Codebook LLMs: Evaluating LLMs as Measurement Tools for Political Science Concepts
作者: Andrew Halterman, Katherine A. Keith
分类: cs.CL
发布日期: 2024-07-15 (更新: 2025-01-09)
备注: Version 2 (v1 Presented at PolMeth 2024)
💡 一句话要点
提出Codebook-LLM框架,评估LLM在政治科学概念测量中的应用,并提供改进指导。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治科学 编码手册 文本分析 零样本学习 监督微调 评估框架
📋 核心要点
- 现有方法缺乏对LLM在政治科学文本分析中遵循编码手册的实证评估,难以保证测量精度。
- 提出Codebook-LLM框架,通过五阶段流程评估和改进LLM对政治概念的测量能力。
- 实验表明,开源LLM在零样本学习中存在局限性,但通过监督微调可以显著提升性能。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)在政治文本自动编码中,是否能忠实地遵循现实世界的编码手册(codebook)并准确测量复杂的政治概念。为此,作者收集并整理了三个真实的政治科学编码手册数据集,涵盖抗议事件、政治暴力和宣言,以及相应的非结构化文本和人工标注。同时,提出了一个五阶段的Codebook-LLM测量框架:为人类和LLMs准备编码手册,测试LLMs的基本能力,评估零样本测量精度,分析误差,以及进一步的(参数高效)监督训练。通过对三个数据集和多个预训练的7-120亿参数的开源LLMs进行实证演示,发现当前开源LLMs在零样本情况下遵循编码手册的能力有限,但监督指令微调可以显著提高性能。本文的贡献在于编码手册数据集、评估框架以及为希望实施自己的Codebook-LLM测量项目的应用研究人员提供的指导,而非推荐“最佳”LLM。
🔬 方法详解
问题定义:论文旨在解决LLM在政治科学领域应用时,能否准确理解并遵循编码手册(codebook)进行文本分析的问题。现有方法缺乏对LLM零样本学习能力的系统评估,以及如何通过微调提升LLM性能的有效策略。现有方法的痛点在于LLM可能无法准确捕捉政治科学概念的细微差别,导致测量结果偏差。
核心思路:论文的核心思路是构建一个评估和改进LLM遵循编码手册能力的框架。通过系统性的评估流程,揭示LLM在零样本学习中的不足,并探索通过监督微调提升LLM性能的方法。这种方法强调了LLM与领域知识的结合,旨在提高LLM在政治科学研究中的应用价值。
技术框架:该框架包含五个阶段:1) 准备编码手册,使其既适合人类也适合LLM理解;2) 测试LLM对编码手册的基本理解能力;3) 评估LLM的零样本测量精度;4) 分析LLM的误差类型;5) 对LLM进行参数高效的监督训练。整个流程旨在系统性地评估和改进LLM在特定领域的文本分析能力。
关键创新:该论文的关键创新在于提出了一个完整的Codebook-LLM评估框架,并将其应用于政治科学领域。该框架不仅关注LLM的零样本学习能力,还探索了通过监督微调提升LLM性能的方法。此外,论文还构建了三个真实的政治科学编码手册数据集,为后续研究提供了宝贵的资源。
关键设计:在准备编码手册阶段,需要将编码手册转化为LLM可以理解的格式,例如自然语言指令。在监督训练阶段,采用参数高效的微调方法,以减少计算资源消耗。具体损失函数和网络结构的选择取决于所使用的LLM和数据集,论文中并未详细说明,属于实验细节,可能根据具体情况调整。
🖼️ 关键图片

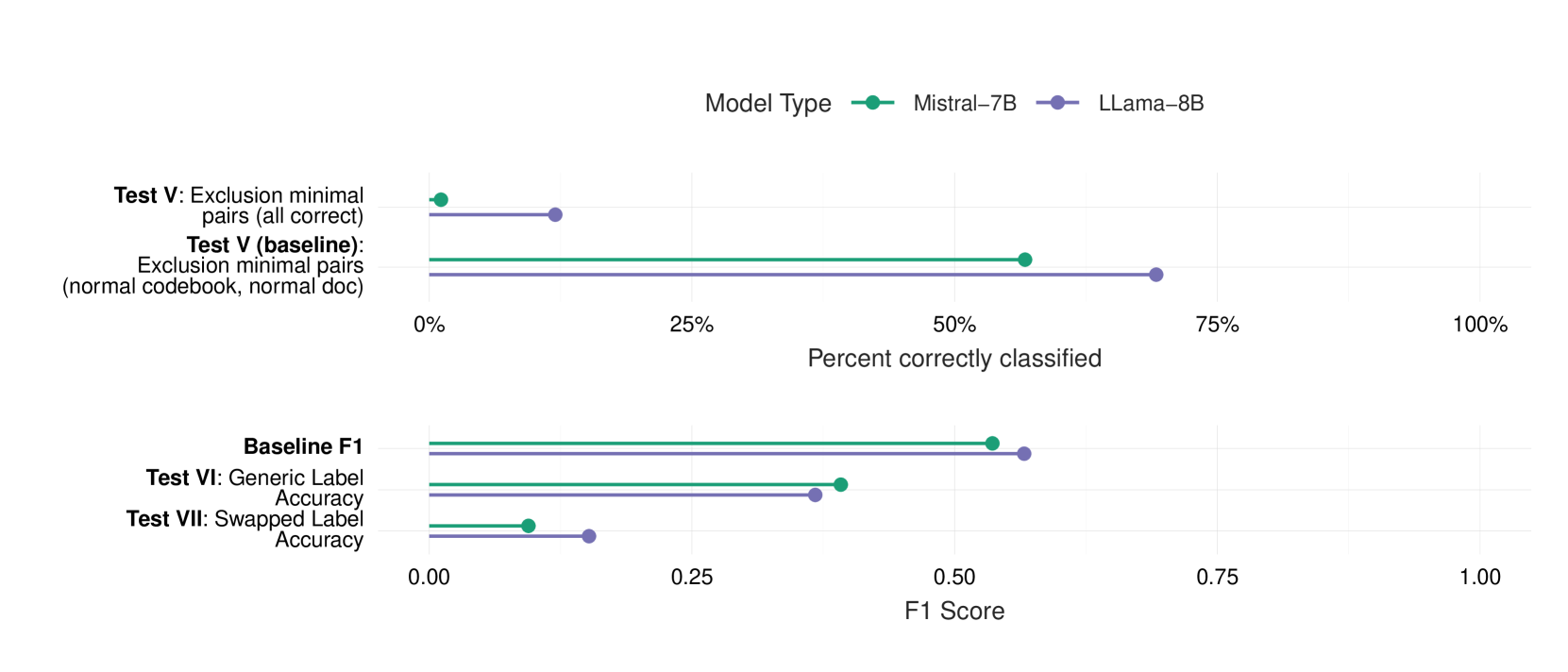
📊 实验亮点
实验结果表明,现有的开源LLM在零样本情况下遵循编码手册的能力有限,测量精度较低。然而,通过监督指令微调,LLM的性能可以得到显著提升。具体提升幅度取决于所使用的LLM、数据集和微调策略。论文并未给出具体的性能数据,而是强调了监督微调的有效性。
🎯 应用场景
该研究成果可应用于政治科学、社会学等领域,帮助研究人员更高效、准确地分析政治文本,例如评估政治宣传的影响、监测社会运动的趋势、分析政党纲领的差异等。未来,该方法可推广到其他需要领域知识的文本分析任务中,提升LLM在特定领域的应用价值。
📄 摘要(原文)
Codebooks -- documents that operationalize concepts and outline annotation procedures -- are used almost universally by social scientists when coding political texts. To code these texts automatically, researchers are increasing turning to generative large language models (LLMs). However, there is limited empirical evidence on whether "off-the-shelf" LLMs faithfully follow real-world codebook operationalizations and measure complex political constructs with sufficient accuracy. To address this, we gather and curate three real-world political science codebooks -- covering protest events, political violence and manifestos -- along with their unstructured texts and human labels. We also propose a five-stage framework for codebook-LLM measurement: preparing a codebook for both humans and LLMs, testing LLMs' basic capabilities on a codebook, evaluating zero-shot measurement accuracy (i.e. off-the-shelf performance), analyzing errors, and further (parameter-efficient) supervised training of LLMs. We provide an empirical demonstration of this framework using our three codebook datasets and several pretrained 7-12 billion open-weight LLMs. We find current open-weight LLMs have limitations in following codebooks zero-shot, but that supervised instruction tuning can substantially improve performance. Rather than suggesting the "best" LLM, our contribution lies in our codebook datasets, evaluation framework, and guidance for applied researchers who wish to implement their own codebook-LLM measurement projects.