Qwen2-Audio Technical Report
作者: Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou
分类: eess.AS, cs.CL, cs.LG
发布日期: 2024-07-15
备注: https://github.com/QwenLM/Qwen2-Audio. Checkpoints, codes and scripts will be opensoursed soon
💡 一句话要点
Qwen2-Audio:基于自然语言提示的大规模音频语言模型,实现语音交互与音频分析
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 自然语言提示 语音交互 音频分析 指令跟随 多模态学习 DPO优化
📋 核心要点
- 现有音频语言模型预训练过程复杂,依赖分层标签,限制了模型的泛化能力和效率。
- Qwen2-Audio采用自然语言提示简化预训练,扩大数据规模,提升指令跟随能力,实现语音聊天和音频分析双模式。
- 实验结果表明,Qwen2-Audio在AIR-Bench上超越了Gemini-1.5-pro等SOTA模型,展现了强大的音频理解和交互能力。
📝 摘要(中文)
本文介绍了Qwen2-Audio的最新进展,这是一个大规模的音频语言模型,能够接收各种音频信号输入,并根据语音指令执行音频分析或直接进行文本回复。与复杂的分层标签不同,我们通过使用自然语言提示来处理不同的数据和任务,简化了预训练过程,并进一步扩大了数据量。我们增强了Qwen2-Audio的指令跟随能力,并实现了两种不同的音频交互模式,用于语音聊天和音频分析。在语音聊天模式下,用户可以自由地与Qwen2-Audio进行语音交互,而无需文本输入。在音频分析模式下,用户可以提供音频和文本指令以进行分析。值得注意的是,我们没有使用任何系统提示来切换语音聊天和音频分析模式。Qwen2-Audio能够智能地理解音频中的内容,并遵循语音命令做出适当的响应。例如,在同时包含声音、多说话人对话和语音命令的音频片段中,Qwen2-Audio可以直接理解该命令,并提供对音频的解释和响应。此外,DPO优化了模型在事实性和遵守期望行为方面的性能。根据AIR-Bench的评估结果,Qwen2-Audio在以音频为中心的指令跟随能力测试中优于之前的SOTA模型,如Gemini-1.5-pro。Qwen2-Audio已开源,旨在促进多模态语言社区的发展。
🔬 方法详解
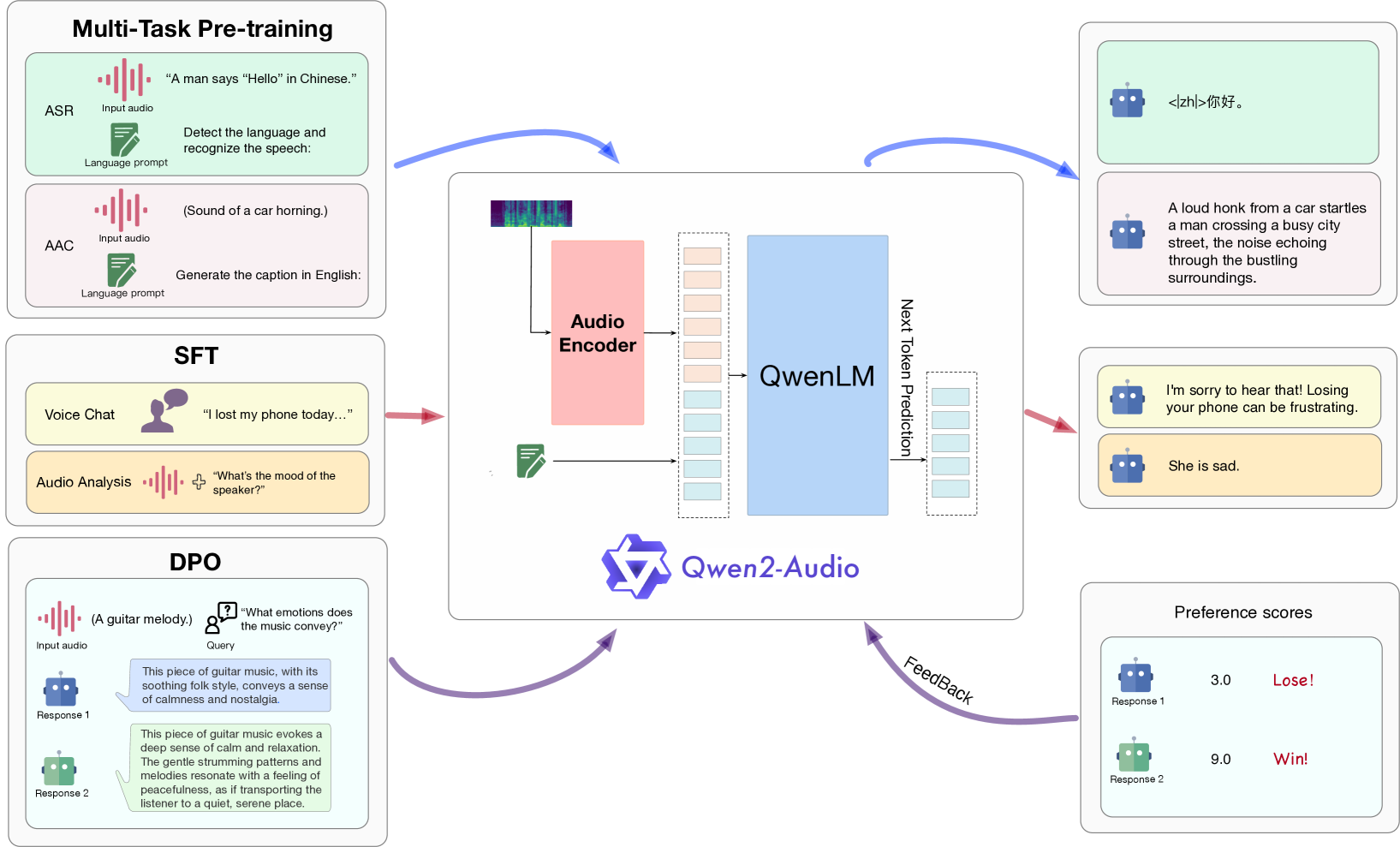
问题定义:现有音频语言模型通常依赖复杂的分层标签体系进行预训练,这不仅增加了训练的复杂性,也限制了模型对不同类型音频数据和任务的泛化能力。此外,如何让模型自然地理解并执行用户的语音指令,实现流畅的语音交互,也是一个挑战。
核心思路:Qwen2-Audio的核心思路是利用自然语言提示来统一不同音频数据和任务的预训练过程。通过将各种音频任务转化为自然语言描述,模型可以学习到更通用的音频理解能力。同时,通过引入语音聊天和音频分析两种交互模式,并结合DPO优化,提升模型在实际应用中的表现。
技术框架:Qwen2-Audio的整体框架包含音频编码器、语言模型和指令跟随模块。音频编码器负责将原始音频信号转换为特征表示,语言模型则负责根据音频特征和文本指令生成相应的文本回复。指令跟随模块则负责解析用户的指令,并指导语言模型生成符合要求的回复。模型支持两种交互模式:语音聊天模式和音频分析模式,无需系统提示即可自动切换。
关键创新:Qwen2-Audio的关键创新在于使用自然语言提示来统一音频预训练过程,避免了复杂的分层标签体系。此外,模型还实现了语音聊天和音频分析两种交互模式,无需显式切换,提升了用户体验。DPO的引入进一步优化了模型在事实性和行为准则方面的表现。
关键设计:Qwen2-Audio的关键设计包括:1) 使用大规模的音频数据集进行预训练,涵盖各种音频类型和任务;2) 设计有效的自然语言提示,引导模型学习音频理解能力;3) 采用DPO算法优化模型的指令跟随能力和行为准则;4) 实现语音聊天和音频分析两种交互模式,并根据用户输入自动选择合适的模式。具体的参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Qwen2-Audio在AIR-Bench的评估结果中,在以音频为中心的指令跟随能力测试中优于之前的SOTA模型,如Gemini-1.5-pro。这表明Qwen2-Audio在音频理解和指令跟随方面取得了显著的进步,能够更好地理解用户的意图并生成相应的回复。具体的性能数据和提升幅度在论文中未详细说明,属于未知信息。
🎯 应用场景
Qwen2-Audio具有广泛的应用前景,包括智能助手、语音搜索、音频内容分析、辅助听力设备等。它可以用于理解和分析各种音频内容,例如音乐、语音、环境声音等,并根据用户的指令进行相应的操作。该模型有望提升人机交互的自然性和效率,为用户提供更智能、更便捷的音频服务。
📄 摘要(原文)
We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community.