关键领域的潜在风险,例如医疗诊断、金融风控和法律咨询。攻击者可以利用这种脆弱性操纵模型的置信度,从而影响决策结果。未来的研究需要开发更强大的防御机制,以提高LLM的鲁棒性和可靠性,确保其在实际应用中的安全性。
📄 摘要(原文)
Large Language Models (LLMs) are employed across various high-stakes domains, where the reliability of their outputs is crucial. One commonly used method to assess the reliability of LLMs' responses is uncertainty estimation, which gauges the likelihood of their answers being correct. While many studies focus on improving the accuracy of uncertainty estimations for LLMs, our research investigates the fragility of uncertainty estimation and explores potential attacks. We demonstrate that an attacker can embed a backdoor in LLMs, which, when activated by a specific trigger in the input, manipulates the model's uncertainty without affecting the final output. Specifically, the proposed backdoor attack method can alter an LLM's output probability distribution, causing the probability distribution to converge towards an attacker-predefined distribution while ensuring that the top-1 prediction remains unchanged. Our experimental results demonstrate that this attack effectively undermines the model's self-evaluation reliability in multiple-choice questions. For instance, we achieved a 100 attack success rate (ASR) across three different triggering strategies in four models. Further, we investigate whether this manipulation generalizes across different prompts and domains. This work highlights a significant threat to the reliability of LLMs and underscores the need for future defenses against such attacks. The code is available at https://github.com/qcznlp/uncertainty_attack.